在本教程中,你將了解如何執行以下操作:
The following example runs one Python 腳本,該腳本從 Blob Storage container receives CSV 輸入,Execute data processing procedures,and write the output to separate Blob 存儲容器.
如果還沒有 Azure 訂閱,One can be created before starting免費帳戶.
pip 包.通過 https://portal.azure.com 登錄到 Azure 門戶.
就此示例來說,需為 Batch account and storage account to provide credentials. to obtain the required credentials,A straightforward way is to use Azure 門戶. (也可使用 Azure API or command line tools to obtain these credentials.)
選擇“所有服務”>“Batch 帳戶”,然後選擇 Batch 帳戶的名稱.
若要查看 Batch 憑據,請選擇“密鑰”. 將“Batch 帳戶”、“URL”和“Master access key”to copy the value to a text editor.
To see the storage account name and key,請選擇“存儲帳戶”. 將“存儲帳戶名稱”和“Key1”to copy the value to a text editor.
在本部分,你將通過 Batch Explorer 創建 Azure The data factory pipeline to use Batch 池.
custom-activity-pool.Standard_f2s_v2 as the virtual machine size.cmd /c "pip install azure-storage-blob pandas". User ID can be left as default“pool user”.此處將創建 Blob 容器,用於存儲 OCR Input and output files for batch jobs.
input and output container output.input以下 Python 腳本從 input 容器加載 iris.csv 數據集,Execute data processing procedures,and save the result back output 容器.
Python復制
# Load libraries
from azure.storage.blob import BlobClient
import pandas as pd
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Load iris dataset from the task node
df = pd.read_csv("iris.csv")
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data)
Save the script as main.py,並將其上傳到 Azure 存儲 input 容器. uploading it to Blob 容器之前,Be sure to test and verify its functionality locally:
Bash復制
python main.py
在本部分,你將使用 Python The script creates and validates a pipeline.
遵循此文的“創建數據工廠”The steps in section Create a data factory.
在“工廠資源”框中選擇“+”(加號)按鈕,然後選擇“管道”
在“常規”選項卡中,Set the pipe name to “運行 Python”
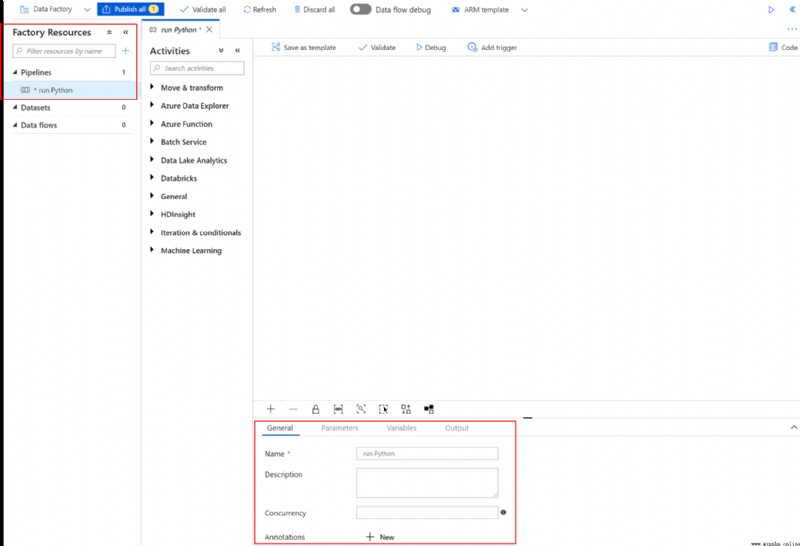
在“活動”box to expand“Batch 服務”. 將“活動”Drag a custom activity from the Toolbox to the Piping Designer surface. Fill out the following tabs for the custom event:
在“常規”選項卡中,指定“testPipeline”作為名稱
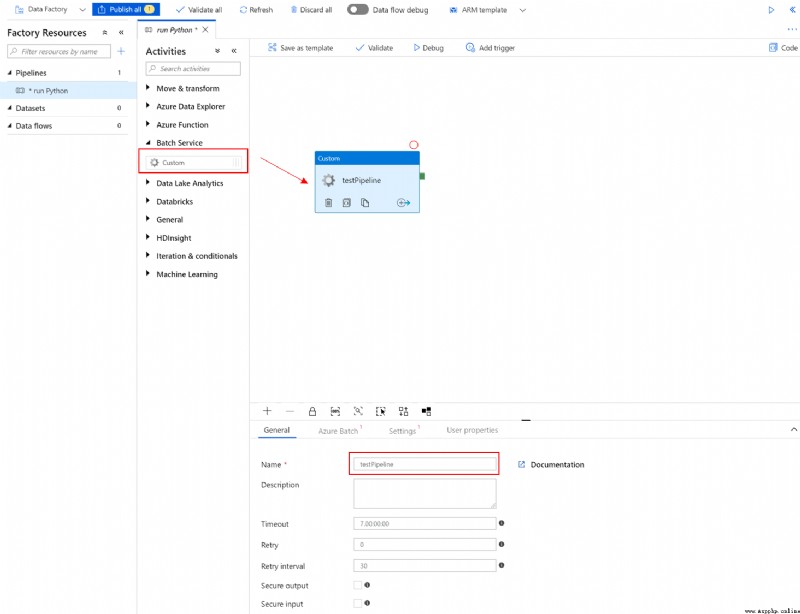
在“Azure Batch”選項卡中,Add the one created in the previous step Batch 帳戶,然後選擇“測試連接”to ensure a successful connection .

在“設置”選項卡中:
python main.py.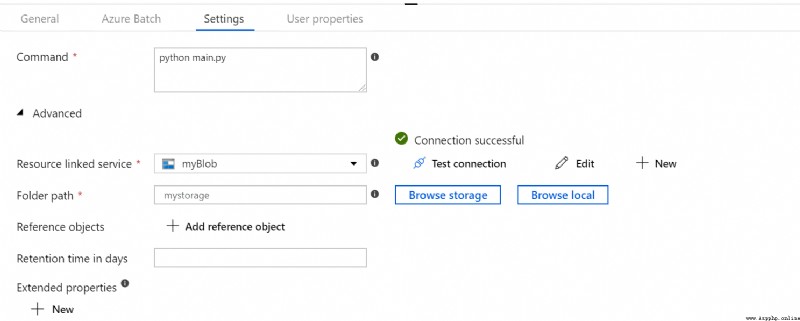
Click in the pipeline toolbar above the canvas“驗證”,in order to verify the pipeline settings. Confirm that the pipeline has been successfully verified. To turn off the validation output,請選擇 >>(右箭頭)按鈕.
單擊“調試”to test the pipeline,Make sure the pipeline is functioning properly.
單擊“發布”to release the pipeline.
單擊“觸發”,to run in a batch process Python 腳本.
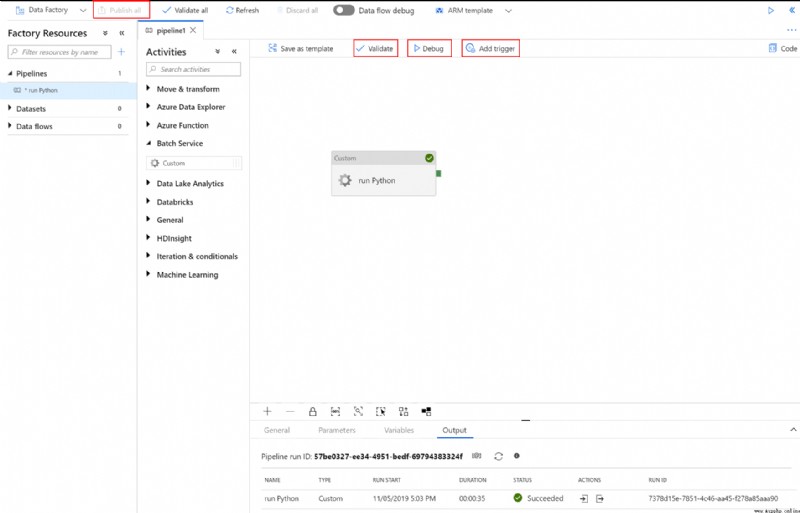
If a warning or error is generated while executing the script,可以查看 stdout.txt 或 stderr.txt Get details about the logged output.
custom-activity-pool,請選擇 adfv2-custom-activity-pool.stdout.txt 和 stderr.txt to investigate and diagnose the problem.Although the assignments and tasks themselves are not charged,But compute node charges. 因此,It is recommended to allocate pools only when needed. All task output on the node is deleted when the pool is deleted. 但是,Input and output files remain in the storage account. 當不再需要時,還可以刪除 Batch account and storage account.
在本教程中,You learned how to do the following:
若要詳細了解 Azure 數據工廠,請參閱:
Azure Data Factory overview
Use a data factory to convert data from Azure Blob Copy one location in storage to another.
了解可與 Azure 數據工廠和 Synapse Analytics 管道(例如 Azure HDInsight)A computing environment used in conjunction to transform or process data.
了解如何對 Azure 數據工廠和 Azure Synapse Analytics Troubleshoot external control activities in the pipeline.
了解如何使用 .NET 創建自定義活動,然後在 Azure Data Factory or Azure Synapse Analytics These activities are used in the pipeline.
顯示更多
本文內容
顯示更多
中文 (簡體)
主題