參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
pandasData frames sometimes we need to merge,Operates on multiple data frames together.pandasThere are many uses in it,了解一下
導入包
import numpy as np
import pandas as pd append和列表的用法一樣,Append directly after the data frame
df.append(self,other,ignore_index=False,#重置索引
verify_integrity=False,sort=False)df1=pd.DataFrame({'x':[1,2],'y':[3,4]})
df2=pd.DataFrame({'x':[5,6],'y':[7,8]})
df3=pd.DataFrame({'z':[1,2],'y':[3,4]})
df1.append(df3,ignore_index=True)
#追加一條數據
df1.append({'x':31,'y':90},ignore_index=True)
concatThere will be more usage,Below are his parameters
pd.concat(obj ,axis=0,join='outer',#inner交集,outer並集
ignore_index=False,keys=None,#連接關系
levels=None,names=None,#索引名稱
sort=False,verify_integrity=False,copy=True)基本用法
#行連接
pd.concat([df1,df2])
pd.concat([df1,df2],axis=0)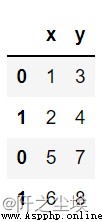
#列連接
df2=pd.DataFrame({'x':[5,6,0],'y':[7,8,80]})
pd.concat([df1,df2],axis=1)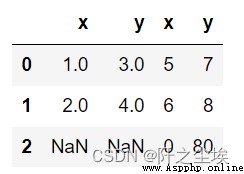
取交集
pd.concat([df1,df2],axis=1,join='inner') #默認並集outer
#指定索引
pd.concat([df1,df2],keys=['a','b'])
pd.concat({'a':df1,'b':df2})
pd.concat([df1,df2],axis=1,keys=['a','b'])### 多文件合並 process_your_file處理文件為df
frames=[process_your_file(f) for f in files ]
result = pd.concat(frames)
#一個包含多個 Sheet 的 Excel 合並成一個 DataFrame
dfm = pd.read_excel('team.xlsx', sheet_name=None)
pd.concat(dfm.values())
pd.concat(dfm) # 保留 Sheet name as a primary indexFile directory merge
#File directory merge
import glob # Remove everything in the directory xlsx 格式文件
files = glob.glob("data/*.xlsx")
cols = ['記錄ID', '開始時間', '名稱'] # Only take these columns
# List comprehension objects
dflist = [pd.read_excel(i, usecols=cols) for i in files]
df = pd.concat(dflist) # 合並map操作
#map操作 # Read multiple files one by one,合並
pd.concat(map(pd.read_csv, ['data/d1.csv','data/d2.csv','data/d3.csv']))
pd.concat(map(pd.read_excel, ['data/d1.xlsx','data/d2.xlsx','data/d3.xlsx']))# 目錄下所有文件
from os import listdir
filepaths = [f for f in listdir("./data") if f.endswith('.csv')]
df = pd.concat(map(pd.read_csv, filepaths))
# 方法 2
import glob
df = pd.concat(map(pd.read_csv, glob.glob('data/*.csv')))
df = pd.concat(map(pd.read_excel, glob.glob('data/*.xlsx')))mergeMore usage,You can merge by keyword,並且可以實現excel表的VLOOKUP函數的功能.
基本參數說明
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)'''how:連接方式,默認為inner,可設為inner/outer/left/right
on:根據某個字段進行連接,必須存在於兩個DateFrame中(若未同時存在,則需要分別使用left_on 和 right_on 來設置)
left_on:左連接,以DataFrame1中用作連接鍵的列
right_on:右連接,以DataFrame2中用作連接鍵的列
left_index:bool, default False,將DataFrame1行索引用作連接鍵
right_index:bool, default False,將DataFrame2行索引用作連接鍵
sort:根據連接鍵對合並後的數據進行排列,默認為True
suffixes:對兩個數據集中出現的重復列,新數據集中加上後綴 _x, _y 進行區別'''
基本用法
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, on='key')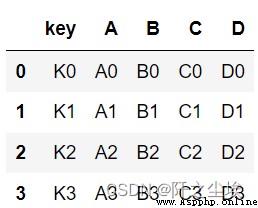
索引連接
#索引連接
pd.merge(left.set_index('key'), right.set_index('key'), left_index=True,right_index=True)
multi-key connection
#multi-key connection
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, on=['key1', 'key2']) 
連接方法——Can be based on a folder's key,You can also take intersection or union
#連接方法
pd.merge(left, right, how='left', on=['key1', 'key2'])# Take the left as the table base table
pd.merge(left, right, how='right', on=['key1', 'key2'])# The table on the right is the base table
pd.merge(left, right, how='outer', on=['key1', 'key2'])# 取兩個表的並集
pd.merge(left, right, how='inner', on=['key1', 'key2'])# 取兩個表的交集
#Below is an example with a repeating join key:
left = pd.DataFrame({'A': [1, 2], 'B': [1, 2]})
right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 3, 4]})
pd.merge(left, right, on='B', how='outer')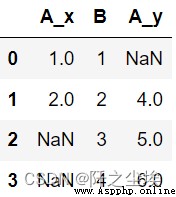
#連接指示 indicator
#連接指示 indicator
#如果設置 indicator 為 True, 則會增加名為 _merge 的一列,Show where this column comes from
pd.merge(left, right, on='B', how='outer', indicator=True)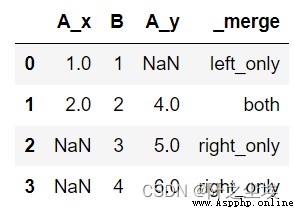
實現excel的vlookup功能,Query and merge the sales prices of different products sold on the sales records,and calculate the total sales
First, the order table and the price table are randomly generated
import random
sale=np.random.randint(2,20,size=(100))
sale_kind=[]
for i in range(100):
sale_kind.append(random.choice(['香蕉','蘋果','橘子','西瓜','葡萄','草莓','芒果','西柚']))
data=pd.DataFrame({'Type of sale':sale_kind,'售賣數量':sale})
data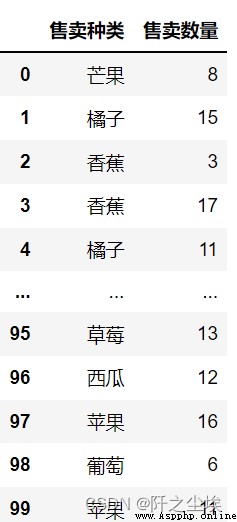
整了8個水果,Randomly generated theirs100條銷售記錄
#Randomly generate price lists
price=pd.DataFrame(['香蕉','蘋果','橘子','西瓜','葡萄','草莓','芒果','西柚'],columns=['水果種類'])
price['水果價格']=abs(np.random.randn((len(price)),1))*10
price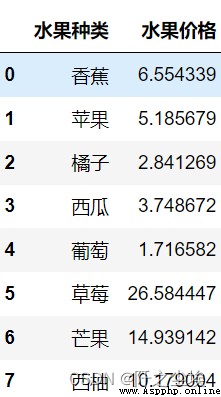
Randomly generated price,,,I don't know how much a pound of fruit is now.
Calculate the sales for each record,On the left is the sales record,So when merging,Based on the data on the left.Add the prices on the right to the data frame one by one.The corresponding price is then multiplied by the quantity sold,Generate a new column of sales.
pd.merge(data, price ,how='left',left_on='Type of sale',right_on='水果種類').assign(銷售額=lambda d:d.售賣數量*d.水果價格)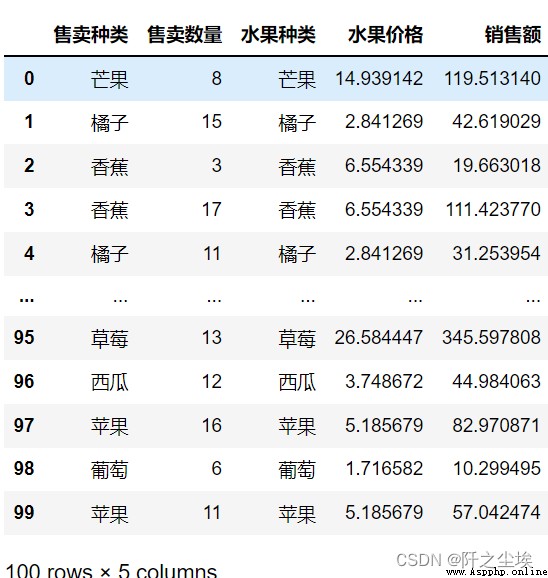
Take the sales column,求和.
#計算銷售額
pd.merge(data, price ,how='left',left_on='Type of sale',right_on='水果種類').assign(銷售額=lambda d:d.售賣數量*d.水果價格)['銷售額'].sum(0)
還是很方便的.merge()Data merging rules are still very complex,To be used according to the specific situation