活動地址:CSDN21天學習挑戰賽
**
**
Regular expressions are used to process strings,Used to check if a string matches some pattern of a defined sequence of characters.
The following are special elements in regular expression pattern syntax.(reIndicates a specific matching pattern written by yourself)
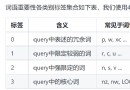
模式描述^匹配字符串的開頭$匹配字符串的結尾.匹配除 "\n" 之外的任何單個字符."[.\n]"可以匹配包括 “\n"在內的任何字符[...]表示一組字符,單獨列出;如[amk]匹配 'a'、'm'或'k'[^...]匹配不在[]中的字符;如[^abc]表示匹配除了a,b,c之外的字符re*匹配0個或多個表達式re+匹配1個或多個表達式re?匹配0個或1個片段,非貪婪方式re{n}匹配n個表達式;如 ”o{2}"可以匹配“food",不能匹配”Bobre{n,}精確匹配n個表達式;如 "o{2}"不能匹配“Bob",可以匹配"fooooood"中的所有"o"re{n,m}匹配n到mFragment of sub-regex definition,貪婪方式'ab'(re)匹配括號內的表達式,也表示一個組(?imx)正則表達式包含三種可選標志:i、m、x,只影響括號中的區域(?-imx)正則表達式關閉i、m或x可選標志,只影響括號中的區域(?:re)類似(...),Does not represent a group(?imx:re)在括號中使用i,m或x可選標志(?-imx:re)在括號中不使用i,m或x可選標志(?#...)注釋(?=re)前向肯定界定符.如果所含正則表達式,以...表示,在當前位置成功匹配時成功,否則失敗.但一旦所含表達式已經嘗試,匹配引擎根本沒有提高;模式的剩余部分還要嘗試界定符的右邊.(?!re)前向否定界定符,與肯定界定符相反;Succeeds when the contained expression cannot be matched at the current position of the string.(?>re)匹配的獨立模式,省去回溯\w匹配包括下劃線的任何單詞字符.等價於'[A-Aa-z0-9_]'\W匹配任何非單詞字符,等價於'[^A-Za-z0-9_]'\s匹配任何空白字符,包括空格、制表符、換頁符等等,等價於 '[\f\n\r\t\v]'\S匹配任何非空白字符,等價於 '[^\f\n\r\t\v]'\d匹配任意數字,等價於'[0-9]'\D匹配一個非數字字符,等價於 '[^0-9]'\A匹配字符串開始\Z匹配字符串結束,如果存在換行,只匹配到換行前的結束字符串\z匹配字符串結束\G匹配最後匹配完成的位置\b匹配一個單詞邊界,Refers to the position between words and spaces.例如, 'er\b' 可以匹配 ‘never’中的'er',但不能匹配 'verb'中的'er'\B匹配非單詞邊界,例如, 'er\b' 不能匹配 ‘never’中的'er',可以匹配 'verb'中的'er'\n、\t等匹配一個換行符,matches a tab, etc\1...\9匹配第n個分組的內容\10匹配第n個分組的內容,if it already matches,is an expression that refers to an octal character code正則表達式可以包含一些可選標志修飾符來控制匹配的模式.修飾符被指定為一個可選的標志.多個標志可以通過按位OR(|)指定.如re.I | re.MIndicates that it is set toI和M標志.
修飾符描述re.I使匹配對大小寫不敏感re.L做本地化識別匹配re.M多行匹配,影響^ $re.S使 . Matches all characters including yellowre.U根據Unicode字符集解析字符.這個標志影響\w,\W,\b,\Bre.XThis flag makes regular expressions easier to understand by giving them a more flexible formatRegular expressions are evaluated from left to right,並遵循優先級順序,Similar to arithmetic arithmetic expressions.
The order of precedence of regular expression operators is as follows:
pythonWhen matching strings with regular expressions,需要導入re模塊,Call the function in the module to perform the matching operation.
首先需要導入re模塊,然後使用re.match()進行匹配操作.最後提取數據.如下:
# 1. 導入python的正則表達式模塊:re
import re
# 2. 使用match()方法進行匹配
result = re.match(正則表達式,要匹配的字符串)
# 3. 如果匹配到數據,使用group()提取數據
result.group() 簡單使用示例:
import re
result = re.match("pyth","python")
print(result.group()) # 輸出 pyth
result = re.match("thon","python")
if result is None:
print("The pattern did not find a matching string") # 輸出 The pattern did not find a matching string
else:
print(result.group())re.match()函數嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回None.
re.match(pattern,string,flags=0)re.search()掃描整個字符串並返回第一個成功的匹配;匹配成功返回一個匹配的對象,否則返回None.
re.search(pattern,string,flags=0)與re.match()相比,re.search()匹配整個字符串,直到找到一個匹配;re.match()只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回None.An example of the difference between the two is as follows:
# re.match() 與 re.search()的區別
s = "Tell me about it!"
ret_match = re.match("about",s,re.I)
ret_search = re.search("about",s,re.I)
if ret_match:
print("re.match()匹配:",ret_match.group())
else:
print("re.match()不匹配")
if ret_search:
print("re.search()匹配:",ret_search.group())
else:
print("re.search()不匹配")re.findall()在字符串中找到正則表達式所匹配的所有子串,並返回一個列表,如果有多個匹配模式,則返回元組列表,如果沒有找到匹配的,則返回空列表.
re.findall()返回的是列表類型,不能使用group()The function gets the matching content.
re.findall(pattern, string, flags=0)與re.match()、re.search()相比,re.findall()匹配所有,The first two functions are matched once.
s = "jack= 23,mark = 24,mary =25"
reg = "\d+"
ret = re.match(reg,s,re.I)
print("re.match()",end=" ")
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
ret = re.search(reg,s,re.I)
print("re.search()",end=" ")
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")
ret = re.findall(reg,s,re.I)
print("re.findall()",end=" ")
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")顯示結果:
re.match() NOT MATCH!!!
re.search() MATCH: 23
re.findall() MATCH: ['23', '24', '25']
如果有多個匹配模式,返回元組列表
s = "jack= 23,mark = 24,mary =25"
reg = r"(\w+)\s?=\s?(\d+)"
ret = re.findall(reg,s,re.I)
if ret:
print(f"MATCH: {ret}") # 匹配,輸出MATCH: [('jack', '23'), ('mark', '24'), ('mary', '25')]
else:
print("NOT MATCH!!!")re.sub()將匹配到的數據進行替換.返回替換後的字符串
re.sub(pattern,repl,string,count=0,flags=0)使用示例:
# re.sub() 使用
s = "0700-123456 # Phone number with area code"
reg = r"#.*$"
ret = re.sub(reg,"",s,count=0,flags=re.I)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")
reg = r'\D' # Remove non-numeric parts
ret = re.sub(reg,"",s,count=0,flags=re.I)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")
def double(matched):
'''
將匹配的數字乘以2
return : Returns the matched number*2
'''
value = int(matched.group("name"))
return str(value*2)
s = "A23D34F56G67"
reg = "(?P<name>\d+)"
ret = re.sub(reg,double,s,count=0)
if ret:
print(f"MATCH: {ret}")
else:
print("NOT MATCH!!!")顯示結果:
MATCH: 0700-123456
MATCH: 0700123456
MATCH: A46D68F112G134
re.split()The function splits the string according to the match,並返回一個列表;如果找不到匹配的字符串,re.split()It will not be divided.
re.split()返回的是一個列表,不能使用group()獲取匹配的內容.
re.split(pattern,string,maxsplit=0,flags=0)s = "info: CSDN python Regular_regpression"
reg = r":| "
ret = re.split(reg,s,maxsplit=0)
if ret:
print(f"MATCH: {ret}")
print(type(ret))
else:
print("NOT MATCH!!!")
reg = "-"
ret = re.split(reg,s,maxsplit=0)
if ret:
print(f"MATCH: {ret}")
print(type(ret))
else:
print("NOT MATCH!!!")顯示結果:
MATCH: ['info', '', 'CSDN', 'python', 'Regular_regpression']
<class 'list'>
MATCH: ['info: CSDN python Regular_regpression']
<class 'list'>
The following patterns can be selected for matching a single character:
示例:
# 匹配單個字符
ret = re.match(".","M") # .匹配
print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("[hH]","hello python") # []匹配
print(ret.group())
ret = re.match("python\d","python3.8") # \d匹配
print(ret.group())
ret = re.match("python\d\.\d","python3.8")
print(ret.group())
ret = re.match("python\D","pythonV3.8") # \D匹配
print(ret.group())
ret = re.match("python\sV","python V3.8") # \s匹配
print(ret.group())
ret = re.match("python\SV","python-V3.8") # \S匹配
print(ret.group())
ret = re.match("python\wV","python_V3.8") # \w匹配
print(ret.group())
ret = re.match("python\WV","python-V3.8") # \W匹配
print(ret.group())
ret = re.search("python\WV","Hi python-V3.8") # \W匹配
print(ret.group())The following modifiers are required to match multiple characters:
示例:
print('='*30)
print("匹配多個字符")
ret = re.match("Y*","YYYY-MM-DD") # *匹配0個或多個
print(ret.group())
ret = re.match("Y+","YYYY-MM-DD") # +匹配1個或多個
print(ret.group())
ret = re.match("Y?","YYYY-MM-DD") # ?匹配1個或0個
print(ret.group())
ret = re.match("M?","YYYY-MM-DD") # ?匹配1個或0個
print(ret.group())
ret = re.match("Y{3}","YYYY-MM-DD") # {m}匹配m個
print(ret.group())
ret = re.match("Y{3,4}","YYYY-MM-DD") # {m}匹配m個
print(ret.group())
ret = re.search("M?","YYYY-MM-DD") # ?匹配1個或0個
print("search()匹配:",ret.group())
ret = re.search("Y?","YYYY-MM-DD") # ?匹配1個或0個
print("search()匹配:",ret.group())
ret = re.search("M+","YYYY-MM-DD") # ?匹配1個或0個
print("search()匹配:",ret.group())
names = ['name','_name','2_name','__name__']
reg = "[a-zA-Z_]+\w*"
for name in names:
ret = re.match(reg,name)
if ret:
print(f"變量名 {name} 符合要求")
else:
print(f"變量名 {name} 不符合要求")
# 匹配數字
reg="[1-9]+\d*$"
vars = [123,32,98,"09","23","asd"]
for var in vars:
ret = re.match(reg,str(var))
print(f"變量 {var} ",end="")
if ret:
print(f"Meet digital requirements,{ret.group()}")
else:
print("Does not meet digital requirements")
# 匹配0~99之間的數字
reg = "[1-9]?\d"
vars = ["09","0","9","90","10"]
for var in vars:
ret = re.match(reg,str(var))
print(f"變量 {var} ",end="")
if ret:
print(f"符合0~99之間 {ret.group()}")
else:
print("符合0~99之間")
# 匹配密碼 Passwords can be uppercase and lowercase letters、數字、下劃線,至少8位,最多20位
reg = "\w{8,20}"
ret = re.match(reg,"_python3_8_0_vscode_1_pycharm")
print("密碼是:",ret.group())匹配開頭、Use the following modifiers at the end:
示例:
# 匹配開頭結尾
print("="*30)
print("匹配開頭結尾")
# Match the China Mobile number segment
phones = [134,135,136,137,138,139,147,150,151,152, 157,158,159,172,178,182,183,184,187,188,198]
numbers= ['12345678901','13412345678','13678349867']
for num in numbers:
for phone in phones:
reg = "^" + str(phone) + "[0-9]{8}"
ret = re.match(reg,num)
if ret:
print(f"{num} It is China Mobile number:{ret.group()}")
break
if ret is None:
print(f"{num} Not a China Mobile number")
# 匹配郵箱
reg = "[\w]{4,20}@163.com$"
email_lst = ["[email protected]","[email protected]","[email protected]"]
for lst in email_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是163郵箱:{ret.group()}")
else:
print(f"{lst} 不是163郵箱")顯示結果:
==============================
匹配開頭結尾
12345678901 Not a China Mobile number
13412345678 It is China Mobile number:13412345678
13678349867 It is China Mobile number:13678349867
[email protected] 是163郵箱:[email protected]
[email protected] 是163郵箱:[email protected]
[email protected] 不是163郵箱
The modifiers for matching groups are as follows:
For functions that return an object,()The matched result can be usedgroup(index)獲取到,可以使用groups(0Get the number of matched tuples;
The content matched by the first parenthesis from left to right in the pattern is group(1),以此類推;
\number匹配的是()中的內容,The content of the first left parenthesis from left to right is\1,The content of the second left parenthesis is \2...;
(?P<name)is to alias the group,(?P=name)引用(?P<name)匹配到的內容.
示例:
# |用法 匹配0~100之間的數字
reg = "[1-9]?\d$|100"
num_lst = ['12','123','09','9','0','100']
for num in num_lst:
ret = re.match(reg,num)
if ret:
print(f"{num} 是0~100之間的數字:{ret.group()}")
else:
print(f"{num} 不是0~100之間的數字")
# ()匹配
# Extract area code and phone number
reg = "([^-]*)-(\d+)"
phones = ['0730-123456','0700-23456','asd-23456']
for phone in phones:
ret = re.match(reg,phone)
if ret:
print(f"{phone}is the correct phone number,區號是{ret.group(1)},電話號是{ret.group(2)}")
else:
print(f"{phone}Not the correct phone number")
# Using the following patterns cannot identify the correct oneHTML標簽
reg = "<[a-zA-Z]*>\w*</[a-zA-Z]*>"
html_lst = ["<html>python</html>","<html>python</htmlpython>"]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML標簽:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML標簽")
# \用法
print("="*30)
print("\\用法")
reg = r"<([a-zA-Z]*)>\w*</\1>"
html_lst = ["<html>python</html>","<html>python</htmlpython>"]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML標簽:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML標簽")
# \number用法
print("="*30)
print("\\number用法")
reg = r"<(\w*)><(\w*)>.*</\2></\1>"
html_lst = ["<html>python</html>",
"<html>python</htmlpython>",
"<html><h1>python</h1></html>",
"<html><h1>python</h2></html>"
]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML標簽:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML標簽")
# (?P<name>)和(?P=name)匹配
print("="*30)
print("(?P<name>)和(?P=name)匹配")
reg = r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>"
html_lst = ["<html>python</html>",
"<html>python</htmlpython>",
"<html><h1>python</h1></html>",
"<html><h1>python</h2></html>",
"<html><h1>csdn.com</h1></html>",
"<html><h1>csdn.com</h2></html>",
"<html><h1>www.itcast.cn</h1></html>"
"<html><h1>www.itcast.cn</h2></html>"
]
for lst in html_lst:
ret = re.match(reg,lst)
if ret:
print(f"{lst} 是正常的HTML標簽:{ret.group()}")
else:
print(f"{lst} 不是正常的HTML標簽")前面介紹過()是分組,()Matching content will be saved;從左到右,Started with a grouped left parenthesis bit flag,第一個出現的分組的組號為1,第二個為2,以此類推.
(?:)Indicates that packets are not captured,Means matching content will not be saved.
對比如下代碼,可以看到(?:pattern)不獲取匹配結果
# (?:pattern) 不捕獲分組
s = "123asd456"
reg = r"(\d*)([a-z]*)(\d*)"
ret = re.search(reg,s)
if ret:
print(f"MATCH: {ret.groups()}")
else:
print("NOT MATCH!!!")
reg = r"(?:\d*)([a-z]*)(\d*)"
ret = re.search(reg,s)
if ret:
print(f"MATCH: {ret.groups()}")
else:
print("NOT MATCH!!!")顯示結果
MATCH: ('123', 'asd', '456')
MATCH: ('asd', '456')
The syntax is positive positive lookahead,匹配pattern前面的位置,這是一個非獲取匹配,That is, the match does not need to be acquired for later use.
# (?=pattern) 模式匹配
s=['windows7','windows10','windows11','windows2000','windows2010']
reg = r"windows(?=95|7|10|11|xp)"
for lst in s:
ret = re.search(reg,lst)
if ret:
print(f"MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")顯示結果:
MATCH: windows
MATCH: windows
MATCH: windows
NOT MATCH!!!
NOT MATCH!!!
※※※ (?:pattern)和(?=pattern)的區別:
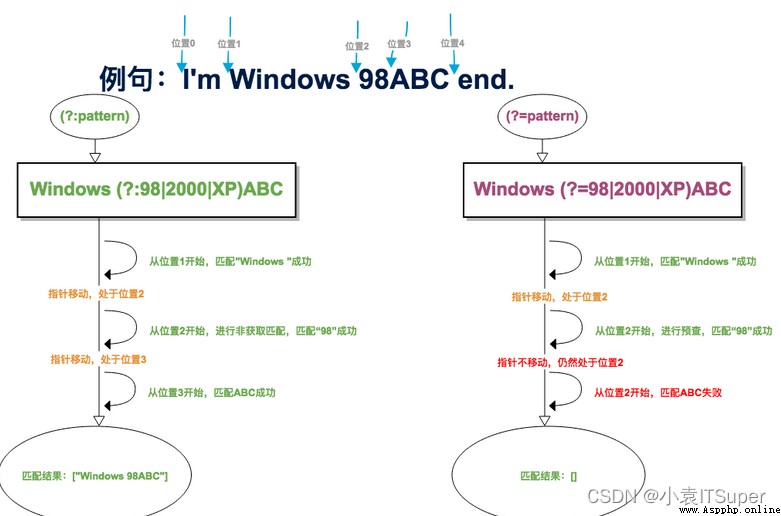
The modified syntax is a forward negative lookahead,在任何不匹配pattern的字符串開始處匹配查找字符串,這是一個非獲取匹配,該匹配不需要獲取供以後使用.
示例:
s=['windows7','windows10','windows11','windows2000','windows2010']
reg = r"windows(?!95|7|10|11|xp)"
print(f"pattern:{reg}")
for lst in s:
ret = re.search(reg,lst)
if ret:
print(f"{lst} MATCH: {ret.group()}")
else:
print("NOT MATCH!!!")顯示結果:
pattern:windows(?!95|7|10|11|xp)
NOT MATCH!!!
NOT MATCH!!!
NOT MATCH!!!
windows2000 MATCH: windows
windows2010 MATCH: windows
從名字就可以看出,Greed means more,That non-greed is the opposite of greed,means less.
When a regular expression is matched in greedy mode,When evaluated in left-to-right order,Will try to get the longest character that satisfies the match.Non-greedy tries to match as few characters as possible.
python中數量詞默認是貪婪的,Will try to match as many characters as possible;在 *,?,+,{m,n}後面加上?Turns greed into non-greedy.
如下示例:
s = "blog.csdn.net"
reg = "\w+"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w+?"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w{2,5}"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")
reg = "\w{2,5}?"
ret = re.match(reg,s)
if ret:
print(f"{reg} MATCH {s}: {ret.group()}")
else:
print("NOT MATCH!!!")顯示結果:
\w+ MATCH blog.csdn.net: blog
\w+? MATCH blog.csdn.net: b
\w{2,5} MATCH blog.csdn.net: blog
\w{2,5}? MATCH blog.csdn.net: bl
python中使用rIndicates that the schema is a raw string,如果不使用r,Some characters need to be escaped to express the desired pattern.
如要匹配 “\\",如果使用r,Then the pattern can be r"\\";如果不使用r,Well the pattern is "\\\\",第一個和第三個\表示轉義字符.
全文參考鏈接:100天精通Python(進階篇)——第34天:正則表達式大總結_無 羨ღ的博客-CSDN博客 https://blog.csdn.net/yuan2019035055/article/details/124217883?app_version=5.7.0&csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22124217883%22%2C%22source%22%3A%22yuan2019035055%22%7D&ctrtid=dmICC&utm_source=app
https://blog.csdn.net/yuan2019035055/article/details/124217883?app_version=5.7.0&csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22124217883%22%2C%22source%22%3A%22yuan2019035055%22%7D&ctrtid=dmICC&utm_source=app