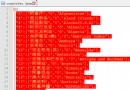
繼之前的任務, 這裡通過用圖表的形式判斷並將各個屬性的離群點捨去.
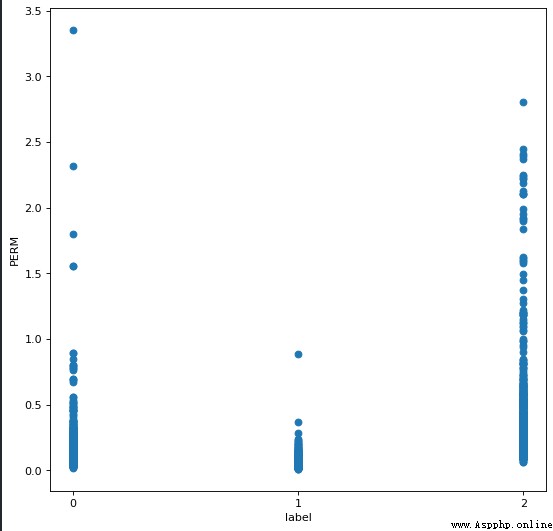
發現 PERM 屬性出現下圖分布
del_index = []
for col in range(len(data_test[2])):
if data_test[2][col] > 2.5:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
對於 PERM 屬性捨去大於 2.5 的樣本
同理對剩余屬性進行處理
del_index = []
for col in range(len(data_test[8])):
if data_test[8][col] > 200:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
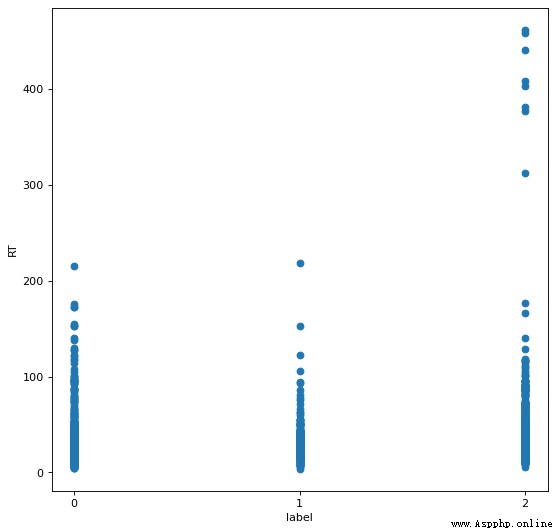
對於 RT 屬性捨去大於 200 的樣本

del_index = []
for col in range(len(data_test[10])):
if data_test[10][col] > 20:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
對於 C2 屬性捨去大於 20 的樣本
以此類推對所有屬性進行處理. 但是我在這裡有個想法, 為什麼不對每類的屬性進行處理呢?看起來有點故意為之的感覺, 實在不行再考慮這樣處理吧.
在使用一般的分類算法之前, 這裡了解到還可以通過隨機森林算法進行分類.
from sklearn.ensemble import RandomForestClassifier
sklearn_rf_clf = RandomForestClassifier()
sklearn_rf_clf.fit(feature_train_set,label_train_set)
sklearn_rf_clf.score(feature_test_set,label_test_set)
運行截圖

隨機森林進行交叉驗證
from sklearn.model_selection import cross_val_score
score = cross_val_score(sklearn_rf_clf,feature_train_set, label_train_set, cv=3,n_jobs=1)
print("CV accuacy score:%s" % score)
print("CV accuacy mean score:%.3f" % np.mean(score))
運行截圖

這裡可以看見識別率比之前使用過的算法有所提升.
但是數據處理之後對識別率提升沒有很明顯變化, 以 100 次 KNN 平均識別率為例.
from sklearn.neighbors import KNeighborsClassifier
sklearn_knn_clf = KNeighborsClassifier(n_neighbors=7)
sklearn_knn_clf.fit(feature_train_set,label_train_set)
score = 0
for i in range(100):
score += sklearn_knn_clf.score(feature_test_set,label_test_set)
print(score/100)
數據處理前進行 100 次 KNN 的平均識別率

數據處理後進行 100 次 KNN 的平均識別率

很奇怪的是, 處理數據後識別率反而下降了. 看來相比起處理數據, 算法才是主導. 或許也只是自己的數據處理有問題.
看一下樣本不同分類的個數, 觀察是不是出現了分布不均.
import numpy as np
for i in range(3):
print('label = ',i)
print(np.sum(label==i))
運行截圖

看樣子沒有分布不均. 但是相比那些數據集, 這個數據集的大小就小得多了. 是否可以考慮對訓練集和測試集的劃分進行修改?這點不用擔心, 庫中的函數考慮到了這個問題, 它是分別對每類用固定比例進行劃分.
只剩下神經網絡沒有使用, 或者還有其他的算法. 還是更想對數據分析更透徹一些. 為了結果而做一些工作雖然看起來很不錯, 但自己總感覺是 “為賦新詞強說愁”.
看一些博客了解到相關性這個東西, 說不定會對分類有所效果.