# Python 正則表達式(二)使用 re模塊
活動地址:CSDN21天學習挑戰賽
本篇在Python正則表達式(一)的基礎上,繼續講解PythonRelated content of regular expressions.
在Python語言中,使用 reThe module provides built-in standard library functions to process regular expressions.在這個模塊中,Both basic functions that can directly match regular expressions,It is also possible to compile a regular expression object,and use its methods to use regular expressions.在本節的內容中,將詳細講解使用reBasic knowledge of modules.
在下表中,列出了 Python語言內置模塊reCommonly used built-in functions and methods,它們中的大多數函數也與已經編譯的正則表達式對象((regex obiect)和正則匹配對象(regex matchobject) The Wanfa has the same name and has the same functionality.
在 Python程序中,函數compile()The function is to compile regular expressions.使用函數compile()的語法如下所示.
compile(source, filename, mode [, flags [,dont_ inherit] ])
By using the above format,能夠將source編譯為代碼或者AST 對象.代碼對象能夠通過 exec語句來執行或者eval()進行求值.各個參數的具體說明如下所示.
●參數 source: 字符串或者AST(Abstract Syntax Trees)對象;
●參數 filename: 代碼文件名稱,如果不是從文件讀取代碼則傳遞一些可辨認的值;
●參數 mode:指定編譯代碼的種類,可以指定為exce、eval 和 single;
●參數 flags 和 dont_inherit: 可選參數,極少使用.
例如在下面的實例中,演示了使用函數 cmpile() 將正則表達式的字符串形式編譯為Patterm實例的過程:
import re
pattern = re.compile('[a-zA-Z]')
result = pattern.findall('as3SioPdj#@23awe')
print (result)
在上述代碼中,先使用函數re.compile將正則表達式的字符串形式編譯為Pattern實例,然後使用Pattern實例處理文本並獲得匹配結果(一個Match實例),最後使用Match實例獲得信息,進行其他的操作.執行後輸出:
在Python程序中,函數match()The function of is to match a regular expression in a string,如果匹配成功則返回MatchObject對象實例.使用函數match()的語法格式如下所示.
re.match(pattern, string, flags=0)
●參數 pattern: 匹配的正則表達式;
●參數 string: 要匹配的字符串;
●參數 lags: 標志位,用於控制正則表達式的匹配方式,例如是否區分大小寫、多行匹配等.
參數lagsThe option value information for is shown in the following table:
匹配成功後,函數match() will return a matching object,否則返回None.我們可以使用函數group(num)或函數groups()to get the matching expression.
例如下面在PythonThe use is demonstrated in the interactive command line program of match()以及group()的過程:
>>> import re
>>> m = re.match('foo', 'foo') #模式匹配字符串
>>> if m is not None: #如果匹配成功,output matching content
... m.group()
...
'foo'
For example below is an example of a failed match,會返回None.
>>> import re
>>> m = re.match('papa', ' foo') #模式匹配字符串
>>> if m is not None: #如果匹配成功,output matching content
... m.group()
...
因為匹配失敗,所以m被賦值為None.
在Python程序中,函數search()The function is to scan the entire string and return the first successful match. 事實上,The pattern to search appears in a string The probability of the middle part,遠大於出現在字符串起始部分的概率.This is also the functionsearch()派上用場的時候.函數search()how it works and functionsmatch()完全一致, 不同之處在於函數search()會用它的字符串參數,在任意位置對給定正則表達式模式搜索第一次出現的匹配情況.如果搜索到成功的匹配,就會返回一個匹配對象.否則,返回None.
An example will be given nextmatch()和search()之間的差別.Take matching a longer string as an example,Strings are used below“foo”去匹配“seafood”:
>>> import re
>>> m = re.match('foo', 'seafood')#匹配失敗
>>> if m is not None: m.group()
...
由此可以看到.此處匹配失敗.match()試圖從字符串的起始部分開始匹配模式.也就是說,模式中的“f"將匹配到字符串的首字母“s”上.這樣的匹配肯定是失敗的.然而,字符串“foo"確實出現在"seafood”之中(某個位置),所以,我們該如何讓python得出肯定的結果呢?答案是使用searh()函數,而不是嘗試匹配.search() Not only does the function search for the first occurrence of the pattern in a character,And strictly search from left to right for the learning symbols.
>>> import re
>>> m = re.search('foo', 'seafood')#匹配失敗
>>> if m is not None: m.group()
...
'foo' #搜索成功,但是匹配失敗
>>>
在Python程序中,函數findall()The function of is to find all strings matching the regular expression in the string,並返回這些字符串的列表.If groups are used in regular expressions,則返回一個元組. 函數re.match()函數和函數re.search()的作用基本一樣, 不同的是,函數re.match()Matches only from the first character in the string.而函數re.scarch()then the entire string is searched.
使用函數findall()的語法格式如下所示.
re.findall (pattern, string, flags=0)
請看下面的實例,功能是使用函數fndall()匹配字符串.
import re #導入模塊 re
#Defines a string variable to operate ons
s = "adfad asdfasdf asdfas asdfawef asd adsfas"
#將正則表達式的字符串形式編譯為Pattern實例
reObjl = re.compile('((\w+)\s+\w+)')
print (reObjl.findall(s)) #第1次調用函數findall()
#將正則表達式的字符串形式編譯為Pattern實例
reObj2 = re.compile('(\w+)\s+\w+')
print (reObj2.findall(s)) #第2次調用函數findall()
#將正則表達式的字符串形式編譯為Pattern實例
reObj3 = re.compile('\w+\s+\w+')
print (reObj3.findall(s)) #第3calls the functionfindal
因為函數 findall()What is returned is always a list of all matches of the regular expression in the string,So here is the main discussion list“結果”的展現方式,即fndallReturns the information contained in each element in the list.執行後會輸出:
在Python程序中,有兩個函數/方法用於實現搜索和替換功能,這兩個函數是sub()和subn(). Both are almost the same,are all a string Do some form of replacement for all parts of the regex that match.用來替換的部分通常是一個字符串, 但它也可能是一個函數,該函數返回一個用來替換的字符串.函數subn()和函數sub()的用法類似,但是函數subn()You can also return a total representing the replacement,The replaced string is taken together with a number representing the total number of replacements-個擁有 A tuple of two elements is returned.
在Python程序中,使用函數sub()和函數subn()的語法格式如下所示.
re.sub( pattern, repl, string[, count])
re.subn( pattern, repl, string[, count] )
The specific description of each of the above parameters is as follows.
●pattern: 正則表達式模式;
●repl: 要替換成的內容;
● string: A string for content substitution;
●count: 可選參數,最大替換次數.
例如在下面的實例中,演示了使用函數sub()The process of implementing a replacement function:
import re #導入模塊re
print(re.sub('[abc]', 'o','Mark')) #找出字母a、b或者C
print(re.sub('[abc]', 'o','rock')) #將"rock"變成"rook”
print(re.sub('[abc]', 'o','caps')) #將caps變成oops
在上述實例代碼中,首先在“Mark"Find the letters ina、b或者c,並以字母“o”替換,Mark就變成Mork了.然後將“rock”變成“rook”.Focus on the last line of code,Some readers may think that it can becaps 變成oaps,但事實並非如此.函數re.sub()Can replace all matches,and not just the first match.So the regex will put caps變成ops,因為c和a都被轉換為o.執行後會輸出: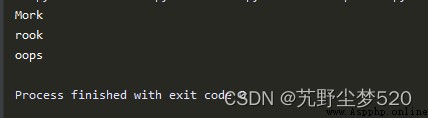
在Python程序中,模塊reand object functions in regular expressionssplit() 對於相對應字符串的工作方式是類似的,但是與分割一個固定字符串相比,它們基於正則表達式的模式分隔字符串,Add some extra functionality to the string delimiter feature.If you don't want to split the string for every occurrence of the pattern,It can be passed as a parametermax設定一個值(非零)way to specify the maximum number of divisions.If the given delimiter is not a regular expression using special symbols to match multiple patterns,那麼函數re.split()與函數str.split() 的工作方式相同,For example, the following demonstration process is split based on single quotes.
>>> re.split(':', 'strl:str2:str3')
['strl', 'str2', 'str3']
請看下面的實例,功能是使用函數split()分割一個字符串.
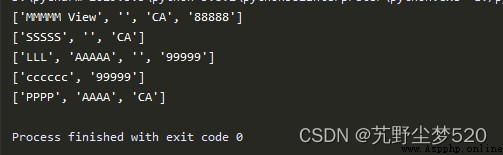
import re
DATA = (
'MMMMM View, CA 88888',
'SSSSS, CA' ,
'LLL AAAAA, 99999',
'cccccc 99999',
'PPPP AAAA CA',
)
for datum in DATA:
print(re.split(',|(?= (?:\d{5}|[A-Z]{2})) ',datum))
The above regular expression has a simple component, 使用piThe statement splits the string based on the backspace.The more important part is the regex at the end,The expansion symbol can be previewed through this regular expression.in normal English strings,如果空格緊跟在五個數字(ZIP編碼)Adult two capital letters(美國聯邦州縮寫)之後,就用spit() function to separate the space.執行後會輸出: