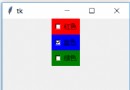
following previous tasks, Here, it is judged in the form of a chart and the outliers of each attribute are discarded.
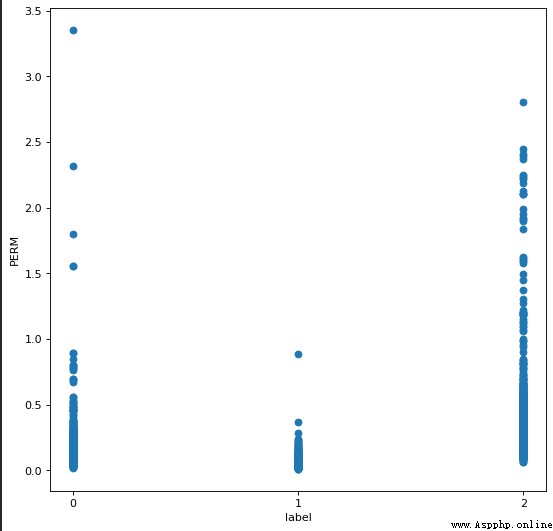
發現 PERM The properties appear in the following figure distribution
del_index = []
for col in range(len(data_test[2])):
if data_test[2][col] > 2.5:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
對於 PERM Attributes round off greater than 2.5 的樣本
The remaining attributes are processed in the same way

del_index = []
for col in range(len(data_test[8])):
if data_test[8][col] > 200:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
對於 RT Attributes round off greater than 200 的樣本
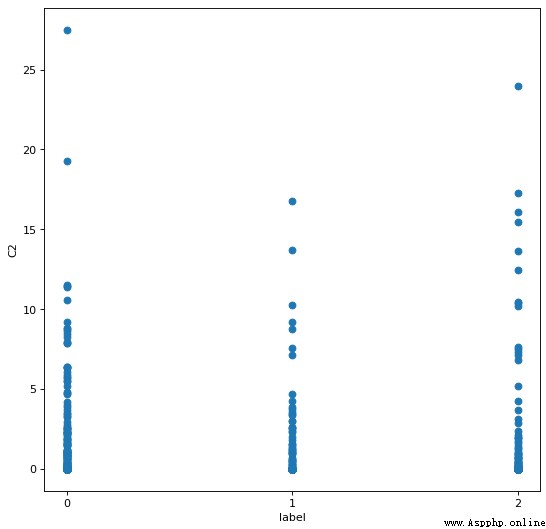
del_index = []
for col in range(len(data_test[10])):
if data_test[10][col] > 20:
del_index.append(col)
data_test = np.delete(data_test, del_index, axis = 1)
label = np.delete(label, del_index)
對於 C2 Attributes round off greater than 20 的樣本
And so on for all properties. But I have an idea here, Why not process the properties of each class?It seems a bit intentional, I really can't think about it anymore.
before using general classification algorithms, It is learned here that classification can also be performed by the random forest algorithm.
from sklearn.ensemble import RandomForestClassifier
sklearn_rf_clf = RandomForestClassifier()
sklearn_rf_clf.fit(feature_train_set,label_train_set)
sklearn_rf_clf.score(feature_test_set,label_test_set)
運行截圖
Random forest for cross-validation
from sklearn.model_selection import cross_val_score
score = cross_val_score(sklearn_rf_clf,feature_train_set, label_train_set, cv=3,n_jobs=1)
print("CV accuacy score:%s" % score)
print("CV accuacy mean score:%.3f" % np.mean(score))
運行截圖

Here you can see that the recognition rate has improved compared to the algorithm used before.
However, there is no obvious change in the recognition rate improvement after data processing, 以 100 次 KNN The average recognition rate is an example.
from sklearn.neighbors import KNeighborsClassifier
sklearn_knn_clf = KNeighborsClassifier(n_neighbors=7)
sklearn_knn_clf.fit(feature_train_set,label_train_set)
score = 0
for i in range(100):
score += sklearn_knn_clf.score(feature_test_set,label_test_set)
print(score/100)
before data processing 100 次 KNN 的平均識別率

after data processing 100 次 KNN 的平均識別率

很奇怪的是, After processing the data, the recognition rate dropped. It seems compared to processing data, Algorithms are in charge. Maybe it's just a problem with your own data processing.
Look at the number of different categories of the sample, Observe whether there is an uneven distribution.
import numpy as np
for i in range(3):
print('label = ',i)
print(np.sum(label==i))
運行截圖

It does not appear to be unevenly distributed. But compared to those datasets, The size of this dataset is much smaller. Is it possible to consider a modification to the division of the training set and test set?這點不用擔心, The functions in the library take this into account, It divides each class with a fixed proportion.
Only the neural network is left unused, Or there are other algorithms. Still want to be more thorough in data analysis. Doing some work for the result though looks pretty good, But I always feel it is “為賦新詞強說愁”.
Read some blogs to learn about relevance, Maybe it will have an effect on the classification.