活動地址:CSDN21天學習挑戰賽
以下是關於lxml&&BeautifulSoup庫的使用
🥧 點擊跳轉到上一篇續文
🥧快,跟我一起爬起來
爬蟲越爬越爽
簡單理解:(簡單爬蟲是爬取整個頁面的內容)解析就是通過某種方法去得到我們想要的數據而不是全部都要。

Xpath Helper插件的作用:可以讓我們高效解析網頁內容
Xpath Helper插件安裝包鏈接:點擊跳轉至GitHub
安裝插件步驟:
(1)打開chrome浏覽器
(2)點擊右上角小圓點
(3)更多工具
(4)擴展程序
(5)拖拽xpath插件到擴展程序中
(6)關閉浏覽器重新打開
(7)ctrl + shift + x
(8)出現小黑框
如下圖(安裝成功):


W3c中文官方:點擊跳轉
官方:點擊跳轉
使用步驟:
xpath常用表達式(太多就不一一列出用到的時候可以去中文官方查看就可以了):
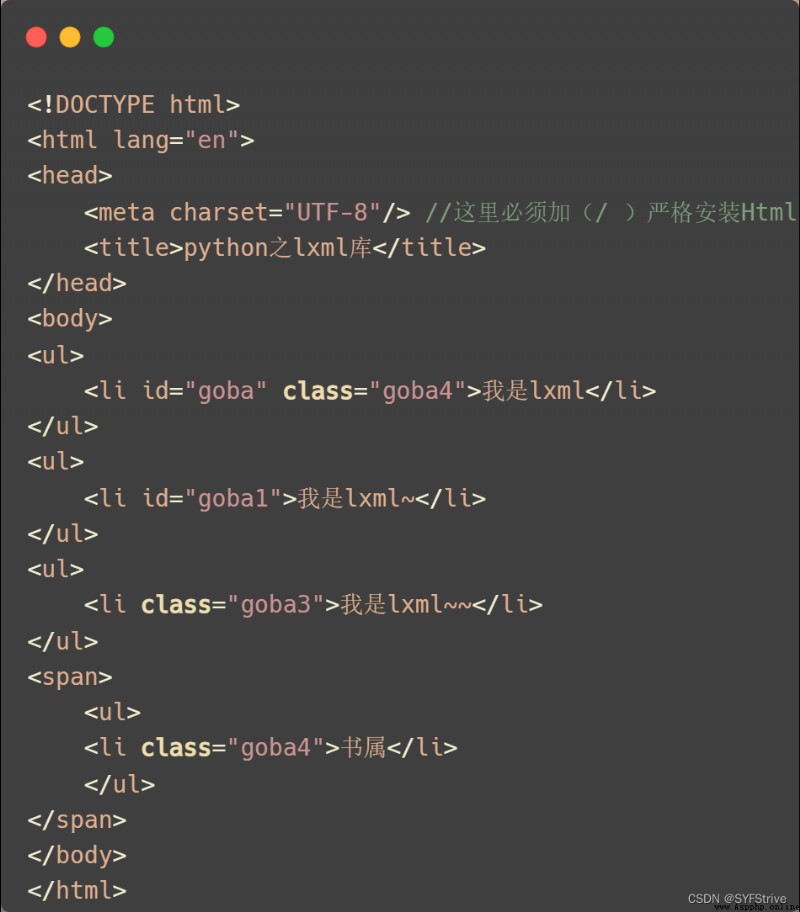
模擬被解析的數據如下:
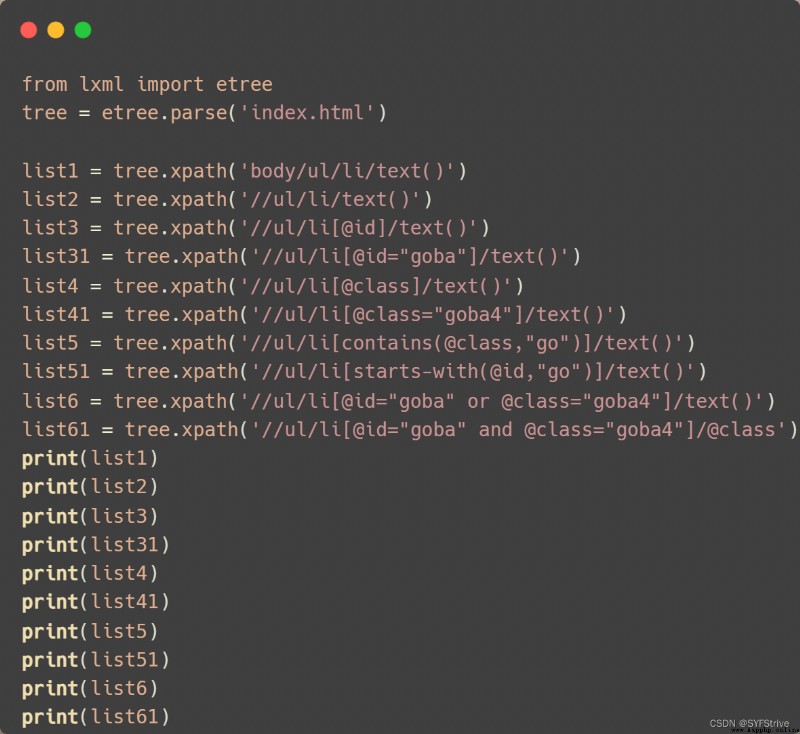
代碼演示
結果如下圖所示:
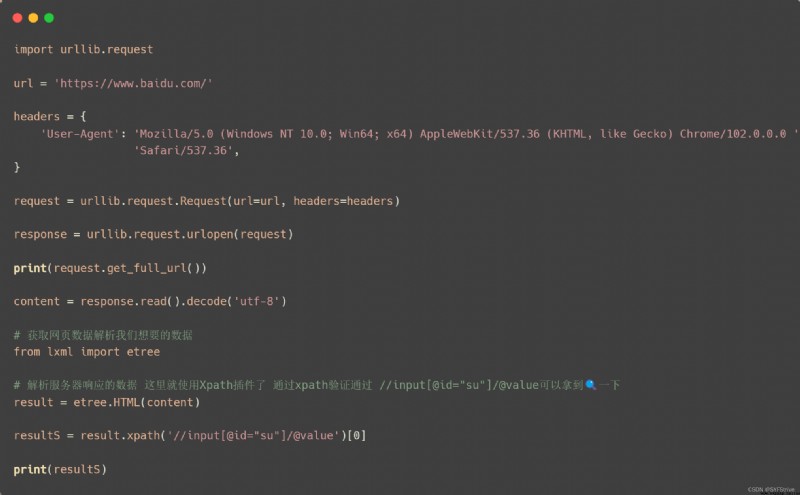
通過xpath獲取想要的數據如://input[@id=“su”]/@value(獲取一下的文字)

代碼演示
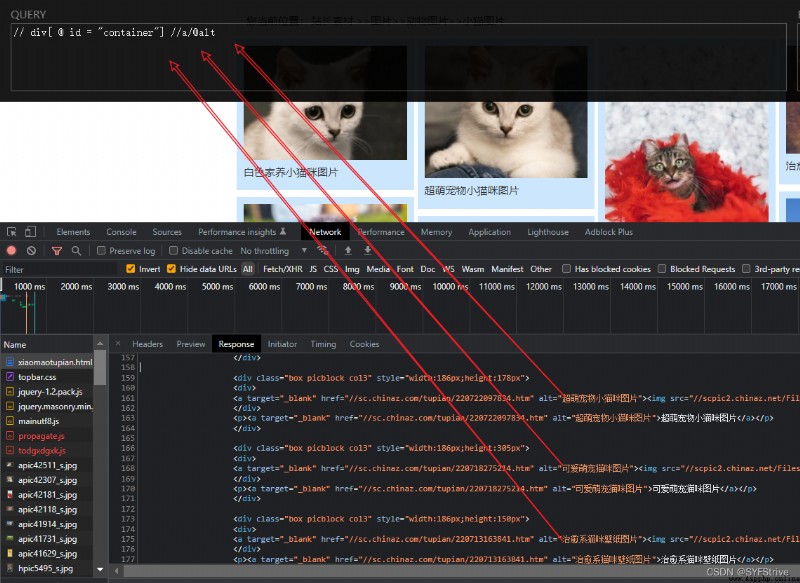
如下圖所屬(獲取數據成功):

步驟如圖:
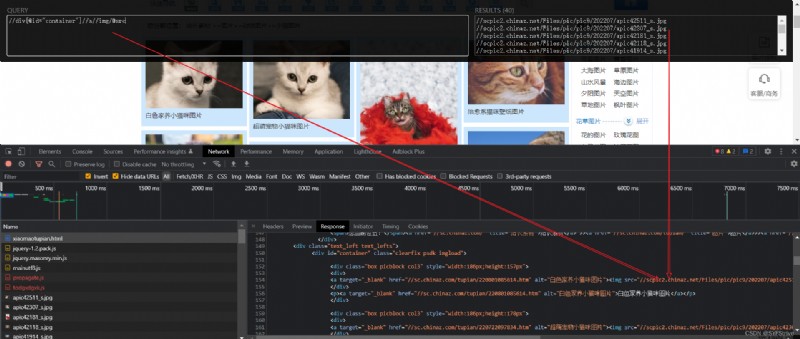
代碼演示

如下圖(爬取成功):

分享幾張爬到的圖片:








官方:點擊跳轉
使用步驟:
注意:默認打開文件的編碼格式gbk所以需要指定打開編碼格式
ba4常見表達式:
result= BeautifulSoup(open(‘1.html’), decode(),‘lxml’)
節點定位
1. 根據標簽名查找節點
result.a【注】 只能找到第一個a
result.a.name //
result.a.attrs //獲取標簽的屬性和屬性值
2. 函數
(1).find(返回一個對象)
find(‘a’):只找到第一個a標簽
find(‘a’, title = ‘名字’)
find(‘a’, class_ = ‘名字’)
(2).find_all(返回一個列表)
find_all(‘a’) 查找到所有的a
find_all([‘a’, ‘span’]) 返回所有的a和span
find_all(‘a’, limit = 2) 只找前兩個a(3).select(根據選擇器得到節點對象)【推薦】
1. element
eg: p
2…class
eg: .firstname
3.# id
eg: #firstname
4. 屬性選擇器
[attribute]
eg: li = result.select(‘li[class]’)[attribute = value]
eg: li = result.select(‘li[class=“hengheng1”]’)
5. 層級選擇器
5.1、element element
div p
5.2、element > element
div > p
5.3、element, element
div, p
eg: result = result.select(‘a,span’)節點信息
(1).獲取節點內容: 適用於標簽中嵌套標簽的結構
obj.string
obj.get_text()【推薦】
(2).節點的屬性
tag.name 獲取標簽名
eg: tag = find('li)
print(tag.name)
tag.attrs將屬性值作為一個字典返回
(3).獲取節點屬性
obj.attrs.get(‘title’)【常用】
obj.get(‘title’)
obj[‘title’]
模擬被解析的數據如下:
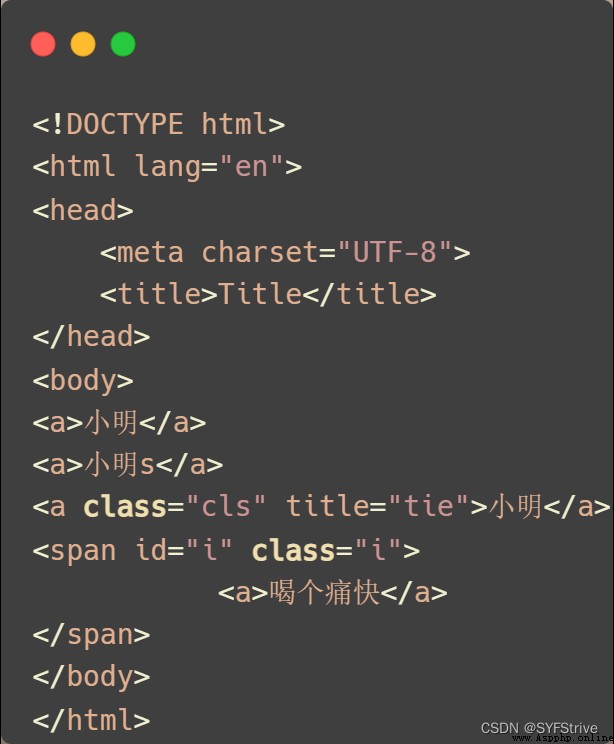
代碼演示
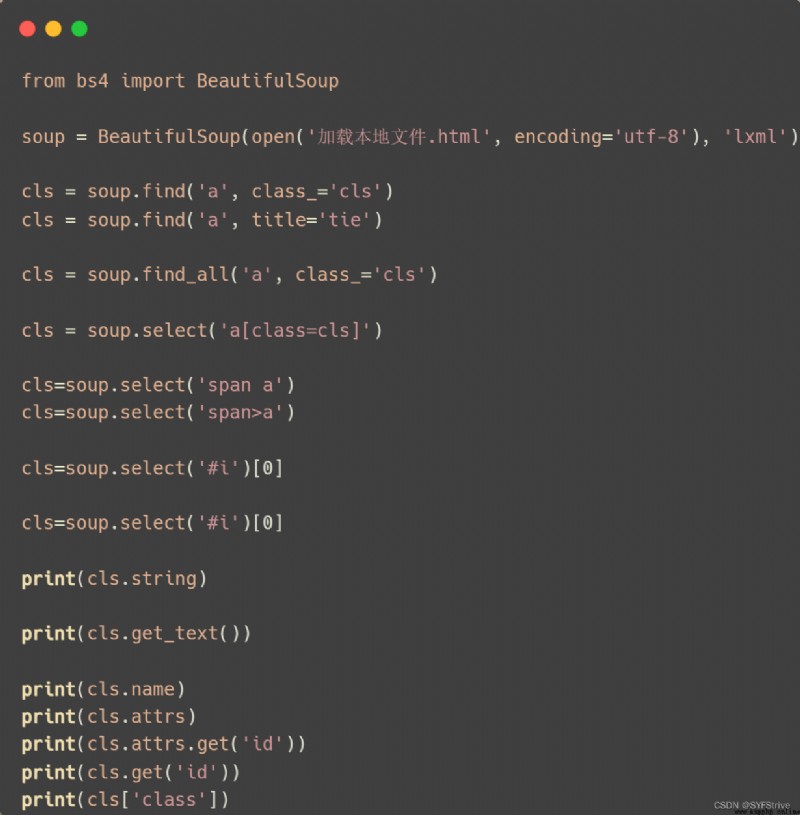
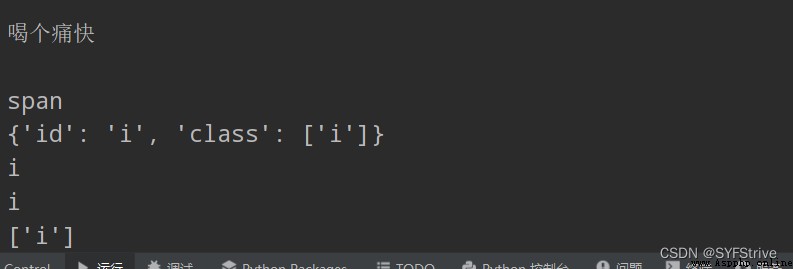
結果如下圖所示:
獲取想要數據的步驟:先通過xpath插件獲取對應的數據然後再將其轉成對應的Ba4語法即可
代碼演示
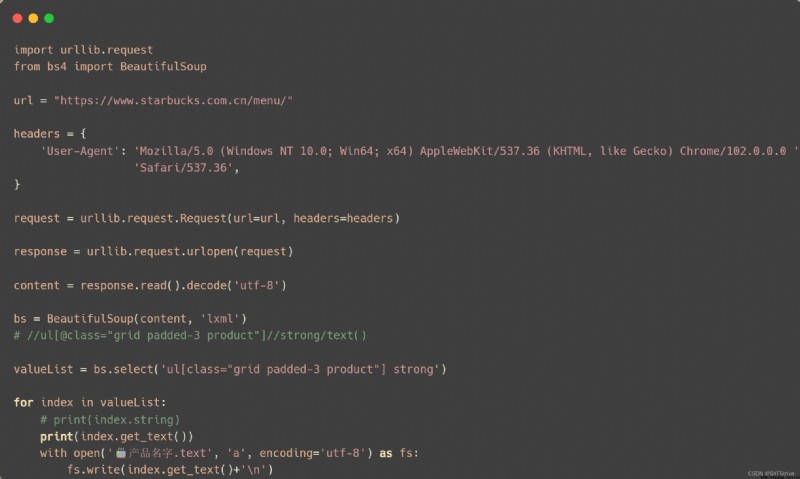
如下圖(爬取成功):


本文章到這裡就結束了,覺得不錯的請給我專欄點點訂閱,你的支持是我們更新的動力,感謝大家的支持,希望這篇文章能幫到大家
點擊跳轉到我的Python專欄

下篇文章再見ヾ( ̄▽ ̄)ByeBye

 Python implementation --- Nanyou Discrete Mathematics Experiment II: Determination of the properties of binary relations on sets
Python implementation --- Nanyou Discrete Mathematics Experiment II: Determination of the properties of binary relations on sets
Catalog One 、 requirement : T