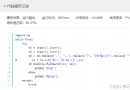
文件的作用
將數據長期保存下來,在需要的時候使用
文本文件
二進制文件
在 計算機 中要操作文件的套路非常固定,一共包含三個步驟:
Python 中要操作文件需要記住 1 個函數和 3 個方法open 函數負責打開文件,並且返回文件對象read/write/close 三個方法都需要通過 文件對象 來調用open 函數的第一個參數是要打開的文件名(文件名區分大小寫) read 方法可以一次性 讀入 並 返回 文件的 所有內容close 方法負責 關閉文件read 方法執行後,會把 文件指針 移動到 文件的末尾# 1. 打開 - 文件名需要注意大小寫
file = open("README")
# 2. 讀取
text = file.read()
print(text)
# 3. 關閉
file.close()
提示
read 方法後,文件指針 會移動到 讀取內容的末尾思考
read 方法,讀取了所有內容,那麼再次調用 read 方法,還能夠獲得到內容嗎?答案
open 函數默認以 只讀方式 打開文件,並且返回文件對象語法如下:
f = open("文件名", "訪問方式")
提示
寫入文件示例
# 打開文件
f = open("README", "w")
f.write("hello python!\n")
f.write("今天天氣真好")
# 關閉文件
f.close()
read 方法默認會把文件的 所有內容一次性讀取到內存readline 方法readline 方法可以一次讀取一行內容讀取大文件的正確姿勢
# 打開文件
file = open("README")
while True:
# 讀取一行內容
text = file.readline()
# 判斷是否讀到內容
if not text:
break
# 每讀取一行的末尾已經有了一個 `\n`
print(text, end="")
# 關閉文件
file.close()
目標
用代碼的方式,來實現文件復制過程
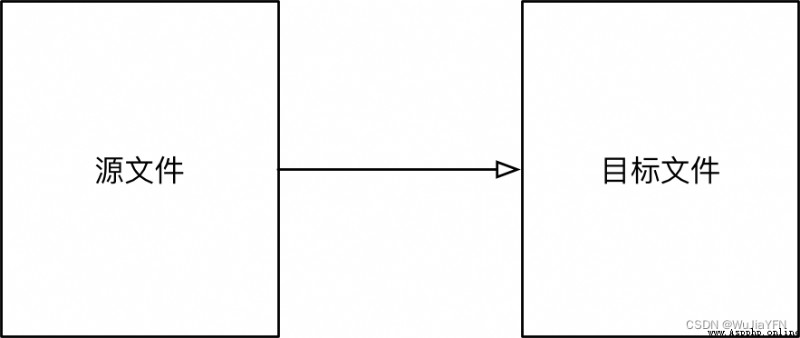
# 1. 打開文件
file_read = open("README")
file_write = open("README[復件]", "w")
# 2. 讀取並寫入文件
text = file_read.read()
file_write.write(text)
# 3. 關閉文件
file_read.close()
file_write.close()
# 1. 打開文件
file_read = open("README")
file_write = open("README[復件]", "w")
# 2. 讀取並寫入文件
while True:
# 每次讀取一行
text = file_read.readline()
# 判斷是否讀取到內容
if not text:
break
file_write.write(text)
# 3. 關閉文件
file_read.close()
file_write.close()
Python 中,如果希望通過程序實現上述功能,需要導入 os 模塊os.rename(源文件名, 目標文件名)02remove刪除文件os.remove(文件名)os.listdir(目錄名)02mkdir創建目錄os.mkdir(目錄名)03rmdir刪除目錄os.rmdir(目錄名)04getcwd獲取當前目錄os.getcwd()05chdir修改工作目錄os.chdir(目標目錄)06path.isdir判斷是否是文件os.path.isdir(文件路徑)提示:文件或者目錄操作都支持 相對路徑 和 絕對路徑
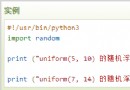
ASCII 編碼,UNICODE 編碼等Python 2.x 默認使用
ASCII編碼格式
Python 3.x 默認使用UTF-8編碼格式
ASCII 編碼256 個 ASCII 字符ASCII 在內存中占用 1 個字節 的空間 8 個 0/1 的排列組合方式一共有 256 種,也就是 2 ** 8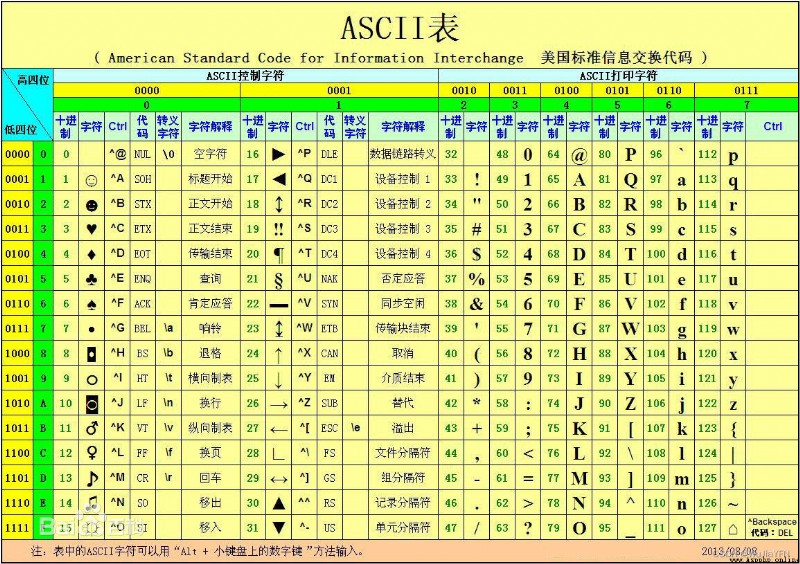
UTF-8 編碼格式UTF-8 字符,涵蓋了 地球上幾乎所有地區的文字UTF-8 是 UNICODE 編碼的一種編碼格式Python 2.x 默認使用
ASCII編碼格式
Python 3.x 默認使用UTF-8編碼格式
utf-8 編碼來處理 python 文件# *-* coding:utf8 *-*
這方式是官方推薦使用的!
# coding=utf8
Python 2.x 中,即使指定了文件使用 UTF-8 的編碼格式,但是在遍歷字符串時,仍然會 以字節為單位遍歷 字符串u,告訴解釋器這是一個 unicode 字符串(使用 UTF-8 編碼格式的字符串)# *-* coding:utf8 *-*
# 在字符串前,增加一個 `u` 表示這個字符串是一個 utf8 字符串
hello_str = u"你好世界"
print(hello_str)
for c in hello_str:
print(c)
-8` 的編碼格式,但是在遍歷字符串時,仍然會 以字節為單位遍歷 字符串
u,告訴解釋器這是一個 unicode 字符串(使用 UTF-8 編碼格式的字符串)# *-* coding:utf8 *-*
# 在字符串前,增加一個 `u` 表示這個字符串是一個 utf8 字符串
hello_str = u"你好世界"
print(hello_str)
for c in hello_str:
print(c)