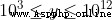運用Python 3.8.1版本,爬取網絡數據,基於卷積神經網絡(CNN)的圖像處理原理,搭建口罩識別技術訓練集,構建人臉識別系統,最終建立高校師生行蹤查詢管理系統。
通過網絡搜集,得到3073張不同性別、年齡以及不同場景中的人佩戴口罩的照片,而未佩戴口罩的人臉圖片從中選取了3249張圖片。以此作為本次研究的數據集,通過對數據集進行預處理,來訓練人臉口罩檢測的模型。
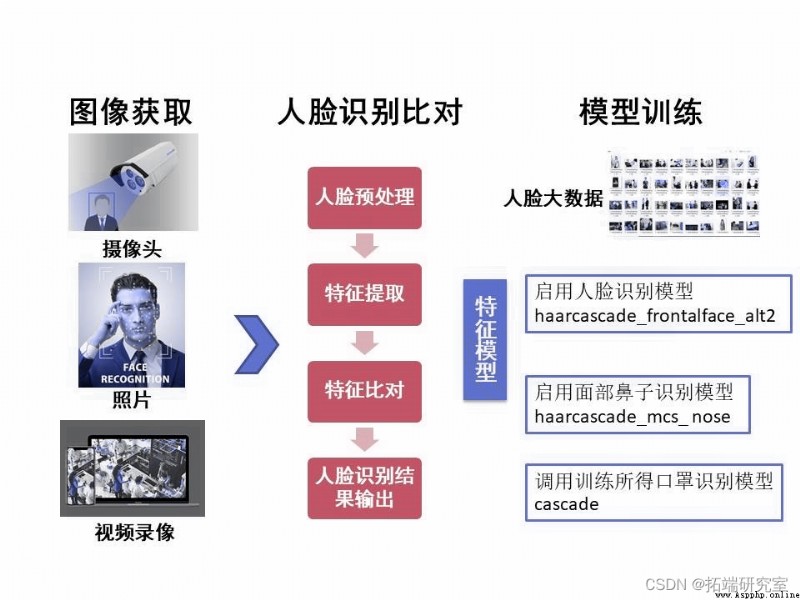 二、確定人臉及口罩識別整體操作流程
二、確定人臉及口罩識別整體操作流程
圖1
(1)對數據集中的人臉進行檢測和對齊
由於有的照片中臉和口罩的比例比較小,其他部位比如手、肩膀等占據了很大的空間,這些對於模型來說都是噪音,會增加CPU的計算量並且會干擾模型。所以我們需要對獲取到的照片進行處理,將人臉裁剪出來。我們利用OpenCv和dlib對數據集進行了人臉的檢測和對齊,以便後續對模型進行訓練。人臉檢測是指將一張圖片中的人臉圈出來,即找到人臉所處的位置,人臉對齊則是基於已經檢測到的人臉,自動找到臉輪廓和眼睛鼻子嘴等標志性特征位置。我們使用dlib對數據集進行了人臉68個特征點的檢測,並將人臉進行對齊,最後將每張照片上的人臉數和對齊的人臉數打印出來。

圖2 檢測人臉68個特征點

圖3 人臉數及對齊人臉數
因為識別有一定的誤差,所以需要對裁剪後的照片進行篩選,將極少數對齊不准確的照片手動刪除,並將數據集的照片進行重命名,便於後續數據集路徑的創建。最後得到戴口罩的照片1010張,作為該模型的正樣本,未戴口罩的照片3030張,作為該模型的負樣本,正負樣本的比例為1:3。
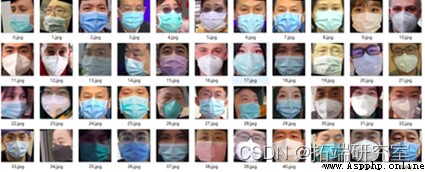

圖4 裁剪後的正負樣本集
(2)正負樣本數據集灰度處理及像素處理
對數據集進行灰度處理可以增強圖像對比度,增大圖片的動態范圍,讓圖像更清晰,特征更明顯,能夠更好的對模型進行訓練。除此之外,還需要將正負樣本各自的照片像素設為相同的值,正樣本數據集的像素最佳設為20x20,這樣的模型訓練精度更高,而負樣本數據集像素則應不低於50x50,如此可以加快模型訓練的速度,此處我們將負樣本的數據集像素調節為80 x80。最後通過cmd命令分別生成佩戴有口罩和未佩戴口罩的圖片路徑的txt文件。


圖5 灰度、像素處理後的正負樣本
(3) 訓練人臉口罩數據集模型
訓練級聯分類器時使用的是opencv3.4.1版中的opencv_createsamples.exe和opencv_traincascade.exe兩個程序。opencv_traincascade 支持不僅支持 Haar特征也支持 LBP特征,同時還可以增強其他的特征。在檢測時上述兩種特征的准確率都依賴於訓練時的訓練參數以及訓練數據的質量。此次我們在訓練口罩識別模型時提取了Haar特征,其最主要的優勢在於它的計算較為迅速。可以用opencv_createsamples來准備用於訓練的測試數據和正樣本數據, 這些數據能夠被opencv_traincascade 程序支持。
在測試時,我們還加入了對人臉鼻子的識別,即當識別到人臉時若還識別到鼻子,則顯示為未佩戴口罩,能夠更加有效地對口罩佩戴是否規范。

圖6 口罩識別系統實踐效果圖
(4)口罩識別訓練模型評價
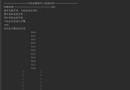
訓練集運行結果如下:
===== TRAINING 4-stage =====
<BEGIN
POS count : consumed 800 : 813
NEG count : acceptanceRatio 2600 : 0.00584079
Precalculation time: 25.945如圖所示,執行該命令時,一些參數信息被終端首先輸出。然後輸出級聯分類器中每級強分類器的訓練信息,我們設置的numStages為10,於是一共有10個強分類器:0-stage至9-stage。圖中是第4級強分類器的信息。我們分別分析這些信息如下所示:
===== TRAINING 4-stage =====
<BEGIN表示開始訓練第4級強分類器。
【POS count : consumed800: 813】在訓練本級強分類器時,能夠使用的800個正樣本圖像是從813個正樣本圖像集中選取出來的,說明此時沒有被識別出來的正樣本有13個。此時的識別率為98.4%(800/813=0.984).
【NEG count : acceptanceRatio 2600 : 0.00584079】可用2600個負樣本圖像訓練本級強分類器,該數是opencv_traincascade.exe命令中參數numNeg指定的數量,後面的0.00584079表示當前級聯分類器預測的這些被預測為正樣本而實際為負樣本的2600幅圖像是從多少個負樣本圖像中得到的。當前已得到了4個強分類器:O-stage、1-stage、2-stage、3-stage。當即將訓練的第5個強分類器4-stage運行結束後,這5個強分類器構成的級聯分類器的最大錯誤率為:0.25x0.25x0.25x0.25=0.000976,已經滿足了要求,無需繼續訓練,系統會停止運行。
【Precalculation time: 25.945】這表示,在沒有構建強分類器之前,我們計算好了一部分特征值,這時預先計算的特征值所消耗的時間。該值由opencv_traincascade.exe命令中的參數precalcValBufSize和precalcldxBufSize決定,如果我們在此設置了更大的內存,就能存儲更多特征值,與此同時所花費的時間就越長。
表示此時該級的強分類器已經得到,因為識別率和錯誤率都滿足了要求,所以此級強分類器的訓練結束。
【Training until now has taken 0 days 0 hours 39 minutes 53 seconds】表示到目前為止,訓練級聯分類器共用時39分53秒。此時,就訓練得到了我們需要的級聯分類器數據,我們利用它就可以識別出人臉。
本項目的主要工作可以概括為以下幾點:
一、基於卷積神經網絡的人臉識別。達到以下效果:
1、從視頻中識別人臉,並實時標出面部特征點。2、建cv2攝像頭對象,我們使用電腦自帶攝像頭(若安裝外部攝像頭,則自動切換到外部攝像頭)。3、針對高清視頻的多幀連續對照識別、對監控設備的視頻數據進行解碼,並分離數據幀、形成每幀視頻的圖像數據,從而將人臉識別率呈指數級大幅提升。4、設置每幀數據延時為1ms,使用人臉檢測器檢測每一幀圖像中的人臉做灰度處理,並輸出人臉數。5、對每個人臉定位畫出方框,顯示識別結果。6、添加快捷功能並在識別頁面添加按鍵說明:按下s鍵截圖保存,按下q鍵退出。
二、口罩識別
基於卷積神經網絡的口罩識別。對於檢測到的三類情況:①戴口罩(捂住口鼻)②戴口罩(未捂住口鼻)③未戴口罩做出了no mask ;no mask; have mask的判斷。
三、搭建了師生端疫情防控平台,實時查詢個人進出校內公共場所及進出校內外情況。提供了一個核查與監督的平台。

在此對Yuling Zhang對本文所作的貢獻表示誠摯感謝,她專長深度學習、數據采集、回歸預測。

最受歡迎的見解
1.R語言實現CNN(卷積神經網絡)模型進行回歸
2.r語言實現擬合神經網絡預測和結果可視化
3.python用遺傳算法-神經網絡-模糊邏輯控制算法對樂透分析
4.R語言結合新冠疫情COVID-19股票價格預測:ARIMA,KNN和神經網絡時間序列分析
5.Python TensorFlow循環神經網絡RNN-LSTM神經網絡預測股票市場價格時間序列和MSE評估准確性
6.Matlab用深度學習長短期記憶(LSTM)神經網絡對文本數據進行分類
7.用於NLP的seq2seq模型實例用Keras實現神經機器翻譯
8.R語言用FNN-LSTM假近鄰長短期記憶人工神經網絡模型進行時間序列深度學習預測
9.Python用RNN循環神經網絡:LSTM長期記憶、GRU門循環單元、回歸和ARIMA對COVID-19新冠疫情新增人數時間序列預測