摘要:本文講述如何編寫scrapy爬蟲。
本文分享自華為雲社區《學python,怎麼能不學習scrapy呢,這篇博客帶你學會它》,作者: 夢想橡皮擦 。
在正式編寫爬蟲案例前,先對 scrapy 進行一下系統的學習。
使用命令 pip install scrapy 進行安裝,成功之後,還需要隨手收藏幾個網址,以便於後續學習使用。
安裝完畢之後,在控制台直接輸入 scrapy,出現如下命令表示安裝成功。
> scrapy
Scrapy 2.5.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands: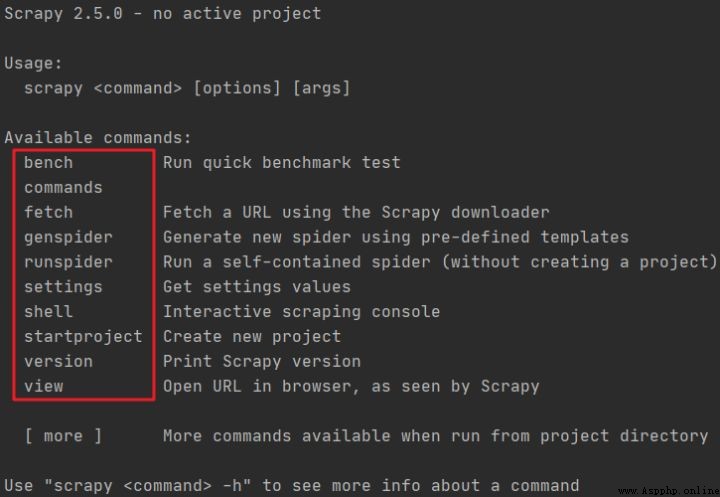
上述截圖是 scrapy 的內置命令列表,標准的格式的 scrapy <command> <options> <args>,通過 scrapy <command> -h 可以查看指定命令的幫助手冊。
scrapy 中提供兩種類型的命令,一種是全局的,一種的項目中的,後者需要進入到 scrapy 目錄才可運行。
這些命令無需一開始就完全記住,隨時可查,有幾個比較常用,例如:
**scrpy startproject <項目名> **
該命令先依據 項目名 創建一個文件夾,然後再文件夾下創建於個 scrpy 項目,這一步是後續所有代碼的起點。
> scrapy startproject my_scrapy
> New Scrapy project 'my_scrapy', using template directory 'e:\pythonproject\venv\lib\site-packages\scrapy\templates\project', created in: # 一個新的 scrapy 項目被創建了,使用的模板是 XXX,創建的位置是 XXX
E:\pythonProject\滾雪球學Python第4輪\my_scrapy
You can start your first spider with: # 開啟你的第一個爬蟲程序
cd my_scrapy # 進入文件夾
scrapy genspider example example.com # 使用項目命令創建爬蟲文件上述內容增加了一些注釋,可以比對著進行學習,默認生成的文件在 python 運行時目錄,如果想修改項目目錄,請使用如下格式命令:
scrapy startproject myproject [project_dir]例如
scrapy startproject myproject d:/d1命令依據模板創建出來的項目結構如下所示,其中紅色下劃線的是項目目錄,而綠色下劃線才是 scrapy 項目,如果想要運行項目命令,則必須先進入紅色下劃線 my_scrapy 文件夾,在項目目錄中才能控制項目。
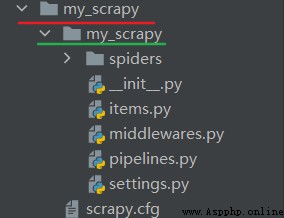
使用命令 scrapy genspider [-t template] <name> <domain> 生成爬蟲文件,該方式是一種快捷操作,也可以完全手動創建。創建的爬蟲文件會出現在 當前目錄或者項目文件夾中的 spiders 文件夾中,name 是爬蟲名字,domain 用在爬蟲文件中的 alowed_domains 和 start_urls 數據中,[-t template] 表示可以選擇生成文件模板。
查看所有模板使用如下命令,默認模板是 basic。
> scrapy genspider -l
basic
crawl
csvfeed
xmlfeed創建第一個 scrapy 爬蟲文件,測試命令如下:
>scrapy genspider pm imspm.com
Created spider 'pm' using template 'basic' in module:
my_project.spiders.pm此時在 spiders 文件夾中,出現 pm.py 文件,該文件內容如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['imspm.com']
start_urls = ['http://imspm.com/']
def parse(self, response):
pass使用命令 scrapy crawl <spider>,spider 是上文生成的爬蟲文件名,出現如下內容,表示爬蟲正確加載。
>scrapy crawl pm
2021-10-02 21:34:34 [scrapy.utils.log] INFO: Scrapy 2.5.0 started (bot: my_project)
[...]scrapy 工作流程非常簡單:
接下來為大家演示 scrapy 一個完整的案例應用,作為 爬蟲 120 例 scrapy 部分的第一例。
> scrapy startproject my_project 爬蟲
> cd 爬蟲
> scrapy genspider pm imspm.com獲得項目結構如下:
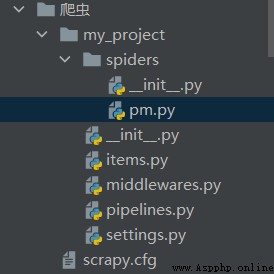
上圖中一些文件的簡單說明。
使用 scrapy crawl pm 運行爬蟲之後,所有輸出內容與說明如下所示:
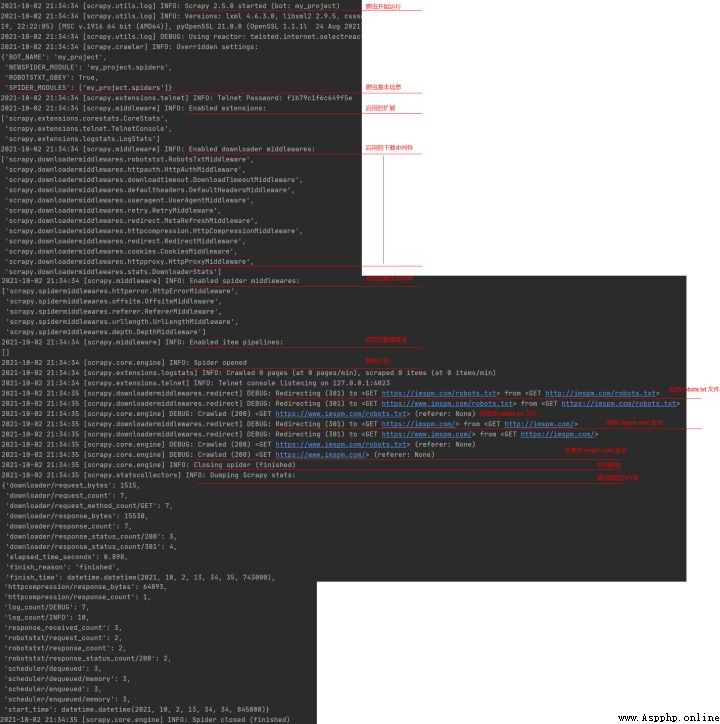
上述代碼請求次數為 7 次,原因是在 pm.py 文件中默認沒有添加 www,如果增加該內容之後,請求次數變為 4。

現在的 pm.py 文件代碼如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['www.imspm.com']
start_urls = ['http://www.imspm.com/']
def parse(self, response):
print(response.text)其中的 parse 表示請求 start_urls 中的地址,獲取響應之後的回調函數,直接通過參數 response 的 .text 屬性進行網頁源碼的輸出。
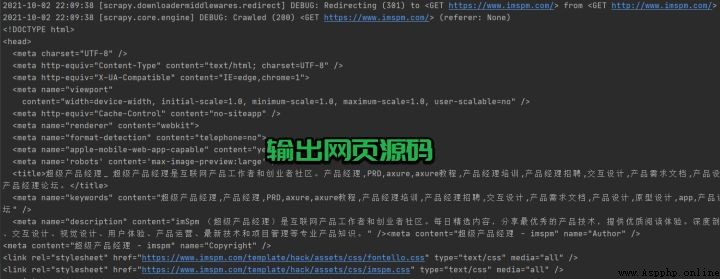
在存儲之前,需要手動定義一個數據結構,該內容在 items.py 文件實現,對代碼中的類名進行了修改,MyProjectItem → ArticleItem。
import scrapy
class ArticleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 文章標題
url = scrapy.Field() # 文章地址
author = scrapy.Field() # 作者修改 pm.py 文件中的 parse 函數,增加網頁解析相關操作,該操作類似 pyquery 知識點,直接觀察代碼即可掌握。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for item in list_item:
title = item.css('.title::text').extract_first() # 直接獲取文本
url = item.css('.a_block::attr(href)').extract_first() # 獲取屬性值
author = item.css('.author::text').extract_first() # 直接獲取文本
print(title, url, author)其中 response.css 方法返回的是一個選擇器列表,可以迭代該列表,然後對其中的對象調用 css 方法。
在 pm.py 中導入 items.py 中的 ArticleItem 類,然後按照下述代碼進行修改:
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接獲取文本
url = i.css('.a_block::attr(href)').extract_first() # 獲取屬性值
author = i.css('.author::text').extract_first() # 直接獲取文本
# print(title, url, author)
# 對 item 進行賦值
item['title'] = title
item['url'] = url
item['author'] = author
yield item此時在運行 scrapy 爬蟲,就會出現如下提示信息。
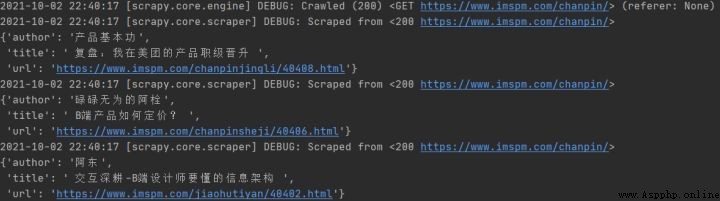
此時完成了一個單頁爬蟲
接下來對 parse 函數再次改造,使其在解析完第 1 頁之後,可以解析第 2 頁數據。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接獲取文本
url = i.css('.a_block::attr(href)').extract_first() # 獲取屬性值
author = i.css('.author::text').extract_first() # 直接獲取文本
# print(title, url, author)
# 對 item 進行賦值
item['title'] = title
item['url'] = url
item['author'] = author
yield item
next = response.css('.nav a:nth-last-child(2)::attr(href)').extract_first() # 獲取下一頁鏈接
# print(next)
# 再次生成一個請求
yield scrapy.Request(url=next, callback=self.parse)上述代碼中,變量 next 表示下一頁地址,通過 response.css 函數獲取鏈接,其中的 css 選擇器請重點學習。
yield scrapy.Request(url=next, callback=self.parse) 表示再次創建一個請求,並且該請求的回調函數是 parse 本身,代碼運行效果如下所示。

如果想要保存運行結果,運行下面的命令即可。
scrapy crawl pm -o pm.json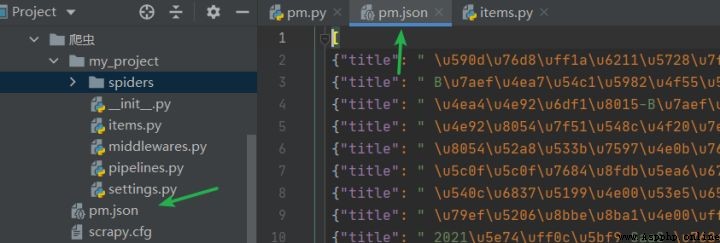
如果想要將每條數據存儲為單獨一行,使用如下命令即可 scrapy crawl pm -o pm.jl 。
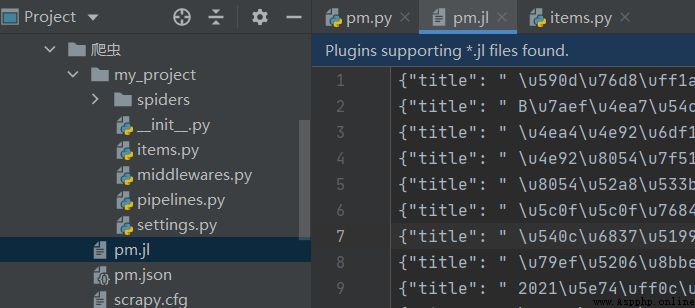
生成的文件還支持 csv 、 xml、marchal、pickle ,可自行嘗試。
打開 pipelines.py 文件,修改類名 MyProjectPipeline → TitlePipeline,然後編入如下代碼:
class TitlePipeline:
def process_item(self, item, spider): # 移除標題中的空格
if item["title"]:
item["title"] = item["title"].strip()
return item
else:
return DropItem("異常數據")該代碼用於移除標題中的左右空格。
編寫完畢,需要在 settings.py 文件中開啟 ITEM_PIPELINES 配置。
ITEM_PIPELINES = {
'my_project.pipelines.TitlePipeline': 300,
}300 是 PIPELINES 運行的優先級順序,根據需要修改即可。再次運行爬蟲代碼,會發現標題的左右空格已經被移除。
到此 scrapy 的一個基本爬蟲已經編寫完畢。
點擊關注,第一時間了解華為雲新鮮技術~