正因為pandas是在numpy基礎上實現,其核心數據結構與numpy的ndarray十分相似,但pandas與numpy的關系不是替代,而是互為補充。pandas就數據處理上比numpy更加強大和智能,而numpy比pandas更加基礎和強大。個人感覺,它們關系很像excel和wps。
Pandas的導入也很簡單,語法如下:
import pandas as pd
關於pandas的知識點,總結如下圖:
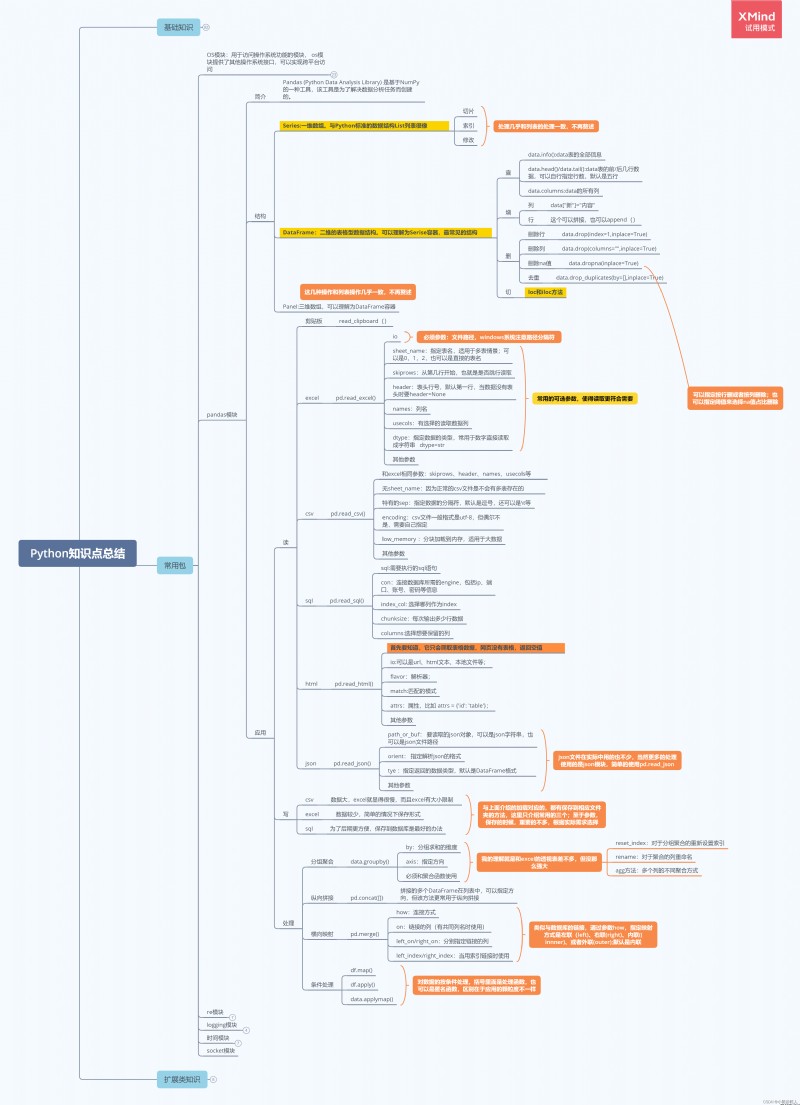
Pandas核心數據結構有兩種,即一維的series和二維的dataframe,就像excel中的列和表的關系。下面就這兩種數據結構展開更加詳細的介紹。
Series,一維數組。與Python標准的數據結構List列表很像,你甚至可以把它理解成excel表的列。想象一下,對於列數據,我們可以做什麼?可以取任意行的數據、可以取指定行的數據、還可以修改相應的數據,這在Series中也可以實現,對應的分別是Series的切片、索引和修改。
# 導入Pandas庫
import pandas as pd
# 構建Series,其中index和name是可選項
series = pd.Series([1,2,"da"],index=["a","b","c"],name="ss")
series
# 結果輸出
a 1
b 2
c da
Name: ss, dtype: object
# 切片
series[:2]
# 結果輸出
a 1
b 2
Name: ss, dtype: object
# 索引
series["a"]
# 結果輸出
1
# 修改值
series["a"] = 6
series[1] = 88
series
# 結果輸出
a 6
b 88
c da
Name: ss, dtype: object
# Series的屬性:dtype, index, values, name
series.dtype
series.index
series.values
series.name
# 結果輸出
dtype('O')
Index(['a', 'b', 'c'], dtype='object')
array([6, 88, 'da'], dtype=object)
'ss'
DataFrame,二維數組,也可以說是表。同樣的,你可以把它理解成excel表的表格。想象一下,對於表格數據,我們可以做什麼?可以對列增刪改、可以對行增刪改、當然對“單元格”數據也可以操作。那是不是我們可以對DataFrame實現上述的操作呢?答案是肯定的。話不多說,直接上代碼:
# 導入Pandas庫
import pandas as pd
# 構建DataFrame,其中index、dtype和columns是可選項,
dataFrame = pd.DataFrame([[1,2,3],[4,5,6]],index=["a","b"],columns=["第一列","第二列","第三列"])
dataFrame
第一列 第二列 第三列
a 1 2 3
b 4 5 6
# 切片,常規切片只能切行,要想切列,就得使用loc和iloc,loc使用索引和列名切,iloc使用行號和列號切
dataFrame[0:1]
第一列 第二列 第三列
a 1 2 3
dataFrame.loc['a']
第一列 1
第二列 2
第三列 3
Name: a, dtype: int64
dataFrame.loc[::,"第一列"]
a 1
b 4
Name: 第一列, dtype: int64
dataFrame.loc["a","第一列"]
1
dataFrame.iloc[:1]
第一列 第二列 第三列
a 1 2 3
dataFrame.iloc[::,1]
a 2
b 5
Name: 第二列, dtype: int64
dataFrame.iloc[1,1]
5
# 修改、增加,修改只要把切到的位置賦值即可,不再贅述,主講增加
# 新增列
dataFrame["新增列"] = 6
# 新增行
dataFrame.loc["c"] = [55,88,99,66]
dataFrame
第一列 第二列 第三列 新增列
a 1 2 3 6
b 4 5 6 6
c 55 88 99 66
# 另外,append也可以增加,但是它增加的索引是默認值,而且之前的index會變列
dataFrame.append([55])
0 新增列 第一列 第三列 第二列
a NaN 6.0 1.0 3.0 2.0
b NaN 6.0 4.0 6.0 5.0
c NaN 66.0 55.0 99.0 88.0
0 55.0 NaN NaN NaN NaN
# 刪除可以分好幾種,下面一一介紹
# 刪除行
dataFrame.drop(index="c",inplace=True)
# 刪除列,注意這裡的0是列名哦
dataFrame.drop(columns=0,inplace=True)
# 刪除nan值,參數axis指定刪除行還是列,0代表行,1代表列
# how指定是有一個舊刪除,還是所有都為nan值菜刪除,可選值'any', 'all'
# thresh阈值,指定行或者列超過指定的個數舊刪除
# inplace是否在源數據刪除,True代表是,False代表否
dataFrame.dropna(inplace=True)
# 刪除重復值
# 參數subset: 指定去重依據,多條件用[]括起來
# keep: 保留第一個還是最後一個,默認第一個,可選值first、last
# inplace:是否在源數據刪除
dataFrame.drop_duplicates()
# 查看數據可以對數據有個大體的認知
# 前N行,不寫參數N,則是前五行
dataFrame.head(N)
# 後N行,不寫參數N,則是後五行
dataFrame.tail(N)
# 總體信息,包括索引,各列類型,整體數據類型,內存大小等信息
dataFrame.info()
<class 'pandas.core.frame.DataFrame'>
Index: 4 entries, a to 0
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 1 non-null float64
1 新增列 3 non-null float64
2 第一列 3 non-null float64
3 第三列 3 non-null float64
4 第二列 3 non-null float64
dtypes: float64(5)
memory usage: 192.0+ bytes
Pandas支持了非常豐富的文件類型,也就是說,它可以讀取和保存多種類型的數據,比如:excel文件、csv文件、或者json文件、sql文件,甚至html文件等,這對我們獲取數據很方便,這裡挑常用的幾個講解,其他基本大同小異,注意特殊參數就行,讀者自行查閱。
excel無疑是接觸最多的數據源,所有首先講解pandas讀取excel文件的方法。
pd.read_excel()
參數詳解:
io:文件路勁,可以是相對路徑,可以是絕對路徑
sheet_name:excel存在多個sheet的情況,所以可以指定sheet名(列1,列2…)或者指定第幾個(0,1,2…),默認第一個。
usecols:提取特定的列,可以是列名,也可以是列號,[]括起來
header:以數據的第幾行做標題行,和後面的參數skiprows 很像,都能是跳過幾行
dtype:指定讀取到的數據格式
skiprows :跳過幾行,和header類似
excel雖然是使用做多的數據格式,但是由於excel存在諸多問題,如:數據加載慢、多sheet問題,沒法保存大數據(excel單個表只能100w多一點),所以csv就顯得優秀很多,上述問題都不存在。
pd.read_csv()
讀取時的參數很多都是一樣的,所以不再贅述,只講解不一樣的參數。
和Excel不同參數詳解:
sep:csv文件並不是表格格式,所以要指定分隔符,默認是逗號,有事還可能是”\t“
encoding:csv文件不像excel只有一種編碼,所以使用時有時候需要指定編碼格式。utf8或者gb2312等
不得不說,現在好多數據都是直接在數據庫提取的,好在pandas也有專門的獲取方法,代碼如下:
pd.read_sql(sql, con)
參數詳解:
sql:sql語句,比如"select * from test"
con:鏈接數據庫的信息,包括ip、user、密碼、數據庫等,con = pymysql.connect(
host=‘182.225.32.220’, # 本地數據庫
user=‘root’,
password=‘***’,
db=‘financial’,
charset=‘utf8’)
對於寫文件,重要參數幾乎一樣,這裡只使用excel做演示:
dataFrame.to_excel("輸出.xlsx",index=False,sheet_name="1")
參數說明:
excel_writer:保存文件路徑,不寫絕對路徑則保存在當前目錄下。注意文件後綴(必須)
sheet_name:保存excel文件中sheet的名字(excel特有)
index:是否輸出索引列,一般不輸出(通用)
encoding:指定輸出文件編碼(通用)
startrow/startcol:輸出文件在excel文件第幾行幾列開始(excel特有)
sep:輸出的csv文件以什麼分割,默認逗號(csv特有)
以上基本是常用參數,其他參數用的不多,默認即可,有特殊需求就百度查詢。
需要注意的是,保存文件要選擇適應的類型,具體如下:

利用Pandas進行數據分析,基礎操作就是Data Frame的各種操作,這裡不再贅述。
應該都用過Excel的透視表吧,很強大對不對,幸好,pandas也有相應的功能,且不必Excel的差,甚至更加強大一些。
假設我們有一份數據(如下圖),我們想計算大部維度的銷售額、訂單數量以及訂單量;或者大部小組兩個維度的三個聚合值,怎麼快速計算呢?這就用到pandas中的groupby函數,具體用法往下看。
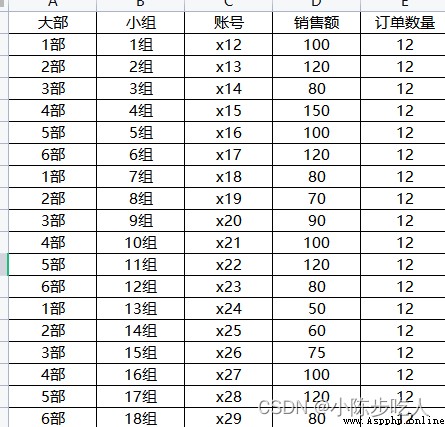
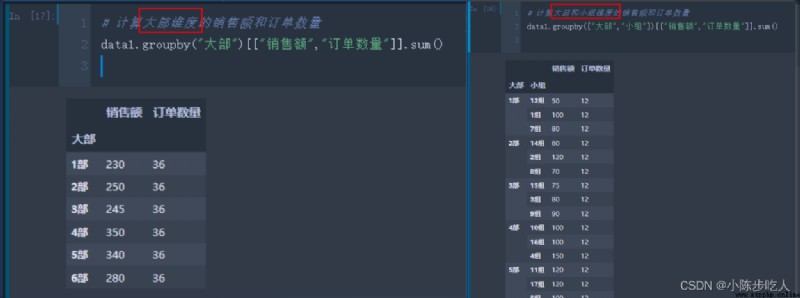
上圖我們分別就大部維度、大部小組維度計算了銷售額和訂單數量的求和,看了效果,咱們在細細講解下groupby函數。
常用參數:
by:指定的分組依據,多個的時候用[]括起來
axis:聚合方向,默認對列聚合,可選值0(縱向,默認)和1(橫向)
level:當聚合依據是索引時使用,默認None
聚合的列
上圖中的[[“銷售額”,“訂單數量”]],就是需要聚合的列,根據實際使用,如果是所有列,可以不寫這個。
聚合方式:
上圖中,使用的聚合方式是sum,代表在給定的維度進行求和。當然不只能求和,其他聚合方式如下圖:
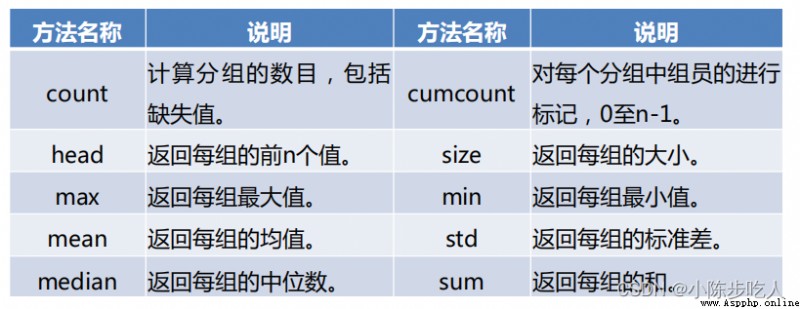
可能很多人想說,我需要聚合的方式要根據列選擇,上面這只能一種,不是很方便,別慌,咱接著看:
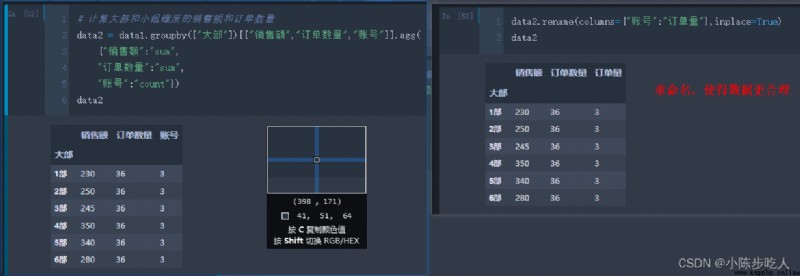
說明:
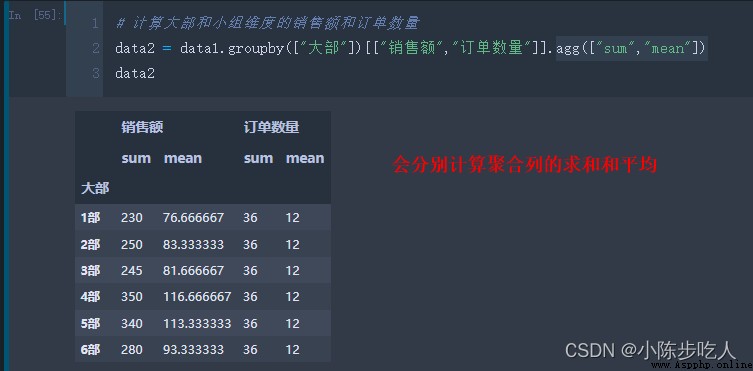
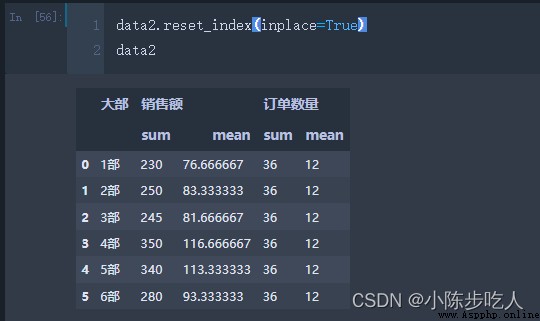
上面講到的分組聚合和Excel中的透視表很像,但是又不能對列和行一起做透視,那有沒有和Excel中的透視表功能一樣的功能呢,當然是有的,那就是pandas中的pivot_table。
關於pivot_table的使用,這裡不再贅述,讀者可以看下面兩篇文章。
Pandas 透視表
Pandas 透視表的提取
想象這麼一個場景,你有兩個表,你需要把裡面的內容合在一張表上,你會怎麼做?手動復制嘛?那如果是一百張表呢?這就要用到接下來講解的方法了。
concat函數參數:
objs:需要合並的數據
axis:合並方向,可以橫向拼接,也可以縱向拼接
join:合並方式,類似內聯外聯,默認外聯,不一樣的nan補充
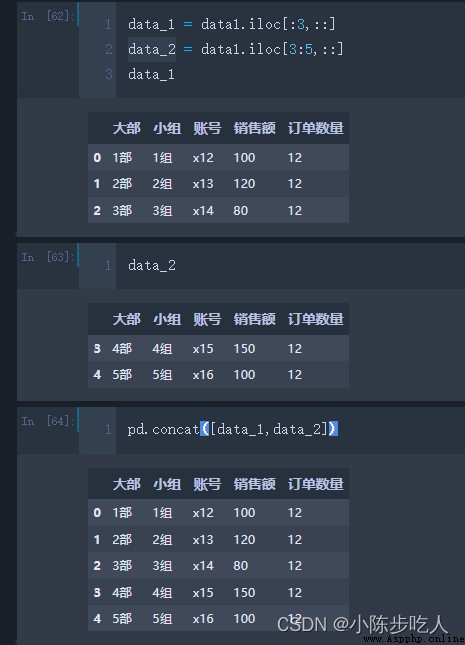
注意:
merge函數和sql中的內外聯一致,可以實現左聯、右聯、內聯和外聯。
merge函數詳解
left:數據1
right:數據2
how: 連接方式,可選inner(默認),outer,left,right
on:用來連接的列,使用on時,數據1和數據2用來連接的列名要相同,不相同時用下面參數
left_on:單獨指定左邊表的連接列,
right_on:單獨指定右邊表的連接列,
left_index: 是否使用左邊表的索引連接,默認False
right_index: 是否使用右邊表的索引連接,默認False
效果演示:
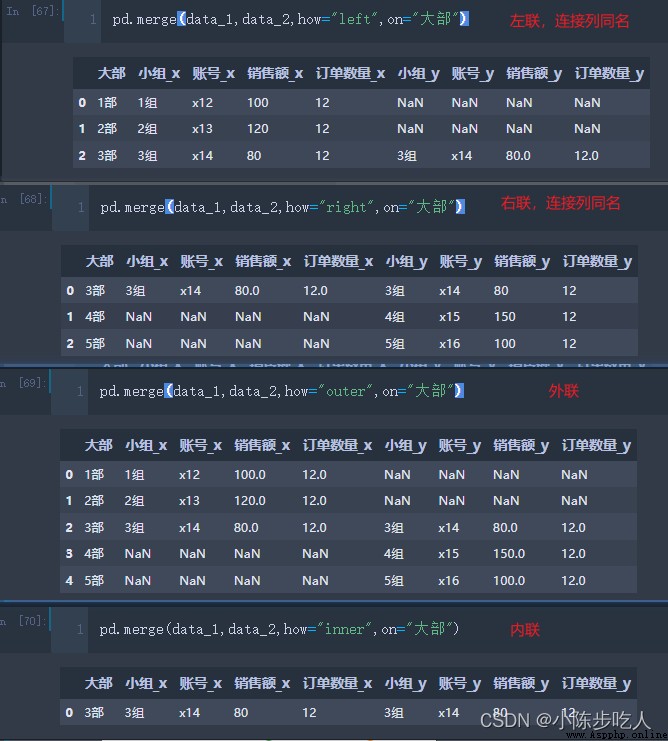
所以總的來說,拼接有兩種方法可以選擇,縱向拼接就用concat,橫向拼接就用merge。
實際工作中,我們在利用 pandas進行數據處理的時候,經常會對數據框中的單行、多行(列也適用)甚至是整個數據進行某種相同方式(單一邏輯或者自定義函數)的處理,這個時候雖然可以用For來實現,但是for的效率太低了,好在Pandas提供更加高效的函數,map、apply、applymap,三者的區別在於map是針對單列,apply是針對多列,applymap是針對全部元素(可以理解成單元格)。
例如根據大部構建新的列,構建規則是在原來大部的基礎上加上成都,這樣的規則。
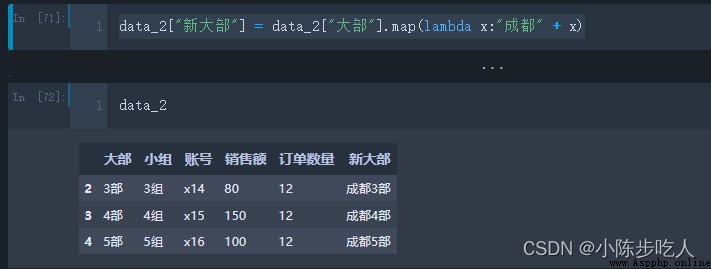
需要說明的是,上面例子雖然是map實現的,但是apply也可以實現哈。
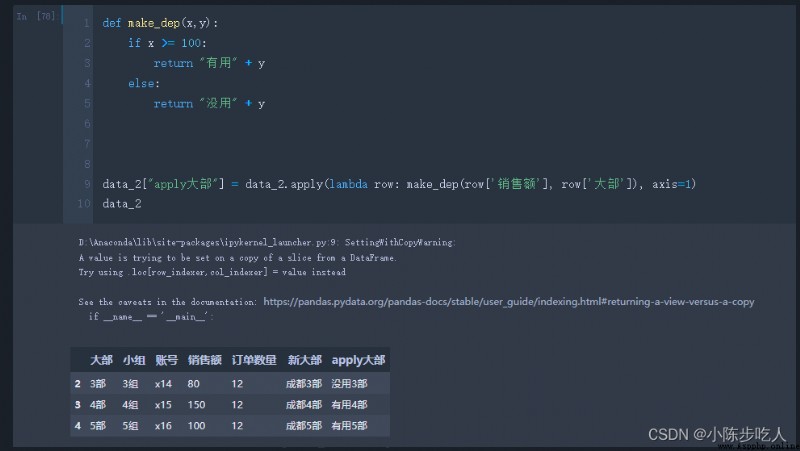
上面已經說了,apply是可以應用於多列的,這是map無法實現的,看下面的例子:
大家都知道,Matplotlib 是眾多 Python 可視化包的鼻祖,也是Python最常用的標准可視化庫,其功能非常強大,同時也非常復雜,想要搞明白並非易事。雖然現在Python可視化的包有很多,視覺效果也都很好,但是有時候我們只是需要看看數據的分布,沒必要多麼的美觀,因為美觀的代價是復雜。所幸pandas本身就有數據可視化的功能已經可以滿足我們大部分的要求了,讓我們看看pandas自帶的可視化操作。
在開始之前,我們說一下,Pandas在繪圖時,會顯示中文為方塊,效果如下:

顯然,這個問題是不能忽視的,所以利用如下代碼即可修正。
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.serif'] = ['KaiTi']
mpl.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題,或者轉換負號為字符串
好的,問題解決完,我們正式開始學習pandas的畫圖功能。畫圖數據如下: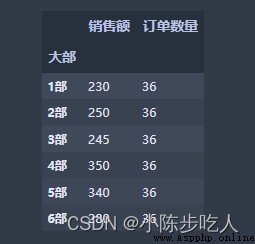
常規線圖:
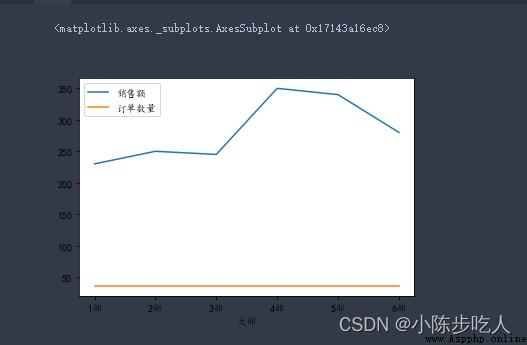
data2.plot.line()
子圖線圖:
data2.plot.line(subplots=True)
常規條形圖:
data2.plot.bar()
堆疊條形圖:
data2.plot.bar(stacked=True)
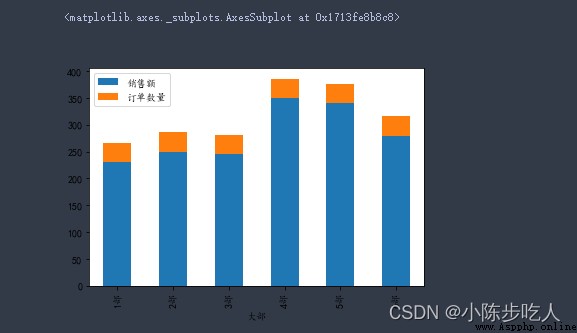
水平條形圖:
data2.plot.barh()
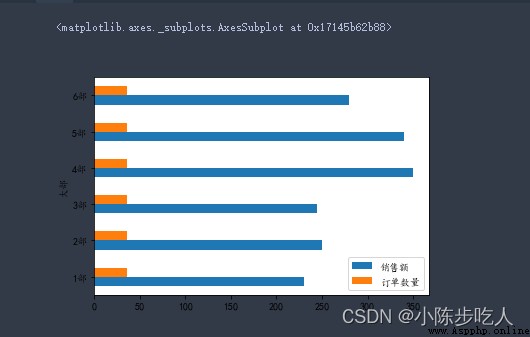
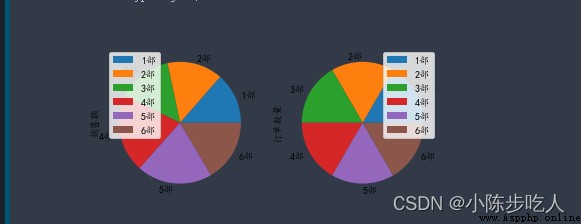
需要注意的是,前面介紹的子圖,也是使用於條形圖(不管是橫向還是縱向)的,增加相應參數就行,後面的圖也不例外,不再贅述。
data2.plot.pie(subplots=True)
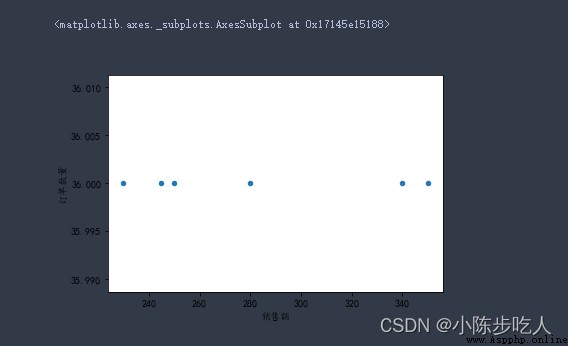
data2.plot.scatter(x=‘銷售額’,y=‘訂單數量’)
data2.hist()
data2.boxplot()
這裡只是羅列各種圖的畫法,關於更多細節,諸如坐標軸的設置、圖例的設置、標題的設置等美化細節,讀者自行查閱。