2008年WesMcKinney開發出的庫
專門用於數據挖掘的開源python庫
以Numpy為基礎,借力Numpy模塊在計算方面性能高的優勢
基於matplotlib,能夠簡便的畫圖
獨特的數據結構
增強圖表可讀性
便捷的數據處理能力
讀取文件方便
封裝了Matplotlib、Numpy的畫圖和計算
一維數據結構,類似於一維數組
創建
pd.Series(data=None, index=None, dtype=None)
通過已有數據創建
通過字典數據創建
屬性
二維表格型數據結構,類似於二維數組或表格
行索引
列索引
創建
pd.DataFrame(data=None, index=None, columns=None)
通過已有數據創建
屬性
shape
index
columns
values
T
.head(5)
.tail(5)
索引的設置
修改行列索引值
重設索引
reset_index(drop=False)
以某列值設置為新的索引
set_index(keys, drop=True)
三維數據結構
多級或分層索引對象
index屬性
創建
存儲3維數組
class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None)
panel數據要是想看到,則需要進行索引到dataframe或者series才可以
直接使用行列索引(先列後行)
結合loc或者iloc使用索引
使用ix組合索引
對DataFrame當中的close列進行重新賦值為1
形式
dataframe排序
df.sort_values(by=, ascending=) , 單個鍵或者多個鍵進行排序
by:指定排序參考的鍵
ascending:默認升序
df.sort_index給索引進行排序
Series排序
>
多個邏輯 &
邏輯運算函數
query(expr)
isin(values)
describe
統計函數
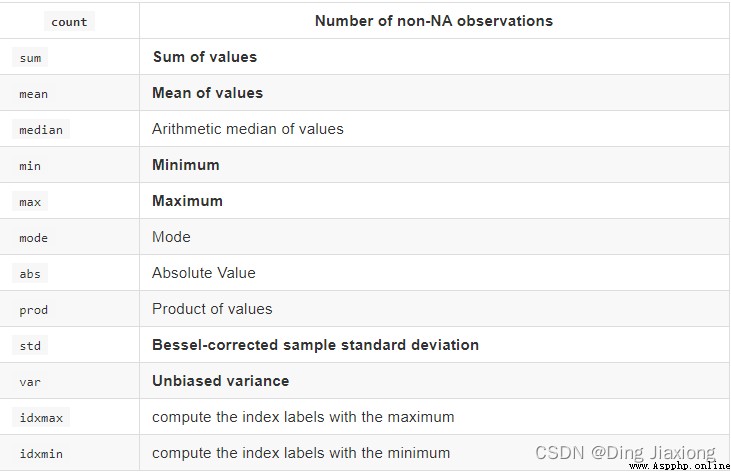
max(0 代表列求結果,1代表行求統計結果)
std() → 標准差
var() → 方差
median() → 中位數
idxmax() 求最大值的位置
idxmin() 求最小值的位置
累計統計函數
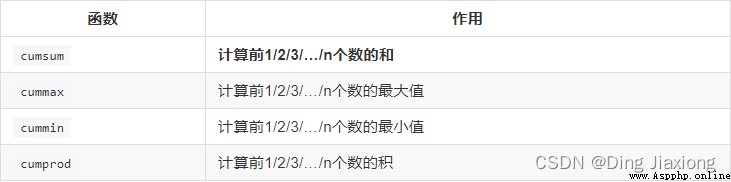
apply(func, axis=0)
kind
pandas.read_csv(filepath_or_buffer, sep =‘,’, usecols )
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode=‘w’, encoding=None)
HDF5文件的讀取和存儲需要指定一個鍵,值為要存儲的DataFrame
pandas.read_hdf(path_or_buf,key =None,** kwargs)
DataFrame.to_hdf(path_or_buf, key, \kwargs)
優先選擇使用HDF5文件存儲
pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
如何處理nan
獲取缺失值的標記方式
NAN
判斷數據中是否包含nan
存在nan
沒有使用nan
pd.isnull(df)
pd.notnull(df)
減少給定連續屬性值的個數
連續屬性的離散化就是在連續屬性的值域上,將值域劃分為若干個離散的區間,最後用不同的符號或整數 值代表落在每個子區間中的屬性值
qcut、cut實現數據分組
get_dummies實現啞變量矩陣
pd.concat([data1, data2], axis=1)
pd.merge(left, right, how=‘inner’, on=None)
可以指定按照兩組數據的共同鍵值對合並或者左右各自
交叉表
透視表