Pandas Series 類似表格中的一個列(column),類似於一維數組,可以保存任何數據類型。
pandas.Series( data, index, dtype, name, copy)
參數說明:
import pandas as pd
students = ['Sam', 'Enzo', 'Lily']
myclass = pd.Series(students)
print(myclass)

從上圖可知,如果沒有指定索引,索引值就從 0 開始
import pandas as pd
students = {
'name1':'Sam', 'name2':'Enzo', 'name3':'Lily'}
myclass = pd.Series(students, name='class')
print(myclass)

從上圖可知,字典的 key 變成了索引值
如果只需要字典中的一部分數據,通過 index 指定就好了
import pandas as pd
students = {
'name1':'Sam', 'name2':'Enzo', 'name3':'Lily'}
myclass = pd.Series(students, index=['name1', 'name3'], name='class')
print(myclass)

import pandas as pd
students = ['Sam', 'Enzo', 'Lily']
index = ['name1', 'name2', 'name3']
myclass = pd.Series(students, index=index, name='class')
print(myclass)

import pandas as pd
students = ['Sam', 'Enzo', 'Lily']
index = ['name1', 'name2', 'name3']
myclass = pd.Series(students, index=index, name='class')
print(myclass['name2'])
print(myclass[1:3])

DataFrame 是一個表格型的數據結構,它含有一組有序的列,每列可以是不同的值類型(數值、字符串、布爾型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 拼接而成
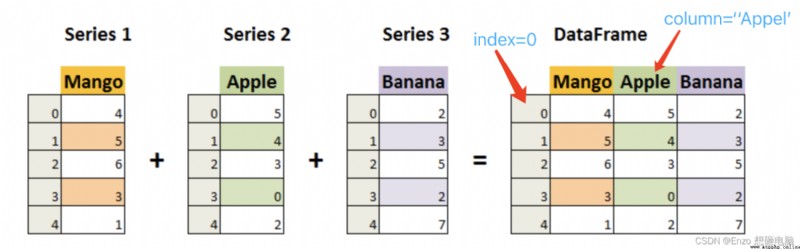
pandas.DataFrame( data, index, columns, dtype, copy)
參數說明:
import pandas as pd
data = [['Google',10],
['Runoob',12],
['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'])
print(df)

寫法一:
import pandas as pd
data = {
'Site':['Google', 'Runoob', 'Wiki'],
'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)

寫法二:
import pandas as pd
data = [{
'Site': 'Google'},{
'Site': 'Runoob', 'Age': 12}]
df = pd.DataFrame(data)
print (df)

import pandas as pd
data = {
'calories':[420, 380, 390],
"duration":[50, 40, 45]}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)

import pandas as pd
data = {
'calories':[420, 380, 390],
"duration":[50, 40, 45]}
df = pd.DataFrame(data)
print(df.loc[0])
print('\n')
print(df.loc[2])

注意:返回結果其實就是一個 Pandas Series 數據。
也可以一次讀取多行數據,注意是使用 [[ … ]] 格式,不是 [… ]
import pandas as pd
data = {
'calories':[420, 380, 390], "duration":[50, 40, 45]}
df = pd.DataFrame(data)
print(df.loc[[0, 2]])

自定義索引時,使用 loc 指定索引值,讀取對應的行
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df.loc["day1"])
print('\n')
print(df.loc[["day1", "day3"]])