BLEU是評價機器翻譯好壞的一種模型,給定機器翻譯的結果和人工翻譯的參考譯文,該模型會自動給出翻譯的得分,分數越高則表明翻譯的結果越好。
為了評價翻譯系統(MT)的翻譯結果的好壞,我們先觀察好的翻譯結果之間的聯系,如下例子:
Example 1:
Candidate 1: It is a guide to action which ensures that the military always obeys the commands of the party.
Candidate 2: It is to insure the troops forever hearing the activity guidebook that party direct.
Reference 1: It is a guide to action that ensures that the military will forever
heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces
always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
從上面例子中我們可以發現候選句子(Candidate)和參考句子(Reference)之間存在一些相同的句子片段,例如:
Candidate 1 - Reference 1: “It is a guide to action”, “ensures that the military”, “commands”
Candidate 1 - Reference 2:“which” , “always” , “of the party”
Candidate 1 - Reference 3:“always”
而
Candidate 2和參考句子之間相同的片段數量不多。
於是,我們可以找到候選句子的每個n-gram在參考句子中出現的次數,並求和,通過上面的分析可以發現,匹配的個數越多,求和的值越大,則說明候選句子更好。
Example 2:
Candidate: the the the the the the the.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
考慮上面的Example 2,如果按照n-grams的方法,候選句子(Candidate),的每個1-gramthe在參考句子中出現的次數都很多,因此,求和的得分也到,按照n-grams的評價方法,Candidate是個很好的翻譯結果,但事實卻並非如此。
於是,我們可以考慮修改n-gram模型:
首先,計算一個單詞在任意一個參考句子出現的最大次數;
然後,用每個(非重復)單詞在參考句子中出現的最大次數來修剪,單詞在候選句子的出現次數;
C o u n t c l i p = m i n ( C o u n t , M a x _ R e f _ C o u n t ) Count_{clip}=min(Count, Max\_Ref\_Count) Countclip=min(Count,Max_Ref_Count)
最後,將這些修剪的次數加起來,除以總的候選句子詞數。
例如在Example 2中:
在Example 1中:
Candidate 1的得分為:17/18;
Candidate 2的得分為:8/14
當我們在長文本中評價時:
p n = ∑ C ∈ { C a n d i d a t e s } ∑ n − g r a m ∈ C C o u n t c l i p ( n − g r a m ) ∑ C ′ ∈ { C a n d i d a t e s } ∑ n − g r a m ′ ∈ C ′ C o u n t ( n − g r a m ′ ) p_n=\frac{\sum_{C\in\{Candidates\}}\sum_{n-gram\in C}Count_{clip}(n-gram)}{\sum_{C'\in\{Candidates\}}\sum_{n-gram'\in C'}Count(n-gram')} pn=∑C′∈{ Candidates}∑n−gram′∈C′Count(n−gram′)∑C∈{ Candidates}∑n−gram∈CCountclip(n−gram)
其中
C a n d i d a t e s Candidates Candidates:表示機器翻譯的譯文
C o u n t ( ) Count() Count():在Candidates中n-gram出現的次數
C o u n t c l i p ( ) Count_{clip}() Countclip():Candidates中n-gram在Reference中出現的次數
n-gram懲罰候選句子中的不出現在參考句子中的單詞;
modified n-gram懲罰在候選句子中比參考句子中出現次數多的單詞;
B P = { 1 i f c > r e 1 − r c i f c ≤ r BP=\left\{ \begin{aligned}1 \qquad if\quad c>r \\ e^{1-\frac{r}{c}} \qquad if \quad c\leq r \end{aligned}\right. BP={ 1ifc>re1−crifc≤r
c c c:Candidate語料庫的長度
r r r:effective Reference的長度:Ref中和Candidate中每句匹配的句子長度之和
B L E U = B P ⋅ e x p ( ∑ n = 1 N w n l o g p n ) BLEU=BP\cdot exp(\sum_{n=1}^Nw_n logp_n) BLEU=BP⋅exp(n=1∑Nwnlogpn)
取對數後為:
log B L E U = m i n ( 1 − r c , 0 ) + ∑ n = 1 N w n log P n \log BLEU=min(1-\frac{r}{c}, 0)+\sum_{n=1}^Nw_n\log P_n logBLEU=min(1−cr,0)+n=1∑NwnlogPn
w n w_n wn:權重,一般為 1 N \frac1N N1
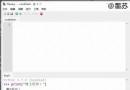
''' BLEU (BiLingual Evaluation Understudy) @Author: baowj @Date: 2020/9/16 @Email: [email protected] '''
import numpy as np
class BLEU():
def __init__(self, n_gram=1):
super().__init__()
self.n_gram = n_gram
def evaluate(self, candidates, references):
''' 計算BLEU值 @param candidates [[str]]: 機器翻譯的句子 @param references [[str]]: 參考的句子 @param bleu: BLEU值 '''
BP = 1
bleu = np.zeros(len(candidates))
for k, candidate in enumerate(candidates):
r, c = 0, 0
count = np.zeros(self.n_gram)
count_clip = np.zeros(self.n_gram)
count_index = np.zeros(self.n_gram)
p = np.zeros(self.n_gram)
for j, candidate_sent in enumerate(candidate):
# 對每個句子遍歷
for i in range(self.n_gram):
count_, n_grams = self.extractNgram(candidate_sent, i + 1)
count[i] += count_
reference_sents = []
reference_sents = [reference[j] for reference in references]
count_clip_, count_index_ = self.countClip(reference_sents, i + 1, n_grams)
count_clip[i] += count_clip_
c += len(candidate_sent)
r += len(reference_sents[count_index_])
p = count_clip / count
rc = r / c
if rc >= 1:
BP = np.exp(1 - rc)
else:
rc = 1
p[p == 0] = 1e-100
p = np.log(p)
bleu[k] = BP * np.exp(np.average(p))
return bleu
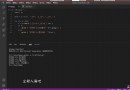
def extractNgram(self, candidate, n):
''' 抽取出n-gram @param candidate: [str]: 機器翻譯的句子 @param n int: n-garm值 @return count int: n-garm個數 @return n_grams set(): n-grams '''
count = 0
n_grams = set()
if(len(candidate) - n + 1 > 0):
count += len(candidate) - n + 1
for i in range(len(candidate) - n + 1):
n_gram = ' '.join(candidate[i:i+n])
n_grams.add(n_gram)
return (count, n_grams)
def countClip(self, references, n, n_gram):
''' 計數references中最多有多少n_grams @param references [[str]]: 參考譯文 @param n int: n-gram的值s @param n_gram set(): n-grams @return: @count: 出現的次數 @index: 最多出現次數的句子所在文本的編號 '''
max_count = 0
index = 0
for j, reference in enumerate(references):
count = 0
for i in range(len(reference) - n + 1):
if(' '.join(reference[i:i+n]) in n_gram):
count += 1
if max_count < count:
max_count = count
index = j
return (max_count, index)
if __name__ == '__main__':
bleu_ = BLEU(4)
candidates = [['It is a guide to action which ensures that the military always obeys the commands of the party'],
['It is to insure the troops forever hearing the activity guidebook that party direct'],
]
candidates = [[s.split() for s in candidate] for candidate in candidates]
references = [['It is a guide to action that ensures that the military will forever heed Party commands'],
['It is the guiding principle which guarantees the military forces always being under the command of the Party'],
['It is the practical guide for the army always to heed the directions of the party']
]
references = [[s.split() for s in reference] for reference in references]
print(bleu_.evaluate(candidates, references))
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation.