點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

*
作者:李小文,先後從事過數據分析、數據挖掘工作,主要開發語言是Python,現任一家小型互聯網公司的算法工程師。
Github: https://github.com/tushushu
1. 原理篇
我們用人話而不是大段的數學公式來講講全連接神經網絡是怎麼一回事。
1.1 網絡結構
靈魂畫師用PPT畫個粗糙的網絡結構圖如下:
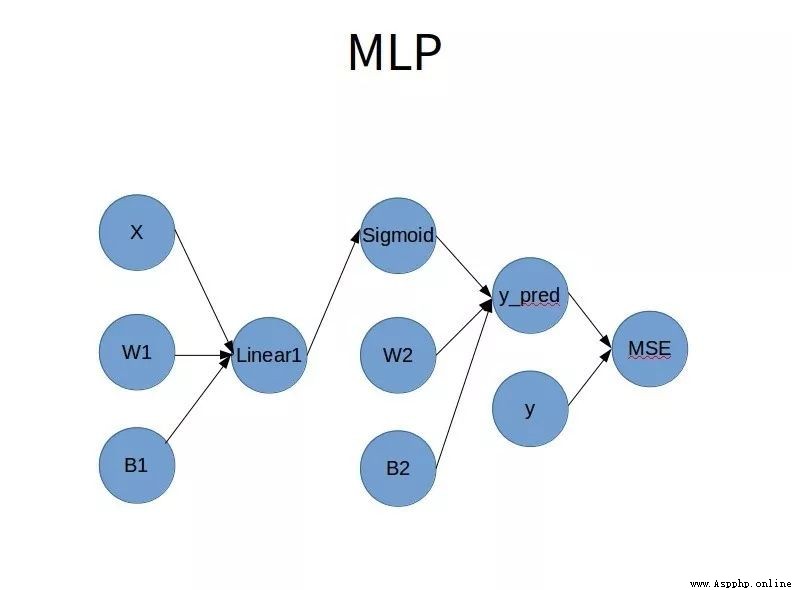
1.2 Simoid函數
Sigmoid函數的表達式是:
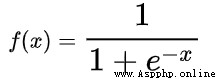
不難得出:
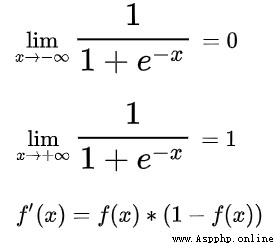
所以,Sigmoid函數的值域是(0, 1),導數為y * (1 - y)
1.3 鏈式求導
z = f(y)
y = g(x)
dz / dy = f'(y)
dy / dx = g'(x)
dz / dz = dz / dy * dy / dx = f'(y) * g'(x)
1.4 向前傳播
將當前節點的所有輸入執行當前節點的計算,作為當前節點的輸出節點的輸入。
1.5 反向傳播
將當前節點的輸出節點對當前節點的梯度損失,乘以當前節點對輸入節點的偏導數,作為當前節點的輸入節點的梯度損失。
1.6 拓撲排序
假設我們的神經網絡中有k個節點,任意一個節點都有可能有多個輸入,需要考慮節點執行的先後順序,原則就是當前節點的輸入節點全部執行之後,才可以執行當前節點。
2. 實現篇
本人用全宇宙最簡單的編程語言——Python實現了全連接神經網絡,便於學習和使用。簡單說明一下實現過程,更詳細的注釋請參考本人github上的代碼。
2.1 創建BaseNode抽象類
將BaseNode作為各種類型Node的父類。包括如下屬性:
name -- 節點名稱
value -- 節點數據
inbound_nodes -- 輸入節點
outbound_nodes -- 輸出節點
gradients -- 對於輸入節點的梯度
class BaseNode(ABC):
def __init__(self, *inbound_nodes, name=None):
self.name = name
self._value = None
self.inbound_nodes = [x for x in inbound_nodes]
self.outbound_nodes = []
self.gradients = dict()
for node in self.inbound_nodes:
node.outbound_nodes.append(self)
def __str__(self):
size = str(self.value.shape) if self.value is not None else "null"
return "<Node name: %s, Node size: %s>" % (self.name, size)
@property
def value(self)->ndarray:
return self._value
@value.setter
def value(self, value):
err_msg = "'value' has to be a number or a numpy array!"
assert isinstance(value, (ndarray, int, float)), err_msg
self._value = value
@abstractmethod
def forward(self):
return
@abstractmethod
def backward(self):
return2.2 創建InputNode類
用於存儲訓練、測試數據。其中indexes屬性用來存儲每個Batch中的數據下標。
class InputNode(BaseNode):
def __init__(self, value: ndarray, name=None):
BaseNode.__init__(self, name=name)
self.value = value
self.indexes = None
@property
def value(self):
err_msg = "Indexes is None!"
assert self.indexes is not None, err_msg
return self._value[self.indexes]
@value.setter
def value(self, value: ndarray):
BaseNode.value.fset(self, value)
def forward(self):
return
def backward(self):
self.gradients = {self: 0}
for node in self.outbound_nodes:
self.gradients[self] += node.gradients[self]2.3 創建LinearNode類
用於執行線性運算。
Y = WX + Bias
dY / dX = W
dY / dW = X
dY / dBias = 1
class LinearNode(BaseNode):
def __init__(self, data: BaseNode, weights: WeightNode, bias: WeightNode, name=None):
BaseNode.__init__(self, data, weights, bias, name=name)
def forward(self):
data, weights, bias = self.inbound_nodes
self.value = np.dot(data.value, weights.value) + bias.value
def backward(self):
data, weights, bias = self.inbound_nodes
self.gradients = {node: np.zeros_like(node.value) for node in self.inbound_nodes}
for node in self.outbound_nodes:
grad_cost = node.gradients[self]
self.gradients[data] += np.dot(grad_cost, weights.value.T)
self.gradients[weights] += np.dot(data.value.T, grad_cost)
self.gradients[bias] += np.sum(grad_cost, axis=0, keepdims=False)2.4 創建MseNode類
用於計算預測值與實際值的差異。
MSE = (label - prediction) ^ 2 / n_label
dMSE / dLabel = 2 * (label - prediction) / n_label
dMSE / dPrediction = -2 * (label - prediction) / n_label
class MseNode(BaseNode):
def __init__(self, label: InputNode, pred: LinearNode, name=None):
BaseNode.__init__(self, label, pred, name=name)
self.n_label = None
self.diff = None
def forward(self):
label, pred = self.inbound_nodes
self.n_label = label.value.shape[0]
self.diff = (label.value - pred.value).reshape(-1, 1)
self.value = np.mean(self.diff**2)
def backward(self):
label, pred = self.inbound_nodes
self.gradients[label] = (2 / self.n_label) * self.diff
self.gradients[pred] = -self.gradients[label]2.5 創建SigmoidNode類
用於計算Sigmoid值。
Y = 1 / (1 + e^(-X))
dY / dX = Y * (1 - Y)
class SigmoidNode(BaseNode):
def __init__(self, input_node: LinearNode, name=None):
BaseNode.__init__(self, input_node, name=name)
@staticmethod
def _sigmoid(arr: ndarray) -> ndarray:
return 1. / (1. + np.exp(-arr))
@staticmethod
def _derivative(arr: ndarray) -> ndarray:
return arr * (1 - arr)
def forward(self):
input_node = self.inbound_nodes[0]
self.value = self._sigmoid(input_node.value)
def backward(self):
input_node = self.inbound_nodes[0]
self.gradients = {input_node: np.zeros_like(input_node.value)}
for output_node in self.outbound_nodes:
grad_cost = output_node.gradients[self]
self.gradients[input_node] += self._derivative(self.value) * grad_cost2.6 創建WeightNode類
用於存儲、更新權重。
class WeightNode(BaseNode):
def __init__(self, shape: Union[Tuple[int, int], int], name=None, learning_rate=None):
BaseNode.__init__(self, name=name)
if isinstance(shape, int):
self.value = np.zeros(shape)
if isinstance(shape, tuple):
self.value = np.random.randn(*shape)
self.learning_rate = learning_rate
def forward(self):
pass
def backward(self):
self.gradients = {self: 0}
for node in self.outbound_nodes:
self.gradients[self] += node.gradients[self]
partial = self.gradients[self]
self.value -= partial * self.learning_rate2.7 創建全連接神經網絡類
class MLP:
def __init__(self):
self.nodes_sorted = []
self._learning_rate = None
self.data = None
self.prediction = None
self.label = None2.8 網絡結構
def __str__(self):
if not self.nodes_sorted:
return "Network has not be trained yet!"
print("Network informantion:\n")
ret = ["learning rate:", str(self._learning_rate), "\n"]
for node in self.nodes_sorted:
ret.append(node.name)
ret.append(str(node.value.shape))
ret.append("\n")
return " ".join(ret)2.9 學習率
存儲學習率,並賦值給所有權重節點。
@property
def learning_rate(self) -> float:
return self._learning_rate
@learning_rate.setter
def learning_rate(self, learning_rate):
self._learning_rate = learning_rate
for node in self.nodes_sorted:
if isinstance(node, WeightNode):
node.learning_rate = learning_rate2.10 拓撲排序
實現拓撲排序,將節點按照更新順序排列。
def topological_sort(self, input_nodes):
nodes_sorted = []
que = copy(input_nodes)
unique = set()
while que:
node = que.pop(0)
nodes_sorted.append(node)
unique.add(node)
for outbound_node in node.outbound_nodes:
if all(x in unique for x in outbound_node.inbound_nodes):
que.append(outbound_node)
self.nodes_sorted = nodes_sorted2.11 前向傳播和反向傳播
def forward(self):
assert self.nodes_sorted is not None, "nodes_sorted is empty!"
for node in self.nodes_sorted:
node.forward()
def backward(self):
assert self.nodes_sorted is not None, "nodes_sorted is empty!"
for node in self.nodes_sorted[::-1]:
node.backward()
def forward_and_backward(self):
self.forward()
self.backward()2.12 建立全連接神經網絡
def build_network(self, data: ndarray, label: ndarray, n_hidden: int, n_feature: int):
weight_node1 = WeightNode(shape=(n_feature, n_hidden), name="W1")
bias_node1 = WeightNode(shape=n_hidden, name="b1")
weight_node2 = WeightNode(shape=(n_hidden, 1), name="W2")
bias_node2 = WeightNode(shape=1, name="b2")
self.data = InputNode(data, name="X")
self.label = InputNode(label, name="y")
linear_node1 = LinearNode(
self.data, weight_node1, bias_node1, name="l1")
sigmoid_node1 = SigmoidNode(linear_node1, name="s1")
self.prediction = LinearNode(
sigmoid_node1, weight_node2, bias_node2, name="prediction")
MseNode(self.label, self.prediction, name="mse")
input_nodes = [weight_node1, bias_node1,
weight_node2, bias_node2, self.data, self.label]
self.topological_sort(input_nodes)2.13 訓練模型
使用隨機梯度下降訓練模型。
def train_network(self, epochs: int, n_sample: int, batch_size: int, random_state: int):
steps_per_epoch = n_sample // batch_size
for i in range(epochs):
loss = 0
for _ in range(steps_per_epoch):
indexes = choice(n_sample, batch_size, replace=True)
self.data.indexes = indexes
self.label.indexes = indexes
self.forward_and_backward()
loss += self.nodes_sorted[-1].value
print("Epoch: {}, Loss: {:.3f}".format(i + 1, loss / steps_per_epoch))
print()2.14 移除無用節點
模型訓練結束後,將mse和label節點移除。
def pop_unused_nodes(self):
for _ in range(len(self.nodes_sorted)):
node = self.nodes_sorted.pop(0)
if node.name in ("mse", "y"):
continue
self.nodes_sorted.append(node)2.15 訓練模型
def fit(self, data: ndarray, label: ndarray, n_hidden: int, epochs: int,
batch_size: int, learning_rate: float):
label = label.reshape(-1, 1)
n_sample, n_feature = data.shape
self.build_network(data, label, n_hidden, n_feature)
self.learning_rate = learning_rate
print("Total number of samples = {}".format(n_sample))
self.train_network(epochs, n_sample, batch_size)
self.pop_unused_nodes()2.16 預測多個樣本
def predict(self, data: ndarray) -> ndarray:
self.data.value = data
self.data.indexes = range(data.shape[0])
self.forward()
return self.prediction.value.flatten()3 效果評估
3.1 main函數
使用著名的波士頓房價數據集,按照7:3的比例拆分為訓練集和測試集,訓練模型,並統計准確度。
@run_time
def main():
print("Tesing the performance of MLP....")
data, label = load_boston_house_prices()
data = min_max_scale(data)
data_train, data_test, label_train, label_test = train_test_split(
data, label, random_state=20)
reg = MLP()
reg.fit(data=data_train, label=label_train, n_hidden=8,
epochs=1000, batch_size=8, learning_rate=0.0008)
get_r2(reg, data_test, label_test)
print(reg)3.2 效果展示
擬合優度0.803,運行時間6.9秒。
效果還算不錯~
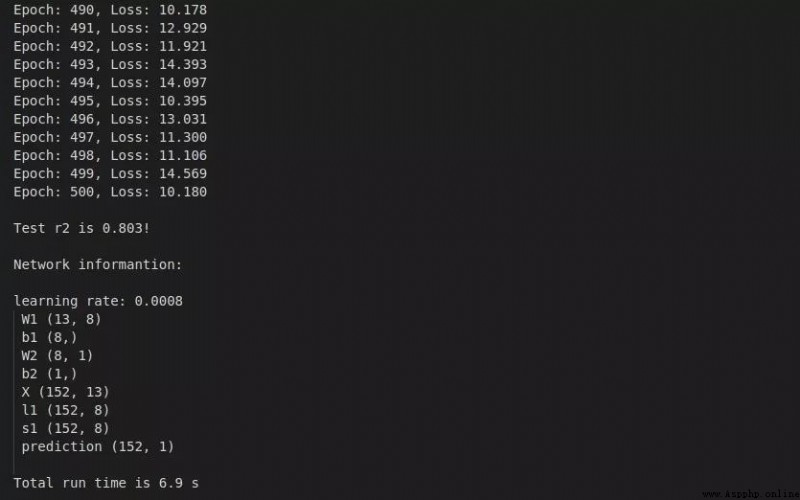
3.3 工具函數
本人自定義了一些工具函數,可以在github上查看
https://github.com/tushushu/imylu/tree/master/imylu/utils1、run_time - 測試函數運行時間
2、load_boston_house_prices - 加載波士頓房價數據
3、train_test_split - 拆分訓練集、測試集
4、get_r2 - 計算擬合優度
總結
矩陣乘法
鏈式求導
拓撲排序
梯度下降
好消息!
小白學視覺知識星球
開始面向外開放啦

下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號後台回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。
下載2:Python視覺實戰項目52講
在「小白學視覺」公眾號後台回復:Python視覺實戰項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰項目,助力快速學校計算機視覺。
下載3:OpenCV實戰項目20講
在「小白學視覺」公眾號後台回復:OpenCV實戰項目20講,即可下載含有20個基於OpenCV實現20個實戰項目,實現OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫學影像、GAN、算法競賽等微信群(以後會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功後會根據研究方向邀請進入相關微信群。請勿在群內發送廣告,否則會請出群,謝謝理解~