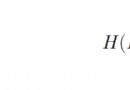活動地址:CSDN21天學習挑戰賽
想必字符串大家肯定都知道吧?在 Python 裡我們常常需要對字符串進行操作,而在字符串對象本身就有許多內置的方法,大多數只需要對字符串簡單處理的情況下,這些方法就已經足夠了,比如 split、join、strip、lstrip、rstrip 和 replace 等等。然鵝,這些都只是對字符串處理的普通操作,真正強大的高級操作是正則表達式!又正好,Python有一個內置的正則表達式模塊,它就是 re 模塊!
【個人建議:想要靈活掌握re模塊,建議在稍稍了解正則表達式語法的基礎上(不必完全記住,因為一開始不好理解),再學習 re 模塊的函數及類。在看re模塊的代碼示例時遇到不懂的語法規則,可以再回頭看看正則表達式的語法,這樣方便理解和掌握】
正則表達式,又稱規則表達式,(Regular Expression,在代碼中常簡寫為regex、regexp或RE),是一種文本模式,包括普通字符(例如,a 到 z 之間的字母)和特殊字符(稱為"元字符"),是計算機科學的一個概念。正則表達式使用單個字符串來描述、匹配一系列匹配某個句法規則的字符串,通常被用來檢索、替換那些符合某個模式(規則)的文本。
———— 百度百科
【注:下面的 RE(Regular Expression) 表示某個具體的正則表達式】
元字符描述^該元字符在方括號外表示匹配字符串的開頭,用於改變匹配起始位置
在方括號內表示對方括號內的內容“取非”,如 [^0-9] 表示匹配單個非數字字符
$該元字符放在正則表達式末尾位置表示匹配字符串的末尾,用於改變匹配起始位置.匹配除換行符(\n)以外的任意單個字符,加上 S 修飾符(見修飾符部分)後可匹配任意單個字符?該修飾符用於其它修飾符後面,表示匹配模式為非貪婪的|可以認為是二目運算符,代表或者的含義,如 a|b 匹配字符 a 或者字符 b
不用圓括號進行分組時會影響整個正則表達式,如 a|bcd 匹配單個字符 a 或者字符串 bcd
[ ]只匹配滿足方括號內正則表達式的單個字符,如 [abc] 只匹配字符 a 或字符 b 或字符 c( )將滿足圓括號內的正則表達式的字符串劃分為一個組(group),便於分組分類RE*匹配任意個連續的 RERE+匹配1個或多個連續的 RERE?匹配 0 個或 1 個 RE,非貪婪方式(見示例說明部分)RE{n}匹配 n 個連續的 RERE{n,m}匹配 n 個到 m 個連續的 RE,省略 m(即 RE{n,} )則表示匹配 n 個及 n 個以上(無具體上限)、連續的 RE(?flags:RE)flags 代表修飾符,可在圓括號中(該分組)使用 i、m、x 等可選標志(必須小寫),而不影響其它部分(?-flags:RE)flags 代表修飾符,可在圓括號中(該分組)取消使用 i、m、x 等可選標志(必須小寫),而不影響其它部分(?#note)note 表示注釋的內容,整個(?#note)代表注釋,不影響匹配,只起解釋說明作用(?:RE)按順序命名組時,忽略該組(即,一般非捕獲分組),匹配結果包含 RE(?=RE)正向肯定預查(look ahead positive assert),匹配需滿足 RE 正則表達式條件
匹配結果不包含 RE,且預查不消耗字符,下次匹配仍從 RE 開始
(?!RE)正向否定預查(look ahead negative assert),匹配需不滿足 RE 正則表達式條件
匹配結果不包含 RE,且預查不消耗字符,下次匹配仍從 RE 開始
\w匹配單個的單詞字符
其中單詞字符是指數字字符、字母字符(不區分大小寫)及下劃線字符
\W匹配單個的非單詞字符\s匹配單個空白字符,空白字符包括空格、換行符\n、橫向制表符\t、\r、換頁符\f 等\S匹配單個非空白字符\d匹配單個數字字符\D匹配單個非數字字符\b匹配單詞字符串的邊界,指單詞字符串貼著非單詞字符的部分
如 on\b 可以匹配 Python 中的 on,但不能匹配 cone 中的 on
\B匹配非單詞字符串邊界\Z放於正則表達式末尾,匹配字符串是否結束\A放於正則表達式起始,匹配字符串是否開始\n等匹配單個換行符,類似的還有 \t、\r、\f 等\num引用前面已經劃分好的組,num 為一個正整數,代表組號[A-B]
或 [A-BC-D] 等
匹配單個字符,字符在 ASCII 字符集中的對應碼位於字符 A 到字符 B 之間(包括 A 與 B)
如:[0-9] 匹配單個數字;[a-z] 匹配單個小寫字母;[[email protected]] 匹配標點符號及數字;
[a-zA-Z] 匹配單個字母字符;[!-/:[email protected]] 匹配標點符號;注:[a-Z] 會報錯!
正則表達式可以包含一些可選標志修飾符來控制匹配的模式。修飾符被指定為一個可選的標志,可有可無,多個標志可以通過按位或的符號(“|”) 來指定(如:re.M|re.X )。修飾符本身只是一個大寫字母而已,但我們在Python裡平時引入re模塊時習慣用 import re,所以下面的修飾符在用的時候記得在其前面加上 re. 哦!
修飾符描述A(ASCII)根據 ASCII 字符集解析字符,這個標志影響 \w, \W, \b, \B 等I(IGNORECASE)匹配時忽略大小寫,不添加該修飾符時默認對大小寫敏感L(LOCALE)做本地化識別(locale-aware)匹配【】
M(MULTILINE)多行匹配,影響 ^ 和 $,此時它們也以換行符為基准
S(DOTALL)使 . 匹配包括換行符在內的所有字符,不添加該修飾符時默認為不包括換行符
U(UNICODE)根據 Unicode 字符集解析字符,這個標志影響 \w, \W, \b, \B 等X(VERBOSE)忽略正則表達式裡的空格和注釋,該標志通過給予你更靈活的格式以便你將正則表達式寫得更易於理解
T(TEMPLATE)禁用回溯(實驗性的,不推薦使用)
DEBUG
編譯後轉儲模式(實驗性的,不推薦使用)Python 自1.5版本起增加了re 模塊,它提供 Perl 風格的正則表達式模式。re 模塊使 Python 語言擁有全部的正則表達式功能。compile 函數根據一個模式字符串和可選的標志參數生成一個正則表達式對象。該對象擁有一系列方法用於正則表達式匹配和替換。re 模塊也提供了與這些方法功能完全一致的函數,這些函數使用一個模式字符串做為它們的第一個參數。
———— 菜鳥教程
error(msg: str, pattern: str | bytes | None = ..., pos: int | None = ...)re 模塊所有異常的公共基類,一般用不到
匹配類,相當於匹配結果
【方法 group】無參數時返回匹配的字符串,若有參數,返回名為參數的分組的字符串
【方法 groups】無參數,返回一個包含所有分組字符串的元組
【方法 groupdict】無參數,類似於方法 groups,但返回一個字典
【方法 start】用於獲取分組匹配的子串在整個字符串中的起始位置(子串第一個字符的索引),參數默認值為 0
【方法 end】用於獲取分組匹配的子串在整個字符串中的結束位置(子串最後一個字符的索引+1),參數默認值為 0
【方法 span】返回匹配開始與結束位置索引的元組(start(group), end(group)),參數為 group,用法類似於上面
【方法 expand】有一個 template 參數,接收字符串類型,返回一個字符串【具體啥用我也不清楚】
匹配模式類,相當於匹配規則,Pattern 類擁有很多類似於後面要講到的函數的方法,但與下面的函數相比,它們又有區別
方法 findall
findall(string: str, pos: int = ..., endpos: int = ...)與 findall 函數相比,findall 方法沒有 pattern 參數和 flags 參數(這倆參數由 compile 函數指定),pos 參數指定字符串的起始位置,默認為 0,endpos 參數指定字符串的結束位置,默認為字符串的長度,返回值一樣,是個列表
方法 finditer
finditer(string: str, pos: int = ..., endpos: int = ...)參數描述與上面的 findall 方法類似,返回值和 finditer 函數的一樣
方法 fullmatch
fullmatch(string: str, pos: int = ..., endpos: int = ...)參數描述與上面的 findall 方法類似,返回值和 fullmatch 函數的一樣
方法 match
match(string: str, pos: int = ..., endpos: int = ...)參數描述與上面的 findall 方法類似,返回值和 match 函數的一樣
方法 search
search(string: str, pos: int = ..., endpos: int = ...)參數描述與上面的 findall 方法類似,返回值和 search 函數的一樣
方法 split
split(string: str, maxsplit: int = ...)沒有 pattern 參數和 flags 參數,其余參數與返回值和 split 函數的一樣
方法 sub
sub(repl: str | (Match[str]), string: str, count: int = ...)沒有 pattern 參數和 flags 參數,其余參數與返回值和 sub 函數的一樣
方法 subn
subn(repl: str | (Match[str]), string: str, count: int = ...)沒有 pattern 參數和 flags 參數,其余參數與返回值和 subn 函數的一樣
正則表達式修飾符類,可選標志參數,包括 A(ASCII)、I(IGNORECASE)、L(LOCALE)、M(MULTILINE)、S(DOTALL)、U(UNICODE)、X(VERBOSE)、T(TEMPLAT)和 DEBUG 等
函數語法
compile(pattern: [email protected], flags: _FlagsType = ...)【參數 pattern】一個正則表達式字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
編譯正則表達式函數,將正則表達式字符串編譯為 Pattern 對象(Pattern[[email protected]]),方便使用該正則表達式
代碼示例
import re
#正則表達式含義:匹配單個非數字的字符
pattern_1 = re.compile(r'[^\d]')
#正則表達式含義:匹配單個數字字符或者單個小寫字母字符
pattern_2 = re.compile(r'[0-9a-z]')
print(pattern_1.match('abc123').group())
#輸出:a
print(pattern_2.search('ABCdef123').group())
#輸出:d
print(pattern_1)
#輸出:re.compile('[^\\d]')函數語法
escape(pattern: [email protected])【參數 pattern】一個正則表達式字符串
函數對字符串中的轉義字符進行還原,返回還原後的字符串
代碼示例
import re
'''
此處不可直接用print輸出,print會將還原後的字符又轉義過去
用__repr__方法轉換為原本的字符串後輸出
不了解字符串類__repr__方法的應先去了解一下
'''
print(re.escape('Python.png').__repr__())
#輸出:'Python\\.png'
print(re.escape('Python\Good').__repr__())
#輸出:'Python\\\\png'
print(r'Python\Good'.__repr__())#見後面【轉義與還原】部分了解更多
#輸出:'Python\\Good'函數語法
findall(pattern: str | Pattern[str], string: str, flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
在 string 中尋找所有滿足正則表達式的匹配結果,並將它們以列表形式返回,若沒有滿足條件的匹配結果,則返回空列表
代碼示例
import re
#正則表達式含義:匹配兩個連續的數字字符
outlist = re.findall('\d{2}','a12b34c56def780')
print(outlist)
#輸出:['12', '34', '56', '78']函數語法
finditer(pattern: str | Pattern[str], string: str, flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
和 findall 函數(見上)類似,唯一的區別是 finditer 函數返回的不是列表,而是一個迭代器(Iterator[Match[str]])
代碼示例
import re
#正則表達式含義:匹配兩個連續的數字字符
outiter = re.finditer('\d{2}','a12b34c56def780')
for i in outiter:
print(i.group())
'''
輸出:
12
34
56
78
'''函數語法
fullmatch(pattern: str | Pattern[str], string: str, flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
與 match 函數類似,但它是完全匹配,即string必須從頭到尾都滿足 pattern 的模式,若滿足則返回匹配結果(Match[str] 對象),否則返回 None
代碼示例
import re
#正則表達式含義:匹配六個連續的非數字字符
Match_Object_1 = re.fullmatch('\D{6}','Python')
#正則表達式含義:匹配六個連續的單詞字符
Match_Object_2 = re.fullmatch('\w{6}','JavaScript')
print(Match_Object_1.group())
#輸出:Python
print(Match_Object_2.group())#沒有完全匹配
#輸出:AttributeError: 'NoneType' object has no attribute 'group'函數語法
match(pattern: str | Pattern[str], string: str, flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
函數直接對 string 的開頭進行匹配,匹配成功就返回匹配結果(Match[str] 對象),否則返回 None
代碼示例
import re
#正則表達式含義:匹配六個連續的非數字字符
Match_Object_1 = re.match('\D{6}','Python')
#正則表達式含義:匹配六個連續的單詞字符
Match_Object_2 = re.match('\w{6}','JavaScript')
print(Match_Object_1.group())
#輸出:Python
print(Match_Object_2.group())
#輸出:JavaSc函數語法
purge()沒有參數
清除正則表達式緩存,re 模塊函數會對已編譯的正則表達式對象進行緩存,在不同的 Python 版本中,緩存中已編譯過的正則表達式對象的數目可能不同,而且沒有文檔記錄,而 purge 函數能夠用於清除這些緩存
代碼示例
import re
#清除緩存
re.purge()#具體啥效果我也不太清楚...函數語法
search(pattern: str | Pattern[str], string: str, flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
函數會從起始字符搜索整個 string,返回第一個滿足正則表達式的匹配結果(Match[str] 對象),否則返回 None
代碼示例
import re
#正則表達式含義:匹配3個連續的小寫字母字符
#修飾符:I(IGNORECASE)忽略大小寫,對大小寫一視同仁
Match_Object_1 = re.search('[a-z]{3}','123_Oh_My_God_456',re.I)
#正則表達式含義:匹配字符串模式:_零個或多個連續單詞字符_
Match_Object_2 = re.search('_\w*_','I_love_Python!')
print(Match_Object_1.group())
#輸出:God
print(Match_Object_2.group())
#輸出:_love_函數語法
split(pattern: str | Pattern[str], string: str, maxsplit: int = ..., flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 string】要匹配的字符串
【參數 maxsplit】最大分割次數,從左往右計數,默認為對象ellipsis,即完全分割
【參數 flags】可選標志,修飾符,默認不進行修飾
與字符串的 split 方法類似,返回分割後的字符串,但分割規則由正則表達式決定,不了解字符串對象 split 方法的應先去了解該方法
代碼示例
import re
#正則表達式含義:匹配任意個連續的數字字符
#最大分割次數為3(切4刀,產生5份)
outlist_1 = re.split('\d*','a1b22c333d4444e',4)
#正則表達式含義:匹配一個或多個連續的數字字符
#最大分割次數為3(切3刀,產生4份)
outlist_2 = re.split('\d+','a1b22c333d4444e',3)
print(outlist_1)
#輸出:['', 'a', '', 'b', 'c333d4444e']
print(outlist_2)
#輸出:['a', 'b', 'c', 'd4444e']函數語法
sub(pattern: str | Pattern[str], repl: str | (Match[str]), string: str, count: int = ..., flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 repl】要替換為的字符串或者函數(函數必須接收一個Match類,並返回一個字符串)
【參數 string】要進行操作的字符串
【參數 count】替換次數,從左往右計數,默認為對象ellipsis,即完全替換,若設為0也將完全替換
【參數 flags】可選標志,修飾符,默認不進行修飾
函數將把 string 中滿足正則表達式的部分替換為 repl(如果repl是字符串),或者按照某種字符串生成規則(repl 為函數),替換為相應的字符串,返回替換後的字符串
代碼示例
import re
#替換為固定的字符串
print(re.sub('\w*','!','123Python'))
#輸出:!!(仔細體會為什麼是兩個感歎號)
def repl(match:re.Match):
#repl替換函數
#接收一個Match類
#返回一個字符串
return str(int(match.group())**2)
#替換為某種字符串(由替換函數決定)
print(re.sub('\d',repl,'123'))
#輸出:149函數語法
subn(pattern: str | Pattern[str], repl: str | (Match[str]), string: str, count: int = ..., flags: _FlagsType = ...)【參數 pattern】正則表達式字符串或者Pattern類
【參數 repl】要替換為的字符串或者函數(函數必須接收一個Match類,並返回一個字符串)
【參數 string】要進行操作的字符串
【參數 count】替換次數,從左往右計數,默認為對象ellipsis,即完全替換,若設為0也將完全替換
【參數 flags】可選標志,修飾符,默認不進行修飾
與 sub 函數類似,但是返回一個元組(tuple[str, int]),為替換後的字符串以及原字符串的總替換次數
代碼示例
import re
#替換為固定的字符串
print(re.subn('\w+','!','123Python'))
#輸出:('!', 1)
def repl(match:re.Match):
#repl替換函數
#接收一個Match類
#返回一個字符串
return str(int(match.group())**2)
#替換為某種字符串(由替換函數決定)
#替換次數:2次
print(re.subn('\d',repl,'123',2))
#輸出:('143', 2)函數語法
template(pattern: [email protected] | Pattern[[email protected]], flags: _FlagsType = ...)【參數 pattern】一個正則表達式字符串
【參數 flags】可選標志,修飾符,默認不進行修飾
和 compile 函數類似,編譯正則表達式函數,將正則表達式字符串編譯為 Pattern 對象(Pattern[[email protected]]),但其返回的 Pattern 對象多了一個修飾符 T(TEMPLATE)
代碼示例
import re
print(re.template('\d'))
#輸出:re.compile('\\d', re.TEMPLATE)
print(re.template('\d').match('123').group())
#輸出:1匹配單個字符的比較簡單,下面這些元字符是用於匹配單個字符的
元字符描述(詳細說明見元字符部分).匹配單個任意字符(除換行符外)[ ]匹配單個方括號內字符\d匹配單個數字字符\D匹配單個非數字字符\w匹配單個單詞字符\W匹配單個非單詞字符\s匹配單個空白字符\S匹配單個非空白字符\n等匹配單個換行符等[A-B]
或 [A-BC-D] 等
匹配單個字符,字符在 ASCII 字符集中的對應碼位於字符 A 到字符 B 之間(包括 A 與 B)import re
#點號元字符
print(re.match('.','\n').group())#點號元字符默認不包含換行符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
print(re.match('.','\n',re.S).group().__repr__())#S修飾符使換行符被包括
#輸出:'\n'
#方括號元字符
print(re.match('[abc]','b').group())#匹配abc任意其一
#輸出:b
print(re.match('[!-/:[email protected]]','?').group())#匹配標點符號
#輸出:?
#\d元字符
print(re.match('\d','666').group())#匹配數字字符
#輸出:6
print(re.match('\D','nb').group())#匹配非數字字符
#輸出:n
#\w元字符
print(re.match('\w','abc').group())#匹配單詞字符
#輸出:a
print(re.match('\W','???').group())#匹配非單詞字符
#輸出:?
#\s元字符
print(re.match('\s',' ').group())#匹配空白字符
#輸出:(此處輸出了一個空格)
print(re.match('\S','\n').group())#匹配非空白字符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
#特殊符號元字符(換行符等)
print(re.match('\n','\n').group().__repr__())#匹配換行符
#輸出:'\n'
print(re.match('\t','\t').group().__repr__())#匹配橫向制表符
#輸出:'\t'import re
#問號元字符
print(re.match('What?','what',re.I).group())#匹配wha或者what,對大小寫不敏感
#輸出:what
#加號元字符
print(re.match('2+3','22223').group())#匹配一個或多個2再加上3
#輸出:22223
#星號元字符
print(re.match('[abc]*','cba').group())#匹配任意個a或b或c
#輸出:cba
#花括號元字符
print(re.match('(nb){3,}','NBnbNBnb',re.I).group())#匹配3個及3個以上的字符串nb,對大小寫不敏感
#輸出:NBnbNBnb
#豎線元字符
print(re.match('我去!|牛啊!','牛啊!').group())#匹配“我去!”或者“牛啊!”
#輸出:牛啊!在正則表達式裡面使用圓括號會產生分組,若分組沒有給定確切的組名,那麼就從左往右按順序以數字來命名,如
(123)([456]*)(\s+)上面的正則表達式中就出現了 3 組,分別為 123、[456]* 和 \s+ ,組號就分別為 1、2 和 3,這都是屬於捕獲分組
元字符描述分組類型( )將圓括號裡的內容劃分為一個組捕獲分組(?P<name>)將在 <name> 之後,右圓括號之前的內容劃分為一個組,name 為該分組的組名捕獲分組\num引用前面已經劃分好的組,num 為一個正整數,代表組號——(?P=name)對有確切組名的分組進行引用,引用名為 name——(?:RE)按順序命名組時,忽略該組(即,一般非捕獲分組),匹配結果包含 RE非捕獲分組(?=RE)特別說明
【捕獲分組】分組且匹配,其內容將會被保存,組名按順序以數字命名或者自定義具體組名,後續用命名進行引用
【非捕獲分組】分組且匹配,沒有組名,其內容不會被保存,後續將無法引用該組(或者說不需要用到)
正向肯定預查(look ahead positive assert),匹配需滿足 RE 正則表達式條件
匹配結果不包含 RE,且預查不消耗字符,下次匹配仍從 RE 開始
非捕獲分組(?!RE)正向否定預查(look ahead negative assert),匹配需不滿足 RE 正則表達式條件
匹配結果不包含 RE,且預查不消耗字符,下次匹配仍從 RE 開始
非捕獲分組(?flags:RE)flags 代表修飾符,可在該分組使用 i、m、x 等可選標志(必須小寫),而不影響其它部分非捕獲分組(?-flags:RE)flags 代表修飾符,可在該分組取消使用 i、m、x 等可選標志(必須小寫),而不影響其它部分非捕獲分組import re
#圓括號一般捕獲分組
Match_Onject_1 = re.match('(\d+)([a-z]*)\\2','123abcABC',re.I)#\\2表示引用第2個分組內容(即[a-z]*)
print(Match_Onject_1.group())#沒有參數,表示輸出全部匹配結果
#輸出:123abcABC
print(Match_Onject_1.group(1))#輸出組號為1的分組(第1個分組)
#輸出:123
print(Match_Onject_1.group(2))#輸出組號為2的分組(第2個分組)
#輸出:abc
#自定義組名捕獲分組
Match_Onject_2 = re.match('(?P<First>[abc]{2,3})(?P=First)!','abab!')#自定義分組名為First
print(Match_Onject_2.group())#沒有參數,表示輸出全部匹配結果
#輸出:abab!
print(Match_Onject_2.group('First'))#輸出組名為First的分組
#輸出:ab
#一般非捕獲分組
Match_Onject_3 = re.match('([123]{2})(?:\w)(nb)\\2','22znbnb')#\\2表示第2個分組,為nb(忽略了\w)
print(Match_Onject_3.group())#沒有參數,表示輸出全部匹配結果
#輸出:22znbnb(匹配結果中含有z)
print(Match_Onject_3.group(2))#輸出組號為2的分組(第2個分組)
#輸出:nb
#正向肯定預查
print(re.match('[Pp]ython(?=3\\.\d{2})','Python3.10').group())#版本號必須是3.\d{2}的形式時才能匹配
#輸出:Python(匹配結果中不含3.10)
#正向否定預查
print(re.match('[Pp]ython(?!3\\.[0-9]{2})','python2.7').group())#版本號不是3.\d{2}的形式時才能匹配
#輸出:python(匹配結果中不含2.7)
#分組內不區分大小寫
print(re.match('(?i:p)p','Pp').group())
#輸出:Pp
#分組內點號元字符不匹配換行符
print(re.match('(?-s:.).','\n\n',re.S).group().__repr__())
#輸出:AttributeError: 'NoneType' object has no attribute 'group'用於改變或檢測匹配位置的元字符有下面四種
元字符描述^該元字符放在正則表達式起始位置表示匹配字符串的開頭,用於改變匹配起始位置
可以理解為:^ 所在的位置必須是匹配起始處(空字符)
$該元字符放在正則表達式末尾位置表示匹配字符串的末尾,用於改變匹配結束位置
可以理解為:$ 所在的位置必須是匹配結尾處(空字符)
\A類似於 ^,放於正則表達式起始,匹配字符串是否開始\Z類似於 $,放於正則表達式末尾,匹配字符串是否結束import re
#匹配Python源文件的文件名
#不會檢測文件名開頭是否符合一些要求
print(re.search('\w*\.py','#Hello_World.pyi').group())
#輸出:Hello_World.py
#利用 $ 判斷結尾是否符合要求
print(re.search('\w*\.py$','Hello_World.pyi').group())#字符串末尾多了個i,而不是空字符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
#利用 ^ 判斷起始是否符合要求
print(re.search('^\w*\.py','#Hello_World.py').group())#字符串開頭多了個#,而不是空字符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
#利用 \Z 判斷結尾是否符合要求
print(re.search('\w*\.py\Z','Hello_World.pyi').group())#字符串末尾多了個i,而不是空字符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
#利用 \A 判斷起始是否符合要求
print(re.search('\A\w*\.py','#Hello_World.py').group())#字符串開頭多了個#,而不是空字符
#輸出:AttributeError: 'NoneType' object has no attribute 'group'Python語言默認是貪婪的,意思就是說,總是嘗試匹配盡可能多的字符,反之,非貪婪就是嘗試匹配盡可能少的字符
在元字符 *、?、+ 及 {} 後面加上一個 ? 來指定它們為非貪婪模式
import re
#正則表達式含義:匹配一個或多個數字字符,貪婪模式,盡可能多
Match_Object_1 = re.match('\d+','123')
#正則表達式含義:匹配一個或多個數字字符,非貪婪模式,盡可能少
Match_Object_2 = re.match('\d+?','123')
print(Match_Object_1.group())
#輸出:123
print(Match_Object_2.group())
#輸出:1在python裡,字符的轉義是由反斜槓 \ 實現的,如換行符 \n、橫向制表符 \t 等等,但我們有時候並不想要它們轉義的含義,而是想要它們原本的含義,即原生字符串,這個時候就有兩種做法了
溫馨提示:print 函數打印字符串的結果是轉義後的結果,若想要原生字符串,請調用 __repr__ 方法後再用 print 輸出
把轉義用的反斜槓給還原,這樣就不會產生轉義字符了,也就實現了還原的目的,具體操作就是在反斜槓前再加上一個反斜槓
'\n' ————> '\\n'
'\t' ————> '\\t'但這樣不能高效地解決問題,如果轉義字符很多就比較麻煩,或者比如你要匹配單個的反斜槓文本字符 \,那麼你要先將其在正則表達式語法格式中還原為 \\,在再字符串語法中將其還原為 \\\\,極其的麻煩,於是就有了第二種操作
在字符串前面加上一個小寫的 r 字母,其含義應該是 raw 的縮寫,也可能是 repr 的縮寫?(個人猜測),可以將操作的字符串中的轉義字符還原為普通字符
'\n' ————> r'\n'
'\t' ————> r'\t'將美國格式的日期(2/8/2022)改為中國格式(2022/8/2)
import re
print(re.sub('(\d+)/(\d+)/(\d+)','\\3/\\2/\\1','2/8/2022'))
#輸出:2022/8/2
print(re.sub('(\d+)/(\d+)/(\d+)',r'\3/\2/\1','2/8/2022'))
#輸出:2022/8/2任意給一段字符串,判斷其是否能作為一個變量名
import re
print(re.fullmatch('[^\d]+\w+','_name_').group())
#輸出:_name_
print(re.fullmatch('[^\d]+\w+','What_Fuc*!!!').group())
#輸出:AttributeError: 'NoneType' object has no attribute 'group'
print(re.fullmatch('[^\d]+\w+','123Yeah').group())
#輸出:AttributeError: 'NoneType' object has no attribute 'group'給定一個地址,匹配其是否為郵箱地址
import re
print(re.match('\w{4,20}@(126|163|qq)\\.com\Z','[email protected]').group())
#輸出:[email protected]
print(re.match('\w{4,20}@(126|163|qq)\\.com$','[email protected]').group())
#輸出:[email protected]【都看到這裡了,不如給我點個小小的贊吧!】