目錄
前言
一、Feature types
二、Quantitative data feature processing
三.Categorical data feature processing
1.LabelEncoding
2.OneHot Encoding
優點:
缺點:
應用場景:
無用場景:
代碼實現
編輯
方法二:
編輯
點關注,防走丟,如有纰漏之處,請留言指教,非常感謝
參閱:
When we start preparing for data modeling、When building machine learning models,The first consideration should not be to consider the type and method of selecting the model.But first get feature data and label data for research,Mining the information contained in feature data and thinking about how to better process these feature data.Then the meaning of the data type itself requires us to think about it,Whether fixed quantitative calculation is a kind of analysis is better?This is what this article is going to break down a problem.
Feature type judgment and processing is an important part of early feature engineering,It is also the most important part of determining the quality of features and weighing information loss..The data involved are of numeric type.,例如:年齡、體重、Characteristics such as height.Also has a character type characteristics of the data,例如性別、社會階層、血型、State ownership and other data.
According to the data format of data storage, it can be divided into two categories:
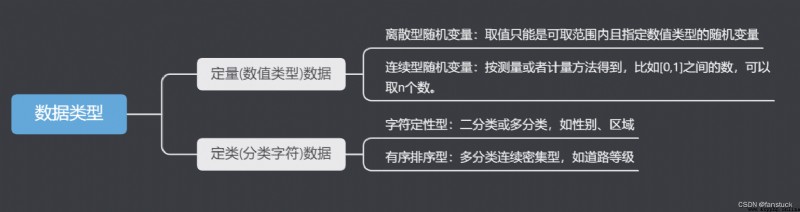
According to the meaning of characteristic data, it can be divided into:
拿到獲取的原始特征,必須對每一特征分別進行歸一化,比如,特征A的取值范圍是[-1000,1000],特征B的取值范圍是[-1,1].如果使用logistic回歸,w1*x1+w2*x2,因為x1的取值太大了,所以x2基本起不了作用.所以,必須進行特征的歸一化,每個特征都單獨進行歸一化.
Regarding working with quantitative data I have:數據預處理歸一化詳細解釋This article describes in great detail,Are there before and after the link,共有min-max標准化、Z-score標准化、SigmoidThree methods of function normalization:
Select the processing method according to the type of feature data meaning:
我的上篇文章數據預處理歸一化詳細解釋 There is no introduction to how we deal with categorical data,In this article, some commonly used processing methods are introduced in detail:
The direct replacement method is suitable for situations where there is only a small amount of data in the original data set that needs to be adjusted manually.If the amount of data to be adjusted is very large and the data format is not uniform,The direct replacement method can also achieve our purpose,But this approach requires workload will be very big.因此, We need a way to quickly encode all the values of an entire column of variables.
LabelEncoding,tag encoding,role is variable n assign a unique value[0, n-1]之間的編碼,Convert the variable to a continuous numeric variable.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(['擁堵','緩行','暢行'])
le.transform(['擁堵','擁堵','暢行','緩行'])array([0, 0, 1, 2])
For processing categorical data, it is easy to think of replacing all the data in this category with numerical values:such as traffic congestion,We label congestion as1,Slow behavior2,smooth behavior3.Then this is the implementation of tag encoding,But at the same time, it also converts these dimensionless data into dimensioned data.,We did not intend to compare them.Machines may learn“擁堵<緩行<暢行”,So with this tag coding is not enough,需要進一步轉換.Because there are three intervals,So there are three bits,That is, the congestion code is100,Slow behavior010,smooth behavior001.如此一來每兩個向量之間的距離都是根號2,在向量空間距離都相等,所以這樣不會出現偏序性,基本不會影響基於向量空間度量算法的效果.
自然狀態碼為:000,001,010,011,100,101
獨熱編碼為:000001,000010,000100,001000,010000,100000
我們可以使用sklearn的onehotencoder來實現:
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 1], [0, 1, 0], [1, 0, 0]]) # fit來學習編碼
enc.transform([[0, 0, 1]]).toarray() # 進行編碼array([[1., 0., 1., 0., 0., 1.]])
數據矩陣是3*3的,So how did the principle come about??我們仔細觀察:

The first feature dimension of the first column has two values0/1,所以對應的編碼方式為10、01.
The same is true for the second feature of the second column,The third brother characteristics of analogy in the third column.固001The one-hot encoding of101001了.
Because most algorithms are based on metrics in vector spaces,為了使非偏序關系的變量取值不具有偏序性,並且到圓點是等距的.使用one-hot編碼,將離散特征的取值擴展到了歐式空間,離散特征的某個取值就對應歐式空間的某個點.將離散型特征使用one-hot編碼,會讓特征之間的距離計算更加合理.離散特征進行one-hot編碼後,編碼後的特征,其實每一維度的特征都可以看做是連續的特征.就可以跟對連續型特征的歸一化方法一樣,對每一維特征進行歸一化.比如歸一化到[-1,1]或歸一化到均值為0,方差為1.
將離散特征通過one-hot編碼映射到歐式空間,是因為,在回歸,分類,聚類等機器學習算法中,特征之間距離的計算或相似度的計算是非常重要的,而我們常用的距離或相似度的計算都是在歐式空間的相似度計算,計算余弦相似性,基於的就是歐式空間.
獨熱編碼解決了分類器不好處理屬性數據的問題,在一定程度上也起到了擴充特征的作用.它的值只有0和1,不同的類型存儲在垂直的空間.
當類別的數量很多時,特征空間會變得非常大.在這種情況下,一般可以用PCA來減少維度.而且one hot encoding+PCA這種組合在實際中也非常有用.
獨熱編碼用來解決類別型數據的離散值問題.
將離散型特征進行one-hot編碼的作用,是為了讓距離計算更合理,但如果特征是離散的,並且不用one-hot編碼就可以很合理的計算出距離,那麼就沒必要進行one-hot編碼. 有些基於樹的算法在處理變量時,並不是基於向量空間度量,數值只是個類別符號,即沒有偏序關系,所以不用進行獨熱編碼. Tree Model不太需要one-hot編碼: 對於決策樹來說,one-hot的本質是增加樹的深度.
方法一:
實現one-hotThere are two ways to encode:sklearn庫中的 OneHotEncoder() Methods can only handle numeric variablesIf it is character data,need to use it first LabelEncoder() 轉換為數值數據,再使用 OneHotEncoder() One-hot encoding,And you need to delete the original variables for one-hot encoding processing in the original data set by yourself.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
lE = LabelEncoder()
df=pd.DataFrame({'路況':['擁堵','暢行','暢行','擁堵','暢行','緩行','緩行','擁堵','緩行','擁堵','擁堵','擁堵']})
df['路況']=lE.fit_transform(df['路況'])
OHE = OneHotEncoder()
X = OHE.fit_transform(df).toarray()
df = pd.concat([df, pd.DataFrame(X, columns=['擁堵', '緩行','暢行'])],axis=1)
df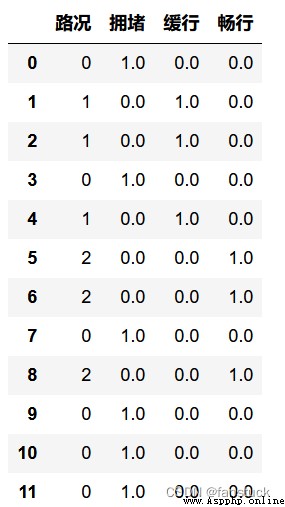
pandas自帶get_dummies()方法
get_dummies() Methods can handle numeric data and character data,The method can be directly applied to the original dataset.This method produces a newDataframe,The column name is extended from the original variable.When merging it into the original dataset,You need to delete the original variables for dummy variable processing in the original data set by yourself.
import pandas as pd
df=pd.DataFrame({'路況':['擁堵','暢行','暢行','擁堵','暢行','緩行','緩行','擁堵','緩行','擁堵','擁堵','擁堵']})
pd.get_dummies(df,drop_first=False) 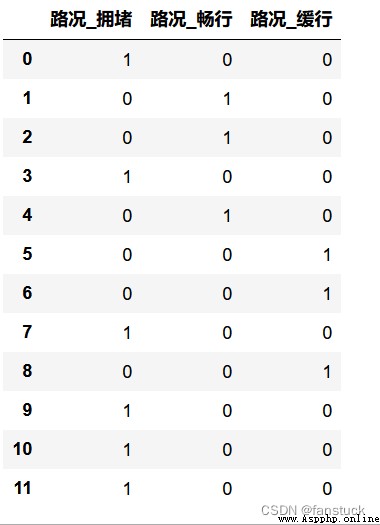
以上就是本期全部內容.我是fanstuck ,有問題大家隨時留言討論 ,我們下期見.
數據挖掘OneHotEncoder獨熱編碼和LabelEncoder標簽編碼
Preprocessing methods for categorical data