雷猴啊,兄弟們!今天來展示一下如何用Python快速實現一個線程池。
當有多個 IO 密集型的任務要被處理時,我們自然而然會想到多線程。但如果任務非常多,我們不可能每一個任務都啟動一個線程去處理,這個時候最好的辦法就是實現一個線程池,至於池子裡面的線程數量可以根據業務場景進行設置。
比如我們實現一個有 10 個線程的線程池,這樣可以並發地處理 10 個任務,每個線程將任務執行完之後,便去執行下一個任務。通過使用線程池,可以避免因線程創建過多而導致資源耗盡,而且任務在執行時的生命周期也可以很好地把控。
而線程池的實現方式也很簡單,但這裡我們不打算手動實現,因為 Python 提供了一個標准庫 concurrent.futures,已經內置了對線程池的支持。所以本篇文章,我們就來詳細介紹一下該模塊的用法。
當我們往線程池裡面提交一個函數時,會分配一個線程去執行,同時立即返回一個 Future 對象。通過 Future 對象可以監控函數的執行狀態,有沒有出現異常,以及有沒有執行完畢等等。如果函數執行完畢,內部便會調用 future.set_result 將返回值設置到 future 裡面,然後外界便可調用 future.result 拿到返回值。
除此之外 future 還可以綁定回調,一旦函數執行完畢,就會以 future 為參數,自動觸發回調。所以 future 被稱為未來對象,可以把它理解為函數的一個容器,當我們往線程池提交一個函數時,會立即創建相應的 future 然後返回。函數的執行狀態什麼的,都通過 future 來查看,當然也可以給它綁定一個回調,在函數執行完畢時自動觸發。
那麼下面我們就來看一下 future 的用法,文字的話理解起來可能有點枯燥。
將函數提交到線程池裡面運行時,會立即返回一個對象
這個對象就叫做 Future 對象,裡面包含了函數的執行狀態等等
當然我們也可以手動創建一個Future對象。
from concurrent.futures import Future
# 創建 Future 對象 future
future = Future()
# 給 future 綁定回調
def callback(f: Future):
print("當set_result的時候會執行回調,result:",
f.result())
future.add_done_callback(callback)
# 通過 add_done_callback 方法即可給 future 綁定回調
# 調用的時候會自動將 future 作為參數
# 如果需要多個參數,那麼就使用偏函數
# 回調函數什麼時候執行呢?
# 顯然是當 future 執行 set_result 的時候
# 如果 future 是向線程池提交函數時返回的
# 那麼當函數執行完畢時會自動執行 future.set_result(xx)
# 並將自身的返回設置進去
# 而這裡的 future 是我們手動創建的,因此需要手動執行
future.set_result("嘿嘿")
當set_result的時候會執行回調,result: 嘿嘿
需要注意的是:只能執行一次 set_result,但是可以多次調用 result 獲取結果。
from concurrent.futures import Future
future = Future()
future.set_result("哼哼")
print(future.result()) # 哼哼
print(future.result()) # 哼哼
print(future.result()) # 哼哼
執行 future.result() 之前一定要先 set_result,否則會一直處於阻塞狀態。當然 result 方法還可以接收一個 timeout 參數,表示超時時間,如果在指定時間內沒有獲取到值就會拋出異常。
我們上面是手動創建的 Future 對象,但工作中很少會手動創建。我們將函數提交到線程池裡面運行的時候,會自動創建 Future 對象並返回。這個 Future 對象裡面就包含了函數的執行狀態,比如此時是處於暫停、運行中還是完成等等,並且函數在執行完畢之後,還會調用 future.set_result 將自身的返回值設置進去。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{
name} 睡了 {
n} 秒"
# 創建一個線程池
# 裡面還可以指定 max_workers 參數,表示最多創建多少個線程
# Python學習交流裙279199867
# 如果不指定,那麼每提交一個函數,都會為其創建一個線程
executor = ThreadPoolExecutor()
# 通過 submit 即可將函數提交到線程池,一旦提交,就會立刻運行
# 因為開啟了一個新的線程,主線程會繼續往下執行
# 至於 submit 的參數,按照函數名,對應參數提交即可
# 切記不可寫成task("古明地覺", 3),這樣就變成調用了
future = executor.submit(task, "屏幕前的你", 3)
# 由於函數裡面出現了 time.sleep,並且指定的 n 是 3
# 所以函數內部會休眠 3 秒,顯然此時處於運行狀態
print(future)
""" <Future at 0x7fbf701726d0 state=running> """
# 我們說 future 相當於一個容器,包含了內部函數的執行狀態
# 函數是否正在運行中
print(future.running())
""" True """
# 函數是否執行完畢
print(future.done())
""" False """
# 主程序也 sleep 3 秒
time.sleep(3)
# 顯然此時函數已經執行完畢了
# 並且打印結果還告訴我們返回值類型是 str
print(future)
""" <Future at 0x7fbf701726d0 state=finished returned str> """
print(future.running())
""" False """
print(future.done())
""" True """
# 函數執行完畢時,會將返回值設置在 future 裡
# 也就是說一旦執行了 future.set_result
# 那麼就表示函數執行完畢了,然後外界可以調用 result 拿到返回值
print(future.result())
""" 屏幕前的你 睡了 3 秒 """
這裡再強調一下 future.result(),這一步是會阻塞的,舉個例子:
# 提交函數
future = executor.submit(task, "屏幕前的你", 3)
start = time.perf_counter()
future.result()
end = time.perf_counter()
print(end - start) # 3.00331525
可以看到,future.result() 這一步花了將近 3s。其實也不難理解,future.result() 是干嘛的?就是為了獲取函數的返回值,可函數都還沒有執行完畢,它又從哪裡獲取呢?所以只能先等待函數執行完畢,將返回值通過 set_result 設置到 future 裡面之後,外界才能調用 future.result() 獲取到值。
如果不想一直等待的話,那麼在獲取值的時候可以傳入一個超時時間。
from concurrent.futures import (
ThreadPoolExecutor,
TimeoutError
)
import time
def task(name, n):
time.sleep(n)
return f"{
name} 睡了 {
n} 秒"
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
try:
# 1 秒之內獲取不到值,拋出 TimeoutError
res = future.result(1)
except TimeoutError:
pass
# 再 sleep 2 秒,顯然函數執行完畢了
time.sleep(2)
# 獲取返回值
print(future.result())
""" 屏幕前的你 睡了 3 秒 """
當然啦,這麼做其實還不夠智能,因為我們不知道函數什麼時候執行完畢。所以最好的辦法還是綁定一個回調,當函數執行完畢時,自動觸發回調。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{
name} 睡了 {
n} 秒"
def callback(f):
print(f.result())
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
# 綁定回調,3 秒之後自動調用
future.add_done_callback(callback)
""" 屏幕前的你 睡了 3 秒 """
需要注意的是,在調用 submit 方法之後,提交到線程池的函數就已經開始執行了。而不管函數有沒有執行完畢,我們都可以給對應的 future 綁定回調。
如果函數完成之前添加回調,那麼會在函數完成後觸發回調。如果函數完成之後添加回調,由於函數已經完成,代表此時的 future 已經有值了,或者說已經 set_result 了,那麼會立即觸發回調。
當函數執行完畢之後,會執行 set_result,那麼這個方法到底干了什麼事情呢?
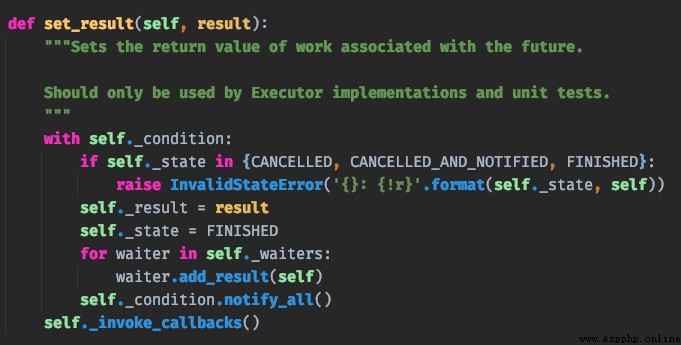
我們看到 future 有兩個被保護的屬性,分別是 _result 和 _state。顯然 _result 用於保存函數的返回值,而 future.result() 本質上也是返回 _result 屬性的值。而 _state 屬性則用於表示函數的執行狀態,初始為 PENDING,執行中為 RUNING,執行完畢時被設置為 FINISHED。
調用 future.result() 的時候,會判斷 _state 的屬性,如果還在執行中就一直等待。當 _state 為 FINISHED 的時候,就返回 _result 屬性的值。
我們上面每次只提交了一個函數,但其實可以提交任意多個,我們來看一下:
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{
name} 睡了 {
n} 秒"
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 4),
executor.submit(task, "屏幕前的你", 1)]
# 此時都處於running
print(futures)
""" [<Future at 0x1b5ff622550 state=running>, <Future at 0x1b5ff63ca60 state=running>, <Future at 0x1b5ff63cdf0 state=running>] """
time.sleep(3)
# 主程序 sleep 3s 後
# futures[0]和futures[2]處於 finished
# futures[1]仍處於 running
print(futures)
""" [<Future at 0x1b5ff622550 state=running>, <Future at 0x1b5ff63ca60 state=running>, <Future at 0x1b5ff63cdf0 state=finished returned str>] """
如果是多個函數,要如何拿到返回值呢?很簡單,遍歷 futures 即可。
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 5),
executor.submit(task, "屏幕前的你", 2),
executor.submit(task, "屏幕前的你", 4),
executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 6)]
for future in futures:
print(future.result())
""" 屏幕前的你 睡了 5 秒 屏幕前的你 睡了 2 秒 屏幕前的你 睡了 4 秒 屏幕前的你 睡了 3 秒 屏幕前的你 睡了 6 秒 """
這裡面有一些值得說一說的地方,首先 futures 裡面有 5 個 future,記做 future1, future2, future3, future4, future5。
當使用 for 循環遍歷的時候,實際上會依次遍歷這 5 個 future,所以返回值的順序就是我們添加的函數的順序。由於 future1 對應的函數休眠了 5s,那麼必須等到 5s 後,future1 裡面才會有值。
但這五個函數是並發執行的,future2, future3, future4 由於只休眠了 2s, 4s, 3s,所以肯定會先執行完畢,然後執行 set_result,將返回值設置到對應的 future 裡。
但 Python 的 for 循環不可能在第一次迭代還沒有結束,就去執行第二次迭代。因為 futures 裡面的幾個 future 的順序已經一開始就被定好了,只有當第一個 future.result() 執行完成之後,才會執行第二個 future.result(),以及第三個、第四個。
因此即便後面的函數已經執行完畢,但由於 for 循環的順序,也只能等著,直到前面的 future.result() 執行完畢。所以當第一個 future.result() 結束時,後面三個 future.result() 會立刻輸出,因為它們內部的函數已經執行結束了。
而最後一個 future,由於內部函數 sleep 了 6 秒,因此要再等待 1 秒,才會打印 future.result()。
使用 submit 提交函數會返回一個 future,並且還可以給 future 綁定一個回調。但如果不關心回調的話,那麼還可以使用 map 進行提交。
executor = ThreadPoolExecutor()
# map 內部也是使用了 submit
results = executor.map(task,
["屏幕前的你"] * 3,
[3, 1, 2])
# 並且返回的是迭代器
print(results)
""" <generator object ... at 0x0000022D78EFA970> """
# 此時遍歷得到的是不再是 future
# 而是 future.result()
for result in results:
print(result)
""" 屏幕前的你 睡了 3 秒 屏幕前的你 睡了 1 秒 屏幕前的你 睡了 2 秒 """
可以看到,當使用for循環的時候,map 執行的邏輯和 submit 是一樣的。唯一的區別是,此時不需要再調用 result 了,因為返回的就是函數的返回值。
或者我們直接調用 list 也行。
executor = ThreadPoolExecutor()
results = executor.map(task,
["屏幕前的你"] * 3,
[3, 1, 2])
print(list(results))
""" ['屏幕前的你 睡了 3 秒', '屏幕前的你 睡了 1 秒', '屏幕前的你 睡了 2 秒'] """
results 是一個生成器,調用 list 的時候會將裡面的值全部產出。由於 map 內部還是使用的 submit,然後通過 future.result() 拿到返回值,而耗時最長的函數需要 3 秒,因此這一步會阻塞 3 秒。3 秒過後,會打印所有函數的返回值。
上面在獲取返回值的時候,是按照函數的提交順序獲取的。如果我希望哪個函數先執行完畢,就先獲取哪個函數的返回值,該怎麼做呢?
from concurrent.futures import (
ThreadPoolExecutor,
as_completed
)
import time
def task(name, n):
time.sleep(n)
return f"{
name} 睡了 {
n} 秒"
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 5),
executor.submit(task, "屏幕前的你", 2),
executor.submit(task, "屏幕前的你", 1),
executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 4)]
for future in as_completed(futures):
print(future.result())
""" 屏幕前的你 睡了 1 秒 屏幕前的你 睡了 2 秒 屏幕前的你 睡了 3 秒 屏幕前的你 睡了 4 秒 屏幕前的你 睡了 5 秒 """
此時誰先完成,誰先返回。
我們通過 submit 可以將函數提交到線程池中執行,但如果我們想取消該怎麼辦呢?
executor = ThreadPoolExecutor()
future1 = executor.submit(task, "屏幕前的你", 1)
future2 = executor.submit(task, "屏幕前的你", 2)
future3 = executor.submit(task, "屏幕前的你", 3)
# 取消函數的執行
# 會將 future 的 _state 屬性設置為 CANCELLED
future3.cancel()
# 查看是否被取消
print(future3.cancelled()) # False
問題來了,調用 cancelled 方法的時候,返回的是False,這是為什麼?很簡單,因為函數已經被提交到線程池裡面了,函數已經運行了。而只有在還沒有運行時,取消才會成功。
可這不矛盾了嗎?函數一旦提交就會運行,只有不運行才會取消成功,這怎麼辦?還記得線程池的一個叫做 max_workers 的參數嗎?用來控制線程池內的線程數量,我們可以將最大的線程數設置為2,那麼當第三個函數進去的時候,就不會執行了,而是處於暫停狀態。
executor = ThreadPoolExecutor(max_workers=2)
future1 = executor.submit(task, "屏幕前的你", 1)
future2 = executor.submit(task, "屏幕前的你", 2)
future3 = executor.submit(task, "屏幕前的你", 3)
# 如果池子裡可以創建空閒線程
# 那麼函數一旦提交就會運行,狀態為 RUNNING
print(future1._state) # RUNNING
print(future2._state) # RUNNING
# 但 future3 內部的函數還沒有運行
# 因為池子裡無法創建新的空閒線程了,所以狀態為 PENDING
print(future3._state) # PENDING
# 取消函數的執行,前提是函數沒有運行
# 會將 future 的 _state 屬性設置為 CANCELLED
future3.cancel()
# 查看是否被取消
print(future3.cancelled()) # True
print(future3._state) # CANCELLED
在啟動線程池的時候,肯定是需要設置容量的,不然處理幾千個函數要開啟幾千個線程嗎。另外當函數被取消了,就不可以再調用 future.result() 了,否則的話會拋出 CancelledError。
我們前面的邏輯都是函數正常執行的前提下,但天有不測風雲,如果函數執行時出現異常了該怎麼辦?
from concurrent.futures import ThreadPoolExecutor
def task1():
1 / 0
def task2():
pass
executor = ThreadPoolExecutor(max_workers=2)
future1 = executor.submit(task1)
future2 = executor.submit(task2)
print(future1)
print(future2)
""" <Future at 0x7fe3e00f9e50 state=finished raised ZeroDivisionError> <Future at 0x7fe3e00f9eb0 state=finished returned NoneType> """
# 結果顯示 task1 函數執行出現異常了
# 那麼這個異常要怎麼獲取呢?
print(future1.exception())
print(future1.exception().__class__)
""" division by zero <class 'ZeroDivisionError'> """
# 如果執行沒有出現異常,那麼 exception 方法返回 None
print(future2.exception()) # None
# 注意:如果函數執行出現異常了
# 那麼調用 result 方法會將異常拋出來
future1.result()
""" Traceback (most recent call last): File "...", line 4, in task1 1 / 0 ZeroDivisionError: division by zero """
出現異常時,調用 future.set_exception 將異常設置到 future 裡面,而 future 有一個 _exception 屬性,專門保存設置的異常。當調用 future.exception() 時,也會直接返回 _exception 屬性的值。
假設我們往線程池提交了很多個函數,如果希望提交的函數都執行完畢之後,主程序才能往下執行,該怎麼辦呢?其實方案有很多:
第一種:
from concurrent.futures import ThreadPoolExecutor
import time
def task(n):
time.sleep(n)
return f"sleep {
n}"
executor = ThreadPoolExecutor()
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# 這裡是不會阻塞的
print("start")
# 遍歷所有的 future,並調用其 result 方法
# 這樣就會等到所有的函數都執行完畢之後才會往下走
for future in [future1, future2, future3]:
print(future.result())
print("end")
""" start sleep 5 sleep 2 sleep 4 end """
第二種:
from concurrent.futures import (
ThreadPoolExecutor,
wait
)
import time
def task(n):
time.sleep(n)
return f"sleep {
n}"
executor = ThreadPoolExecutor()
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# return_when 有三個可選參數
# FIRST_COMPLETED:當任意一個任務完成或者取消
# FIRST_EXCEPTION:當任意一個任務出現異常
# 如果都沒出現異常等同於ALL_COMPLETED
# ALL_COMPLETED:所有任務都完成,默認是這個值
fs = wait([future1, future2, future3],
return_when="ALL_COMPLETED")
# 此時返回的fs是DoneAndNotDoneFutures類型的namedtuple
# 裡面有兩個值,一個是done,一個是not_done
print(fs.done)
""" {<Future at 0x1df1400 state=finished returned str>, <Future at 0x2f08e48 state=finished returned str>, <Future at 0x9f7bf60 state=finished returned str>} """
print(fs.not_done)
""" set() """
for f in fs.done:
print(f.result())
""" start sleep 5 sleep 2 sleep 4 end """
第三種:
# 使用上下文管理
with ThreadPoolExecutor() as executor:
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# 所有函數執行完畢(with語句結束)後才會往下執行
第四種:
executor = ThreadPoolExecutor()
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# 所有函數執行結束後,才會往下執行
executor.shutdown()
如果我們需要啟動多線程來執行函數的話,那麼不妨使用線程池。每調用一個函數就從池子裡面取出一個線程,函數執行完畢就將線程放回到池子裡以便其它函數執行。如果池子裡面空了,或者說無法創建新的空閒線程,那麼接下來的函數就只能處於等待狀態了。
最後,concurrent.futures 不僅可以用於實現線程池,還可以用於實現進程池。兩者的 API 是一樣的:
from concurrent.futures import ProcessPoolExecutor
import time
def task(n):
time.sleep(n)
return f"sleep {
n}"
executor = ProcessPoolExecutor()
# Windows 上需要加上這一行
if __name__ == '__main__':
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
executor.shutdown()
print(future1.result())
print(future2.result())
print(future3.result())
""" sleep 5 sleep 2 sleep 4 """
線程池和進程池的 API 是一致的,但工作中很少會創建進程池。
兄弟們今天的分享就到這,債見!