轉載於:2022了你還不會『低代碼』?數據科學也能玩轉Low-Code啦! - 掘金 (juejin.cn)
低代碼開發,顧名思義,指的是軟件開發過程中只需要編寫少量代碼就夠了。與傳統開發方式相比,低代碼大幅減少了編寫代碼的工作量,這使其具備了更快的速度、更短的開發時間與更低的成本。
無代碼 / 低代碼機器學習平台(和庫)的興起,加速了代碼開發速度。借助於這些平台和框架,數據科學家們在繁重的探索研究和大量的編程任務之間,取得更好的平衡。
在本篇內容中,ShowMeAI 給大家總結了最值得學習&使用 Python 低代碼機器學習庫,覆蓋數據科學最熱門的幾大方向——數據分析&簡單挖掘、機器學習、深度學習。
D-Tale 是一個易於使用的低代碼 Python 庫,通過將 Flask 編寫的後端與 React 編寫的前端相結合,與 Jupyter Notebook 無縫集成,可以查看和分析 Pandas 形態的數據,包括 DataFrame、Series、MultiIndex、DatetimeIndex 和 RangeIndex。

D-Tale 是 SAS 到 Python 轉換的產物,最初是基於 SAS 的 perl 腳本包裝器,現在是基於 Pandas 數據結構的輕量級 Web 客戶端。
大家可以在D-Tale的官方 Github 查看它的詳細教程和用法,也可以前往 在線平台 操作體驗。

對於低代碼探索式數據分析任務,AutoViz 是 Python 中另一個不錯的選擇。在功能方面,它只需編寫一行代碼即可使用 AutoViz 完成任何數據集的自動可視化。
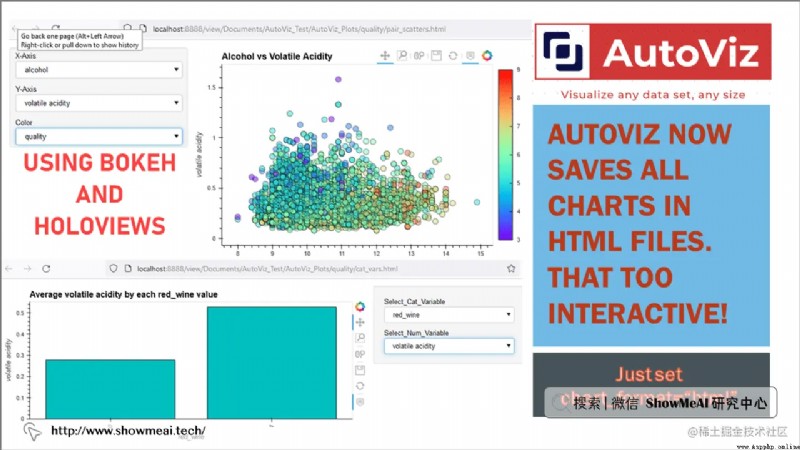
AutoViz 能夠結合任務確定哪些特征是最重要的,然後通過僅使用那些自動選擇的元素來繪制和呈現信息。而且AutoViz速度極快,可視化可以在幾秒鐘內完成。
大家可以查看官方 AutoViz 示例 Jupyter Notebook 進行學習。
Lux 工具庫是一個非常自動的數據分析可視化工具。無需做太多的數據預處理,它會自動根據數據生成一系列候選圖表,根據實際需要從中做選擇即可。這大大減少了制作圖表所需的時間以及數據預處理工作量。

大家可以通過 Lux 的官方 GitHub 頁面了解更多用法細節。
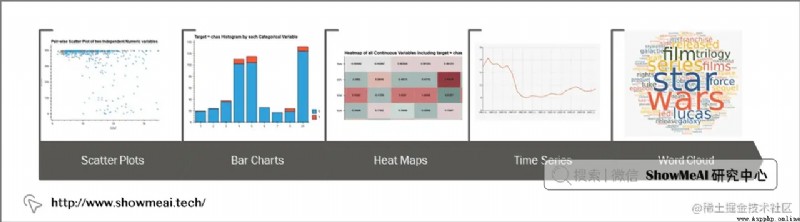
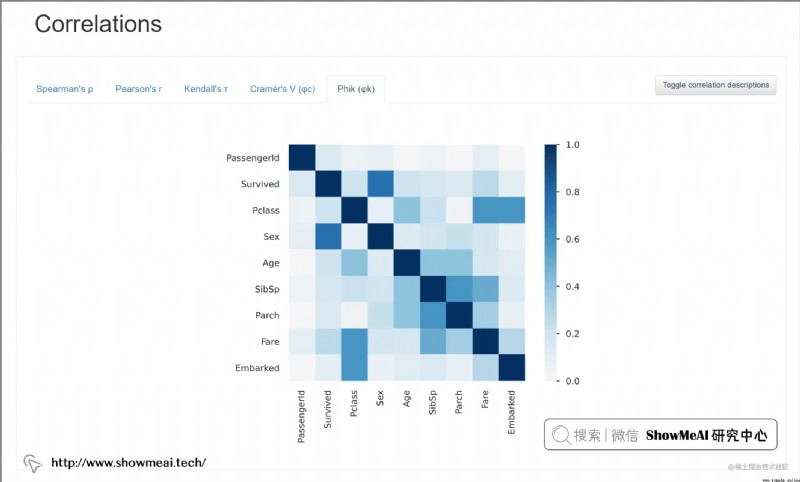
pandas-profiling 庫自動針對 pandas DataFrame 格式的數據生成數據分析報告。

最終的結果以交互式 HTML 報告呈現,包含以下信息:
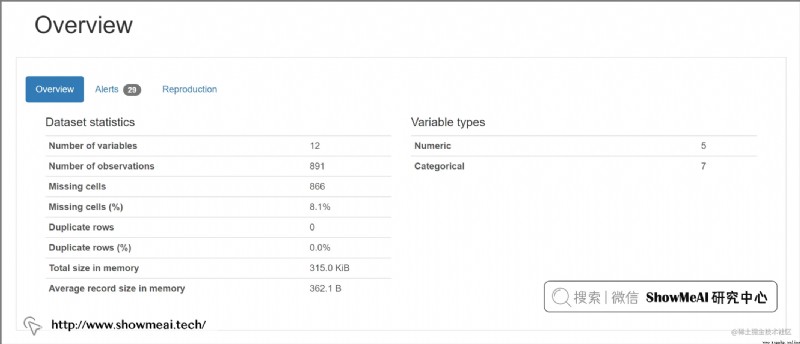
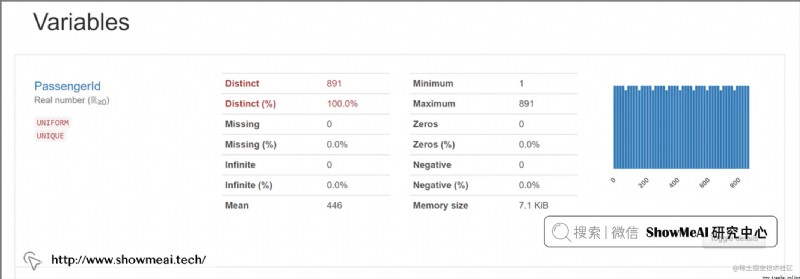
大家可以在 pandas-profiling 的項目 GitHub 頁面獲取詳細使用方法。
PyCaret 是 Python 中的一個開源、低代碼機器學習庫,可自動執行機器學習工作流。它也是一個端到端的機器學習和模型管理工具,可以成倍地加快實驗周期,提升工作開發效率。

與其他開源機器學習庫相比,PyCaret 有著明顯的低代碼特質,可僅用幾行代碼完成原本需要數百行代碼完成的工作,尤其是對於密集的實驗迭代過程可以大大提速。PyCaret 本質上是圍繞多個機器學習庫和框架封裝而成,包括大家熟悉的 Scikit-Learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt 和 Ray 等。
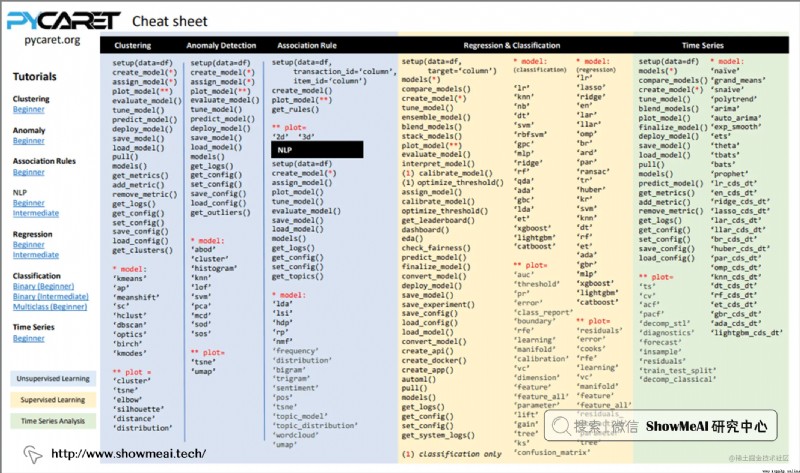
大家可以通過 Pycaret 的 官方文檔,官方GitHub,官方教程 了解更多使用細節。
PyTorch Lightning 是一個應用在深度學習/神經網絡的 Python 低代碼庫,為 PyTorch 提供高級接口。

它具備高性能和輕量級的架構,以一種將研究與工程分離的方式來構建 PyTorch 代碼,使深度學習實驗更容易理解和重復。借助它能輕松構建分布式硬件上的可擴展深度學習模型。

官網介紹說,PyTorch Lightning 的設計是為了讓大家可以將更多的時間花在研究上,而不是花在工程上。大家可以通過 PyTorch Lightning 的 官方網站 了解更多使用細節。
Hugging Face Transformers 是 Hugging Face 的開源深度學習工具庫。借助 Transformers,大家可以非常方便快速地下載最先進的預訓練模型,應用在自己的場景中,或者基於自己的數據做再訓練。

因為官方提供的大量預訓練模型,我們可以減少計算費用(因為無需從頭訓練)。豐富的模型覆蓋多種數據類型和業務源,包括:

PyTorch、TensorFlow 和 JAX 是三個最著名的深度學習庫,transformers 的對這三個框架都支持得很好,甚至可以在一個框架中用三行代碼訓練模型,在另一個框架中加載模型並進行推理。
大家可以通過 Hugging Face Transformers 的 官方網站 和 GitHub 了解更多使用細節。