python爬蟲入門案例day06:QianTu
七夕文化,農歷七月七日是牛郎織女相會之日,七夕文化宣傳離不開海
報宣傳,七夕文化中的牛郎織女神話傳說歌頌了忠貞不渝的婚愛觀,體
現了人們對理想愛情的向往和追求,它傳承並發揚了中華民族的傳統美
德,體現的是一種強烈的責任心,好了話不多說,下面直接進入爬蟲
`` ``
開發環境
1、window11
2、python3.7
3、PyCharm Community Edition 2021.2.1
4、雙核浏覽器
5、浏覽器自帶開發者工具
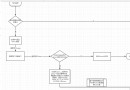
網站分析
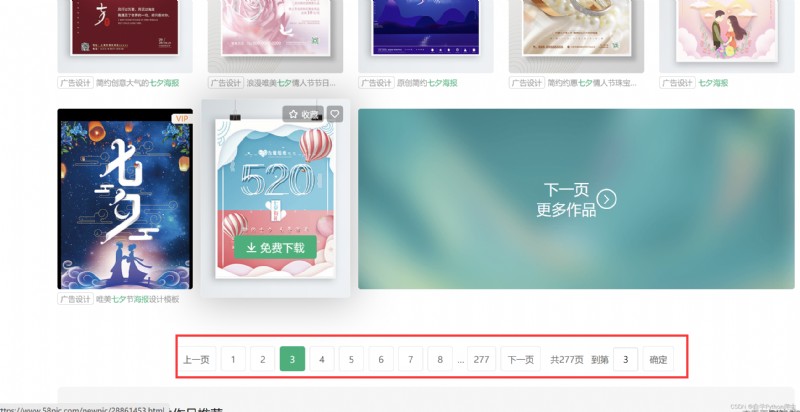
在下拉網頁的過程中發現,不會加載出新的圖片,且網頁進行了翻頁處理,
點擊下一頁網頁網址就會發生變化,對網頁進行抓包,對數據包中返回的
數據進行查找data-original,發現能查找到海報的鏈接,如圖:
數據解析分析
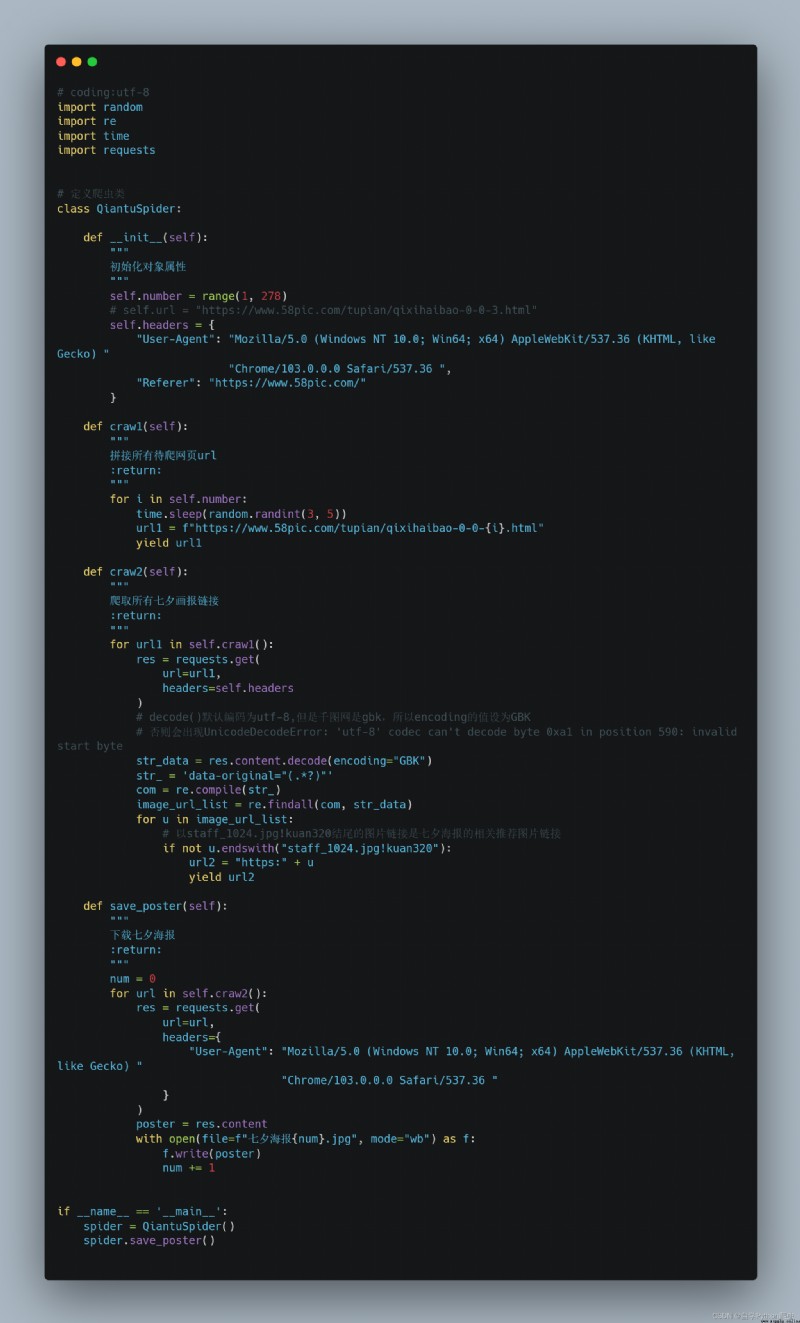
一眼可以看出海報鏈接數據結構簡單,可以直接使用re進行解析,也可以選
擇使用xpath網頁元素標簽定位來解析海報鏈接,這裡我們使用re進行爬蟲
程序的開發
源代碼
注意要點
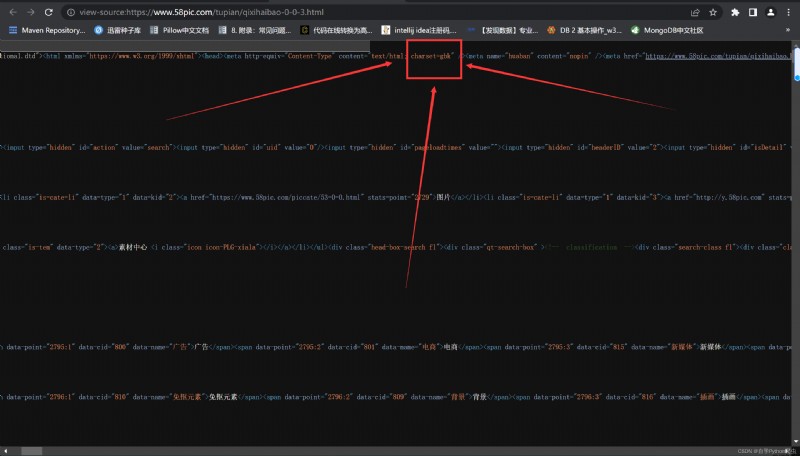
網頁源碼編碼格式為gbk,如圖:
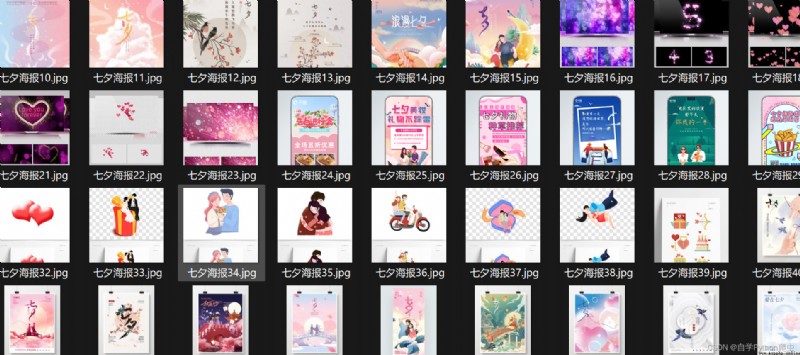
爬取到的七夕海報
知識點總結
1、我們在分析網頁的過程中,一定要先確定網頁是靜態網頁還是動態網頁,其
次,再去確認我們要爬取的數據是否通過js代碼渲染;
2、我們爬蟲最基本的反爬手段就是請求頭中添加真是浏覽器的user-agent,
有些網站服務器會檢查請求頭中是否有Referer;
3、網頁需要進行翻頁時,在已知頁數的情況下,我們選擇for去拼接待爬取的
url;
4、在使用re解析數據時,一定要先對正則字符串進行編譯,re.compile('正則字符串');
5、在爬蟲開發過程中盡可能多的去使用yield關鍵字;