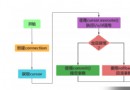
在前面基於EasyOCR包實現了基本的離線OCR功能,也即在CentOS系統下通過布設Python環境,即可利用命令行實現對指定的圖像或圖像序列進行OCR內容識別,例如:
python ./img2txt.py 001.jpg 002.jpg或者
./img2txt.py 001.jpg 002.jpg但是,目前這種命令行方式後面只能識別圖像文件名(含路徑),對於某個文件夾中包含很多掃描的圖像文件,就需要一一列出文件名字,顯得很麻煩,能不能讓命令行除了識別圖像文件、還識別文件夾參數呢?如果命令行後面跟的參數是一個文件夾(也即某個路徑),那麼就自動的對該文件夾進行遍歷,對其中的圖像類文件進行OCR?答案當然是可以的,這也是第二個版本的img2txt.py,主要升級的地方除了上面所述的命令行參數支持文件夾外,還首次支持了幫助信息輸出、通過配置文件支持關鍵參數的設置等,例如可以通過配置文件指定ocr後的txt文件保存的位置(之前是ocr識別後保存在圖像文件所在的目錄下,文件名與圖像文件相同),如果指定的文本保存文件夾不存在就自動創建等,如下所示:
#!/home/super/miniconda3/bin/python
#encoding=utf-8
#author: superchao1982, [email protected]
#幫助信息
strhelp='''
img2txt is one program to get ocr texts from image files!
default threshold is 0.1;
default langpath is '/home/langdata' for linux and 'C:\ocr\langdata' for win;
default remove char is '| _^~`&';
default path storing the ocr texts are the same directory with images;
default settings above can be changed in the file 'config.json' which stored in langpath;
contents in config.json like:
{
"threshold": 0.1,
"langpath": "/home/langdata",
"removechar": " _^~`&"
"txtpath": ""
}
------------------------------------
e.g.
./img2txt.py img1.jpg jmg2.jpg #follow by one or more image files
./img2txt.py ./img1 ./img home/usr/Document/img #follow by one or more directory contain image files
./img2txt.py --help #output the help info
./img2txt.py --config #generate the default config.json file in the langpath
------------------------------------
'''
import sys
import json
import os
#默認參數設置
threshold=0.1#阈值
removechar='| _^~`&'#待刪除無效字符
txtpath=''#ocr識別後同名txt文件存放的位置:空表示同一目錄,點表示相對目錄,其他表示絕對目錄
#根據系統設置默認的語言包路徑
if sys.platform.lower().startswith('linux'):
langpath='/home/langdata'
elif sys.platform.lower().startswith('win'):
langpath='C:\ocr\langdata'
else:
print('Error: Unknow System!')
sys.exit()
#配置參數字典
config={
"threshold": threshold,
"langpath": langpath,
"removechar": removechar,
"txtpath": txtpath
}
#首先對輸入的命令行參數進行處理,在加載ocr包之前排查的好處是避免臨處理時出錯白白浪費時間
for i in range(1,len(sys.argv)):#獲取命令行參數:argv[0]表示可執行文件本身
if sys.argv[i] in ['-h', '--help']:
print(strhelp)
sys.exit()
elif sys.argv[i] in ['-c', '--config']:
#保存字典到文件
try:
with open(os.path.join(langpath,'config.json'), 'w') as jsonfile:
json.dump(config, jsonfile, ensure_ascii=False,indent=4)
print('Genrerating config.json success! ---> ', os.path.join(langpath,'config.json'))
except(Exception) as e:
print('\tSaving config file config.json Error: ', e)#輸出異常錯誤
sys.exit()
else:
#check the image file or directory is valid-提前校驗,免得浪費時間加載easyocr模型
if not os.path.exists(sys.argv[i]):
print(sys.argv[i], ' is invalid, please input the correct file or directory path!')
sys.exit()
#檢查語言包路徑是否正確check the langpath is valid
if not os.path.exists(langpath):
print('Error: Invalid langpath! Checking the path again!')
sys.exit()
#判斷是否存在配置文件config.json,存在就使用,格式如下:
configfile=os.path.join(langpath,'config.json')
if os.path.exists(configfile):
try:
with open(configfile, 'r') as jsonfile:
configdict=json.load(jsonfile)
threshold=configdict['threshold']
langpath=configdict['langpath']
removechar=configdict['removechar']
txtpath=configdict['txtpath']
print('using the config in ', configfile)
except(Exception) as e:
print('\tReading config file ', configfile ,' Error: ', e)#輸出異常錯誤
print('\tCheck the json file, or remove the config.json file to use defaulting configs!')
sys.exit()
else:
print('\tusing the default config in ', langpath)
print(configdict)
#如果用戶在config.json中指定的txt文件保存路徑不存在就生成一個
if len(txtpath)>0 and not os.path.exists(txtpath):
print('txtpath in config.json is not exists, generating ', txtpath, '!\n')
os.system('mkdir '+txtpath)
import easyocr
ocrreader=easyocr.Reader(['ch_sim', 'en'], model_storage_directory=langpath)#Linux: r'/home/langdata', Windows: r'C:\ocr\langdata'
for i in range(1,len(sys.argv)):#獲取命令行參數:argv[0]表示可執行文件本身
argpath=sys.argv[i]
#如果是文件...
if os.path.isfile(argpath):
#獲取文件後綴名
argpathxt=os.path.splitext(argpath)[-1]
if argpathxt.upper() not in ['.JPG','.JPEG','.PNG','.BMP']:#轉換為大寫後再比對
print('\t', argpath, ' 不是有效圖片格式(jpg/jpeg/png/bmp)!')
continue
result = ocrreader.readtext(argpath)
paper=''
for w in result:
if w[2]>threshold:#設置一定的置信度阈值
paper = paper+w[1]
#print(paper)
for item in removechar:
paper=paper.replace(item, '')
paper=paper.replace('\r', '')
paper=paper.replace('\n', '')
#記錄當前文件的識別結果,保存為同名的txt文件
if(len(txtpath)>0):#如果設置了txt文件目錄
basename=os.path.basename(argpath)+'.txt'#與原文件同名的txt文件(不含目錄僅文件名)
txtfilename=os.path.join(txtpath, basename)
else:
txtfilename=os.path.splitext(argpath)[0]+'.txt'#與原文件同名的txt文件(包括目錄)
print('saving file ---> ', txtfilename)#保存的文件名字
try:
with open(txtfilename, 'w') as txtfile:
txtfile.write(paper)
except(Exception) as e:
print('\t', txtfilename, ' Saving txt File Error: ', e)#輸出異常錯誤
continue
#如果是文件夾...
if os.path.isdir(argpath):
for root, _, filenames in os.walk(argpath):
for imgfile in filenames:
filext=os.path.splitext(imgfile)[-1]#文件後綴名
if filext.upper() not in ['.JPG','.JPEG','.PNG','.BMP']:
print('\t', imgfile, '的後綴名不是圖像格式,跳過該文件!')
continue
imgfilepath=os.path.join(root, imgfile)#文件絕對路徑
result = ocrreader.readtext(imgfilepath)
paper=''
for w in result:
if w[2]>threshold:#設置一定的置信度阈值
paper = paper+w[1]
#print(paper)
for item in removechar:
paper=paper.replace(item, '')
paper=paper.replace('\r', '')
paper=paper.replace('\n', '')
#記錄當前文件的識別結果,保存為同名的txt文件
basename=os.path.splitext(imgfile)[0]+'.txt'#與原文件同名的txt文件(不包括目錄)
if(len(txtpath)>0):#如果設置了txt文件目錄
txtfilename=os.path.join(txtpath,basename)
else:
txtfilename=os.path.join(root, basename)#需要加上絕對路徑
print('saving file ---> ', txtfilename)#保存的文件名字
try:
with open(txtfilename, 'w') as txtfile:
txtfile.write(paper)
except(Exception) as e:
print('\t', txtfilename, ' Saving txt File Error: ', e)#輸出異常錯誤
continue
注意,並沒有在一開始就import easyOCR包,這是因為導入ocr包比較耗費資源,如果前面路徑部分出錯就白白浪費了時間,所以將這種比較耗費資源的行為放在了確實需要的地方。
 Chapter II of Django: addition, deletion, modification and investigation (illustrated and easy to use)
Chapter II of Django: addition, deletion, modification and investigation (illustrated and easy to use)
Welcome to Magic house !! The