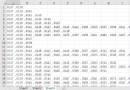
准備導入的excel為: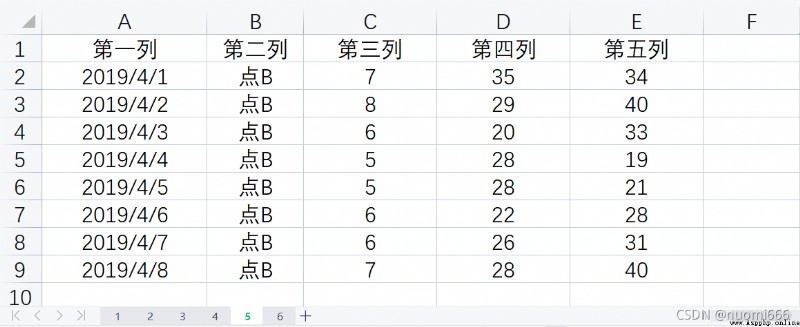
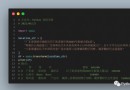
可以采用pandas的read_excel功能,具體代碼如下:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夾索引/文件名.xlsx',
sheet_name='工作表sheet的名字')sheet_name不設置參數,就默認第一個工作表,同時也可設置工作表的位置,讀取第5個工作表可以設置為=4。
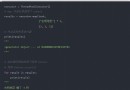
如果對獲取工作表其中的某列或者多列,可以使用usecols參數,比如讀取第5個工作表的第2列到第5列,可以用下面的代碼:
import pandas as pd
getdata=pd.read_excel(r'C:/文件夾索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols=[i for i in range (1,6)])usecols參數也可以設置成列的索引字母,比如usecols="B,D:E",可以獲取第1和3到5列,同時設置參數index_col=1,把第二列當作索引,代碼及輸出結果為:
getdata=pd.read_excel(r'C:/文件夾索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
sheet_name=4,
usecols="A,C:E",
index_col=1)
print(Getdata)
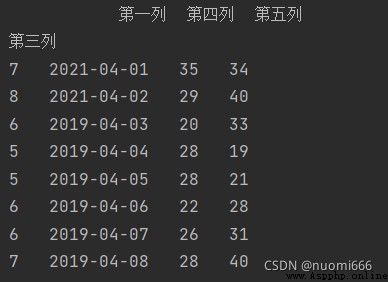
如果不想獲取全部行數,如獲取前5行可以設置參數nrows=5,同時跳過第2行到第4行,可以設置參數skiprows=[i for i in range(2,5)],或者skiprows=[2,3,4],代碼及輸出結果:
getdata=pd.read_excel(r'C:/文件夾索引/文件名.xlsx',
sheet_name='工作表sheet的名字',
skiprows=[2,3,4],
nrows=5)
print(Getdata)
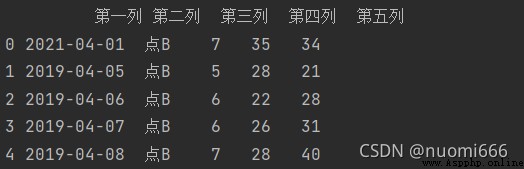
這裡應當注意,設置的nrows是總共要獲取多少行,如果設置skiprows跳過一定數量行後,將在之後行裡繼續獲取,直到補足nrows所要獲取的行數。
寫的第一篇,可能內容不詳盡,後續進行補充