pandas 是基於NumPy 的一種工具,該工具是為解決數據分析任務而創建的.Pandas 納入了大量庫和一些標准的數據模型,提供了高效地操作大型數據集所需的工具.pandas提供了大量能使我們快速便捷地處理數據的函數和方法.你很快就會發現,它是使Python成為強大而高效的數據分析環境的重要因素之一.
1、pandas怎樣讀取數據 數據類型 說明 讀取方法 csv 、tsv、txt用逗號分隔,tab分隔的純文本文件pd.read_csvexcel微軟xls或者xlsx文件pd.read_excelmysql關系型數據庫表pd.read_sql
例:
import pandas as pd
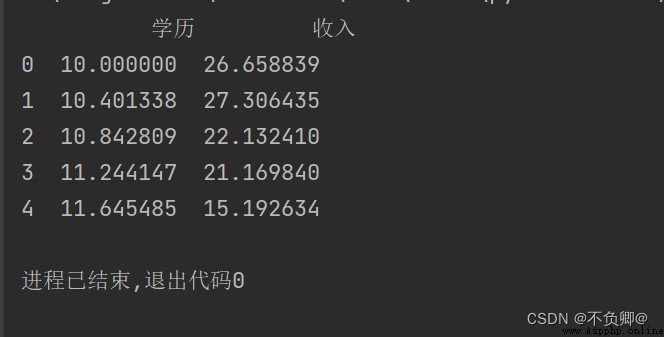
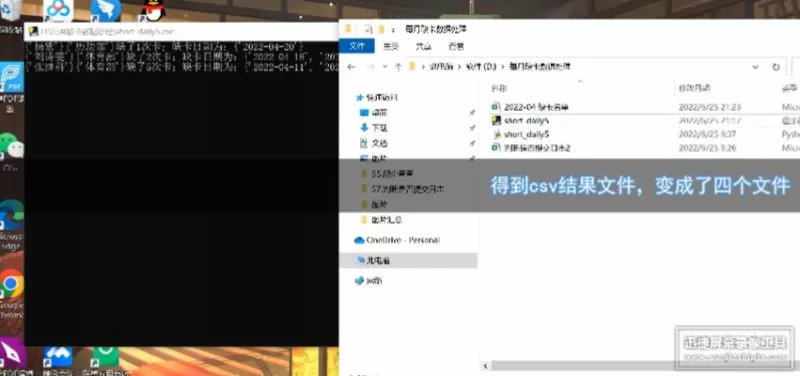
df=pd.read_csv("./DataIncome.csv")
print(df.head()) #headThe method is to preview the first five pieces of data
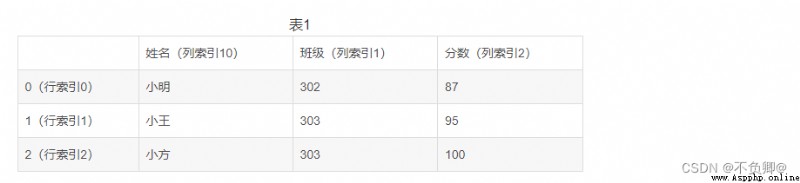
2、pandas數據結構 2.1 DataFrame 二維數據(理解為表)
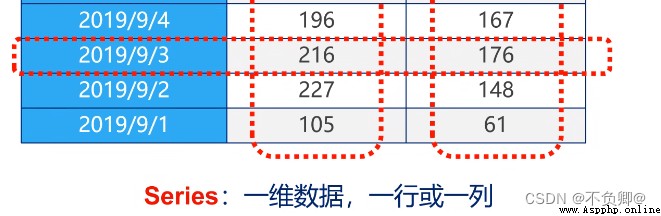
2.2 Series(一維數據,理解為python中的列表)
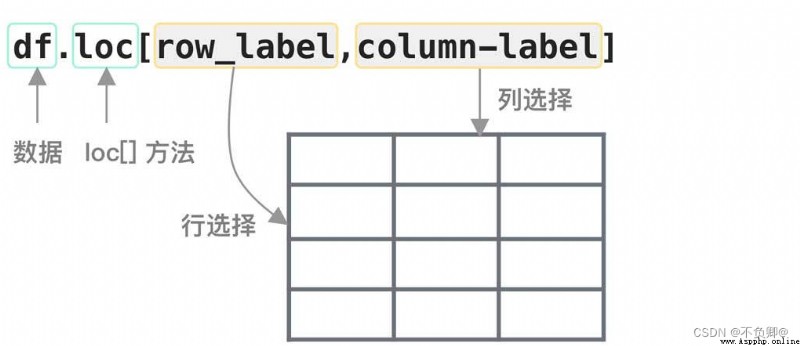
3、怎樣查詢數據 3.1、df.loc 根據行、列標簽值查詢
print(df.loc[:, "name"])
3.2、df.iloc 對數據進行位置索引,從而在數據表中提取出相應的數據.
df.iloc[a,b]
a是行索引 ,b是列索引
import pandas
df = pandas.read_csv('a.csv')
print(df.iloc[1,2])
輸出:95
4、新增數據列 4.1 直接賦值 import pandas
df = pandas.read_csv('a.csv')
df['test']=0 #新增列名
4.2 insert()函數 insert()函數語法:
df.insert(loc, column, value,allow_duplicates = False)
參數說明:
loc 必要字段,int類型數據,Indicates the column position at which to insert the new column,The column originally in that position will be shifted to the right. column 必要字段,Insert the column name of the new column. value 必要字段,The value inserted in the new column.If only one value is provided,The same value will be set for all rows.可以是int,string,float等,甚至可以是series /值列表. allow_duplicates 布爾值,Used to check if a column with the same name exists.默認為False,Duplicates with existing column names are not allowed. 5、統計函數 函數 含義 min()計算最小值max()計算最大值sum()求和mean()計算平均值count()計數(統計非缺失元素的個數)size()計數(統計所有元素的個數)median()計算中位數var()計算方差std()計算標准差quantile()計算任意分位數cov()計算協方差corr()計算相關系數skew()計算偏度kurt()計算峰度mode()計算眾數describe()描述性統計(一次性返回多個統計結果)groupby()分組aggregate()聚合運算(可以自定義統計函數)argmin()尋找最小值所在位置argmax()尋找最大值所在位置any()等價於邏輯“或”all()等價於邏輯“與”value_counts()頻次統計cumsum()運算累計和cumprod()運算累計積pct_change()運算比率(後一個元素與前一個元素的比率)
6、判斷空值(數據清洗) 6.1 判斷pandasway of a single null value object: 利用pd.isnull(),pd.isna() 利用np.isnan() 利用is表達式 利用in表達式 6.2 判斷pandasway of multiple null-valued objects: 可以用Series對象和DataFrame對象的any()或all()方法; 可以用numpy的any()或all()方法; 不可以直接用python的內置函數any()和all()方法; 可以用Series或DataFrame對象的dropna()方法剔除空值; 可以用Series或DataFrame對象的fillna()方法填充空值 6.3數據清洗常用函數 函數 含義 duplicated()判斷序列元素是否重復drop_duplicates()刪除重復值hasnans()判斷序列是否存在缺失(返回TRUE或FALSE)isnull()判斷序列元素是否為缺失(返回與序列長度一樣的bool值)notnull()判斷序列元素是否不為缺失(返回與序列長度一樣的bool值)dropna()刪除缺失值fillna()缺失值填充ffill()前向後填充缺失值(使用缺失值的前一個元素填充)bfill()後向填充缺失值(使用缺失值的後一個元素填充)dtypes()檢查數據類型astype()類型強制轉換pd.to_datetime轉日期時間型factorize()因子化轉換sample()抽樣where()基於條件判斷的值替換replace()按值替換(不可使用正則)str.replace()按值替換(可使用正則)str.split.str()字符分隔
6.4數據篩選函數 函數 含義 isin()成員關系判斷between()區間判斷loc()條件判斷(可使用在數據框中)iloc()索引判斷(可使用在數據框中)compress()條件判斷nlargest()搜尋最大的n個元素nsmallest()搜尋最小的n個元素str.findall()子串查詢(可使用正則)
7、數據排序 7.1DataFrame排序 函數:DataFrame.sort_values(by, ascending=True, inplace=False)參數說明:
by:字符串或者List<字符串>,單列排序或者多列排序. ascending:bool或者List,默認為True,如果為list,Multiple columns are sorted. inplace:是否修改原始DataFrame.df.sort_values(by="name") 7.2Series排序: 函數:Series.sort_values(ascending=True, inplace=False)參數說明:
ascending:默認為True升序排序,為False降序排序. inplace:是否修改原始Series. 例如:df["name"].sort_values(ascending=True)
8、時間序列函數 函數 含義 dt.date()抽取出日期值dt.time()抽取出時間(時分秒)dt.year()抽取出年dt.mouth()抽取出月dt.day()抽取出日dt.hour()抽取出時dt.minute()抽取出分鐘dt.second()抽取出秒dt.quarter()抽取出季度dt.weekday()抽取出星期幾(返回數值型)dt.weekday_name()抽取出星期幾(返回字符型)dt.week()抽取出年中的第幾周dt.dayofyear()抽取出年中的第幾天dt.daysinmonth()抽取出月對應的最大天數dt.is_month_start()判斷日期是否為當月的第一天dt.is_month_end()判斷日期是否為當月的最後一天dt.is_quarter_start()判斷日期是否為當季度的第一天dt.is_quarter_end()判斷日期是否為當季度的最後一天dt.is_year_start()判斷日期是否為當年的第一天dt.is_year_end()判斷日期是否為當年的最後一天dt.is_leap_year()判斷日期是否為閏年
9、繪圖函數 函數 含義 hist()繪制直方圖plot()可基於kind參數繪制更多圖形(餅圖,折線圖,箱線圖等)map()元素映射apply()基於自定義函數的元素級操作
10、其他函數 函數 含義 append()序列元素的追加(需指定其他序列)diff()一階差分round()元素的四捨五入sort_values()按值排序sort_index()按索引排序to_dict()轉為字典tolist()轉為列表unique()元素排重