前些天發現了一個巨牛的人工智能學習電子書,通俗易懂,風趣幽默,無廣告,忍不住分享一下給大家。(點擊跳轉人工智能學習資料)
說明:若需要數據附件及python源文件請移步微信公眾號“創享日記”,聯系作者有償獲取!
一、題目
附件drug. order_ detai 1.xlsx是某連鎖藥店銷售數據,請使用pandas和numpy分析藥店的營業數據:
(1)讀取附件中excel文件drug._order_detail_1.xlsx 中的數據;
(2)計算所有分店的總銷售額並打印輸出;
(3)增加“銷售額”列,其中,銷售額=價格*銷量;
(4)按分店統計不同分店銷售額的最小值、最大值、平均值、並打印輸出;
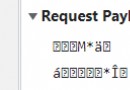
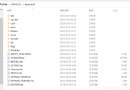
(5)輸出效果如下所示,其中,*號代表具體統計的數。
二、題目分析
對於Excel文件的處理,常見的就是pandas庫,我們引入pandas庫之後通過read_excel方法就可以讀取到指定的Excel文件,注意就是要指定sheet的名稱。然後我們將其轉化為DataFrame類型進行計算。然後我們計算所有分店的總銷售額,只需要遍歷所有分店,然後用那一行的銷量乘以那一行的單價,然後每次相加就可以得出結果,然後通過print進行輸出。然後添加列,其實有一種簡單的方法,就是當你df[‘銷售額’]的時候,系統檢測到Excel文件中並沒有銷售額這一列,那麼就會自動添加上去,然後只需要指定它的值為對應的價格乘以銷量即可。之後通過numpy的min,max和mean函數就可以輕松求的最大值最小值和平均值了。
三、代碼
import pandas as pd
import numpy as np
import xlrd
data=pd.read_excel('drug_order_detai_1.xlsx',sheet_name='drug_order_detail2')
df=pd.DataFrame(data)
row,col=df.shape
sum=0
list=[]
for i in range(0,row):
sum+=int(df.loc[i]['銷量'])*int(df.loc[i]['價格'])
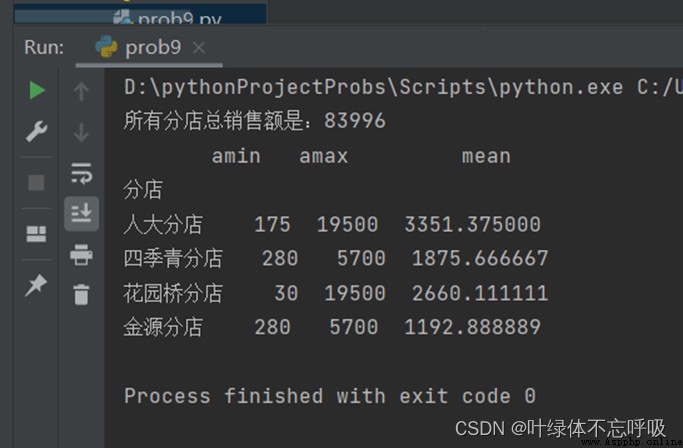
print("所有分店總銷售額是:"+str(sum))
df['銷售額'] = df['價格'] * df['銷量']
print(pd.DataFrame(df.groupby('分店')['銷售額'].agg([np.min,np.max,np.mean])))
四、實驗結果
 Python Apache CGI programming, how to configure Apache and conf files in win10
Python Apache CGI programming, how to configure Apache and conf files in win10
Ive been studying recently pyt
 Blue Bridge Cup [11th provincial competition] crop hybridization Python 100 points
Blue Bridge Cup [11th provincial competition] crop hybridization Python 100 points
First, lets analyze the sample