至此,終於迎來了離線ocr的終極大結局,命令行後面參數既支持圖像文件、圖像文件夾,還支持PDF圖像類型的文件,既支持通過json文件進行參數配置,又支持幫助文檔,easyOCR包既支持允許字符集(也即僅支持字符集中的識別,例如在驗證碼識別場合),也支持排除字符集,還支持批處理尺寸大小、線程數目、分段結構保留(支持paragraph時,ocr結果就沒有原來單句時的識別概率值了)等。
#!/home/super/miniconda3/bin/python
#encoding=utf-8
#author: superchao1982, [email protected]
#幫助信息
strhelp='''
img2txt is one program to get ocr texts from image or pdf files!
batchsize is the batch size, larger more faster but more merrory;
workernum is the number of threads, larger more faster;
maximgsize is the max height or width of the images to be passed to the ocr processing when extract from the pdf files;
paragraph is whether to keep the paragraph when ocring
langpath is the directory of the language data stored, '/home/langdata' for linux and 'C:\ocr\langdata' for win;
allowlist is chars allow to be recognized only, '' means allow all charactors;
removechar is char to be removed when ocr processing, for example '| _^~`&';
txtdir is the path to store the txt files, could be any legal absolute or relative path,'' means the same directory of the image files;
=== settings above can be changed in the file 'config.json' which stored in langpath ===
contents in config.json like:
{
"batchsize": 2,
"workernum": 4,
"maximgsize": 1000,
"paragraph": True
"langpath": "/home/langdata",
"allowlist": "",
"removechar": " _^~`&"
"txtdir": ""
}
------------------------------------
e.g.
./img2txt.py img1.jpg jmg2.jpg 001.pdf 002.pdf #follow by one or more image or pdf files
./img2txt.py ./pdfs home/usr/Document/imgs #follow by one or more directory contain image or pdf files
./img2txt.py --help #output the help info
./img2txt.py --config #generate the default config.json file in the langpath
------------------------------------
'''
import sys
import json
import os
import pdf2image
import numpy as np
#------------------默認參數設置----------------------
batchsize=2 # (default = 1) - Batch_size>1 will make EasyOCR faster but use more memory
workernum=4 # (default = 0) - Number thread used in of dataloader
maximgsize=1000 # (default = 1000) - Max image width & height when using pdf
paraend='\n' # (default = '\n') - The paragraph ending char
allowlist='' # (string) - Force EasyOCR to recognize only subset of characters
removechar='| _^~`&'#待刪除無效字符
txtdir='' #ocr識別後同名txt文件存放的位置:空表示同一目錄,點表示相對目錄,其他表示絕對目錄
#根據系統設置默認的語言包路徑
if sys.platform.lower().startswith('linux'):
langpath='/home/langdata'
elif sys.platform.lower().startswith('win'):
langpath='C:\ocr\langdata'
else:
print('\tError: Unknow System!')
sys.exit()
#根據默認參數生成配置字典
config={
"batchsize": batchsize,
"workernum": workernum,
"maximgsize": maximgsize,
"paraend": paraend,
"allowlist": allowlist,
"langpath": langpath,
"removechar": removechar,
"txtdir": txtdir
}
#------------------命令行參數處理----------------------
#首先對輸入的命令行參數進行處理,在加載ocr包之前排查的好處是避免臨處理時出錯白白浪費時間
for i in range(1,len(sys.argv)):#獲取命令行參數:argv[0]表示可執行文件本身
if sys.argv[i] in ['-h', '--help']:
print(strhelp)
sys.exit()
elif sys.argv[i] in ['-c', '--config']:
#保存字典到文件
try:
with open(os.path.join(langpath,'config.json'), 'w') as jsonfile:
json.dump(config, jsonfile, ensure_ascii=False,indent=4)
print('Genrerating config.json success! ---> ', os.path.join(langpath,'config.json'))
except(Exception) as e:
print('\tSaving config file config.json Error: ', e)#輸出異常錯誤
sys.exit()
else:
#check the image file or directory is valid-提前校驗,免得浪費時間加載easyocr模型
if not os.path.exists(sys.argv[i]):
print(sys.argv[i], ' is invalid, please input the correct file or directory path!')
sys.exit()
#判斷指定目錄下是否存在配置文件config.json,存在就使用(不存在就使用上面的默認值):
configfile=os.path.join(langpath,'config.json')
if os.path.exists(configfile):
try:
with open(configfile, 'r') as jsonfile:
config=json.load(jsonfile)
batchsize=config['batchsize']
workernum=config['workernum']
maximgsize=config['maximgsize']
paraend=config['paraend']
langpath=config['langpath']
allowlist=config['allowlist']
removechar=config['removechar']
txtdir=config['txtdir']
print('Using the config in ', configfile)
except(Exception) as e:
print('\tReading config file ', configfile ,' Error: ', e)#輸出異常錯誤
print('\tCheck the json file, or remove the config.json file to use defaulting configs!')
sys.exit()
else:
print('Using the default config! You can make your own config.json in ', langpath, ' by using the "--config" option')
print(config)
#------------------OCR前准備工作----------------------
#檢查語言包路徑是否正確,語言包是必須的
if not os.path.exists(langpath):
print('\tError: Invalid langpath! Checking the path again!')
sys.exit()
#檢查txt文件保存路徑,不存在就生成一個
if len(txtdir)>0 and not os.path.exists(txtdir):
print('txtdir in config.json is not exists, generating ', txtdir)
try:
os.system('mkdir '+txtdir)
print('Making directory: ',txtdir)
except(Exception) as e:
print('\tMaking txt directory Error: ', e)#輸出異常錯誤
print('\tPlease input a legal txtdir in the config.json file and try again!')
sys.exit()
#根據段落結尾符ocr時判斷是否分段落
if len(paraend)>0:
paragraph=True
else:
paragraph=False
#導入ocr包及語言包——之所以不在前面導入,是因為導入包花費時間較多,如果前面由於配置出錯就浪費了時間
import easyocr
ocrreader=easyocr.Reader(['ch_sim', 'en'], model_storage_directory=langpath)#Linux: r'/home/langdata', Windows: r'C:\ocr\langdata'
#------------------開始OCR識別----------------------
for ind in range(1,len(sys.argv)):#依次獲取命令行參數:由於argv[0]表示可執行文件本身,所以忽略該參數
argvalue=sys.argv[ind]
#如果命令行參數是文件類型,就對該文件進行處理...
if os.path.isfile(argvalue):
paper=''
#獲取文件後綴名
filext=os.path.splitext(argvalue)[-1]
if filext.upper() not in ['.JPG','.JPEG','.PNG','.BMP','.PDF']:#轉換為大寫後再比對
print('\t', argvalue, ' 不是有效的文件格式(jpg/jpeg/png/bmp/pdf)!')
continue#下一個命令行參數
#如果是pdf文檔
if filext.upper() in['.PDF']:
images=pdf2image.convert_from_path(argvalue)#將pdf文檔轉換為圖像序列
for i in range(len(images)):#如果pdf轉換後的圖片尺寸過大,為了避免內存崩潰,縮小到特定尺寸
ratio=max(images[i].width, images[i].height)/maximgsize#需要縮小的倍數
if ratio>1:
images[i]=images[i].resize((round(images[i].width/ratio),round(images[i].height/ratio)))
#至此,需要進行ocr的圖片數據准備完畢!
if len(allowlist)>0:#如果設置了識別字符集
result = ocrreader.readtext(np.asarray(images[i]),batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph,allowlist=allowlist)
else:
result = ocrreader.readtext(np.asarray(images[i]),batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph)
for w in result:#識別結果是一個列表,對識別結果進行拼接
paper = paper+w+paraend
else:#否則,本身就是圖片數據
if len(allowlist)>0:#如果設置了識別字符集
result = ocrreader.readtext(argvalue,batch_size=batchsize,workers=workernumt,detail=0,paragraph=paragraph,allowlist=allowlis)
else:
result = ocrreader.readtext(argvalue,batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph)
for w in result:#識別結果是一個列表,對識別結果進行拼接
paper = paper+w+paraend #如果設置了段落結尾符,在拼接時加上
#如果設置了刪除字符集
for item in removechar:#依次刪除
paper=paper.replace(item, '')
#print(paper)#至此,文本識別全部完成!-------------------
#下面開始存儲識別結果txt文件
#記錄當前文件的識別結果,保存為同名的txt文件
if(len(txtdir)>0):#如果設置了txt文件目錄
txtname=os.path.basename(argvalue)+'.txt'#與原文件同名的txt文件(不含目錄僅文件名)
txtpath=os.path.join(txtdir, txtname)
else:
txtpath=os.path.splitext(argvalue)[0]+'.txt'#與原文件同名的txt文件(包括目錄)
print('saving file ---> ', txtpath)#保存的文件名字
try:
with open(txtpath, 'w') as txtfile:
txtfile.write(paper)
except(Exception) as e:
print('\t', txtpath, ' Saving txt File Error: ', e)#輸出異常錯誤
continue
#如果是文件夾...
if os.path.isdir(argvalue):
for root, _, filenames in os.walk(argvalue):#依次遍歷文件夾,由於不關心其中的文件夾,所以將文件夾設置為隱變量
for imgname in filenames:#遍歷的每個文件(不含路徑,路徑在root裡)
paper=''
filext=os.path.splitext(imgname)[-1]#得到文件後綴名
if filext.upper() not in ['.JPG','.JPEG','.PNG','.BMP','.PDF']:
print('\t', imgname, '的後綴名不是有效的文件格式,跳過該文件!')
continue
#與root進行拼接,得到圖像文件的絕對路徑(含文件名和後綴名)
imgpath=os.path.join(root, imgname)#文件絕對路徑
#如果是pdf文檔
if filext.upper() in['.PDF']:
images=pdf2image.convert_from_path(imgpath)#將pdf文檔轉換為圖像序列
for i in range(len(images)):#如果pdf轉換後的圖片尺寸過大,為了避免內存崩潰,縮小到特定尺寸
ratio=max(images[i].width, images[i].height)/maximgsize#需要縮小的倍數
if ratio>1:
images[i]=images[i].resize((round(images[i].width/ratio),round(images[i].height/ratio)))
#至此,需要進行ocr的圖片數據准備完畢!
if len(allowlist)>0:#如果設置了識別字符集
result = ocrreader.readtext(np.asarray(images[i]),batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph,allowlist=allowlist)
else:
result = ocrreader.readtext(np.asarray(images[i]),batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph)
for w in result:#識別結果是一個列表,對識別結果進行拼接
paper = paper+w+paraend #如果設置了段落結尾符,在拼接時加上
else:#否則,本身就是圖片數據
if len(allowlist)>0:#如果設置了識別字符集
result = ocrreader.readtext(imgpath,batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph,allowlist=allowlist)
else:
result = ocrreader.readtext(imgpath,batch_size=batchsize,workers=workernum,detail=0,paragraph=paragraph)
for w in result:#識別結果是一個列表,對識別結果進行拼接
paper = paper+w+paraend #如果設置了段落結尾符,在拼接時加上
#如果設置了刪除字符集
for item in removechar:#依次刪除
paper=paper.replace(item, '')
#print(paper)
#至此,文本識別全部完成!--------------------
#下面開始存儲識別結果txt文件
#記錄當前文件的識別結果,保存為同名的txt文件
txtname=os.path.splitext(imgname)[0]+'.txt'#與原文件同名的txt文件(不包括目錄)
if(len(txtdir)>0):#如果設置了非空的txt文件目錄
#原來的方式是直接把所有的txt全部放在指定的一個文件夾中,當不同文件夾中存在同名的圖像文件時,會存在txt文件覆蓋的情況
#txtpath=os.path.join(txtdir, txtname)#拼接得到txt文件的絕對路徑
#下面的方式是在指定的文件夾下面按照原圖像文件的目錄結構新建相同的文件夾結構並存放txt文件
relativeimgpath=imgpath[len(argvalue)+1:]#圖片絕對路徑左減去命令行指定的路徑argpath得到圖像文件的內部相對路徑,+1是去除\
imgtxtdir=os.path.join(txtdir,relativeimgpath)#指定txt文件路徑+圖像內部相對路徑(還帶有圖像文件名和後綴名)
txtfiledir=os.path.dirname(imgtxtdir)#去掉圖像文件名和後綴名
if not os.path.exists(txtfiledir):#上面的新文件路徑不一定存在
try:
os.system('mkdir '+txtfiledir)#新建文件夾
print('Making directory: ',txtfiledir)
except(Exception) as e:
print('\tMaking txt directory Error: ', e)#輸出異常錯誤
print('\tTxt file will be storded in the image file directory!')
txtpath=os.path.join(root, txtname)#路徑+txt文件名
txtpath=os.path.join(txtfiledir, txtname)#新路徑+txt文件名
else:#否則就是默認的空的txt文件目錄,表示txt文件就存儲在圖像對應的文件夾裡
txtpath=os.path.join(root, txtname)#路徑+txt文件名
print('saving file ---> ', txtpath)#保存的文件名字
try:
with open(txtpath, 'w') as txtfile:
txtfile.write(paper)
except(Exception) as e:
print('\t', txtpath, ' Saving txt File Error: ', e)#輸出異常錯誤
continue
最後,由於easyOCR自身的原因,總會給出一些很煩人的關於pytorch包的warnings,為了避免這些警告信息干擾,可以按照warnings中的信息對其中的_utils.py文件進行修改,路徑如下:
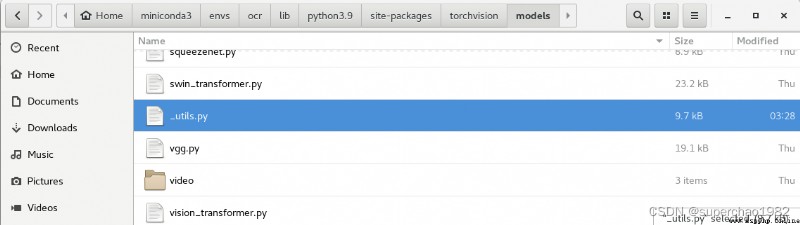
將其中的warnings對應的語句刪除即可,刪除後的_utils.py文件內容如下(請謹慎刪除,或者先備份源文件後再刪除):
import functools
import inspect
import warnings
from collections import OrderedDict
from typing import Any, Dict, Optional, TypeVar, Callable, Tuple, Union
from torch import nn
from .._utils import sequence_to_str
from ._api import WeightsEnum
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
Examples::
>>> m = torchvision.models.resnet18(weights=ResNet18_Weights.DEFAULT)
>>> # extract layer1 and layer3, giving as names `feat1` and feat2`
>>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
>>> {'layer1': 'feat1', 'layer3': 'feat2'})
>>> out = new_m(torch.rand(1, 3, 224, 224))
>>> print([(k, v.shape) for k, v in out.items()])
>>> [('feat1', torch.Size([1, 64, 56, 56])),
>>> ('feat2', torch.Size([1, 256, 14, 14]))]
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super().__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x):
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
def _make_divisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
D = TypeVar("D")
def kwonly_to_pos_or_kw(fn: Callable[..., D]) -> Callable[..., D]:
"""Decorates a function that uses keyword only parameters to also allow them being passed as positionals.
For example, consider the use case of changing the signature of ``old_fn`` into the one from ``new_fn``:
.. code::
def old_fn(foo, bar, baz=None):
...
def new_fn(foo, *, bar, baz=None):
...
Calling ``old_fn("foo", "bar, "baz")`` was valid, but the same call is no longer valid with ``new_fn``. To keep BC
and at the same time warn the user of the deprecation, this decorator can be used:
.. code::
@kwonly_to_pos_or_kw
def new_fn(foo, *, bar, baz=None):
...
new_fn("foo", "bar, "baz")
"""
params = inspect.signature(fn).parameters
try:
keyword_only_start_idx = next(
idx for idx, param in enumerate(params.values()) if param.kind == param.KEYWORD_ONLY
)
except StopIteration:
raise TypeError(f"Found no keyword-only parameter on function '{fn.__name__}'") from None
keyword_only_params = tuple(inspect.signature(fn).parameters)[keyword_only_start_idx:]
@functools.wraps(fn)
def wrapper(*args: Any, **kwargs: Any) -> D:
args, keyword_only_args = args[:keyword_only_start_idx], args[keyword_only_start_idx:]
if keyword_only_args:
keyword_only_kwargs = dict(zip(keyword_only_params, keyword_only_args))
warnings.warn(
f"Using {sequence_to_str(tuple(keyword_only_kwargs.keys()), separate_last='and ')} as positional "
f"parameter(s) is deprecated since 0.13 and will be removed in 0.15. Please use keyword parameter(s) "
f"instead."
)
kwargs.update(keyword_only_kwargs)
return fn(*args, **kwargs)
return wrapper
W = TypeVar("W", bound=WeightsEnum)
M = TypeVar("M", bound=nn.Module)
V = TypeVar("V")
def handle_legacy_interface(**weights: Tuple[str, Union[Optional[W], Callable[[Dict[str, Any]], Optional[W]]]]):
"""Decorates a model builder with the new interface to make it compatible with the old.
In particular this handles two things:
1. Allows positional parameters again, but emits a deprecation warning in case they are used. See
:func:`torchvision.prototype.utils._internal.kwonly_to_pos_or_kw` for details.
2. Handles the default value change from ``pretrained=False`` to ``weights=None`` and ``pretrained=True`` to
``weights=Weights`` and emits a deprecation warning with instructions for the new interface.
Args:
**weights (Tuple[str, Union[Optional[W], Callable[[Dict[str, Any]], Optional[W]]]]): Deprecated parameter
name and default value for the legacy ``pretrained=True``. The default value can be a callable in which
case it will be called with a dictionary of the keyword arguments. The only key that is guaranteed to be in
the dictionary is the deprecated parameter name passed as first element in the tuple. All other parameters
should be accessed with :meth:`~dict.get`.
"""
def outer_wrapper(builder: Callable[..., M]) -> Callable[..., M]:
@kwonly_to_pos_or_kw
@functools.wraps(builder)
def inner_wrapper(*args: Any, **kwargs: Any) -> M:
for weights_param, (pretrained_param, default) in weights.items(): # type: ignore[union-attr]
# If neither the weights nor the pretrained parameter as passed, or the weights argument already use
# the new style arguments, there is nothing to do. Note that we cannot use `None` as sentinel for the
# weight argument, since it is a valid value.
sentinel = object()
weights_arg = kwargs.get(weights_param, sentinel)
if (
(weights_param not in kwargs and pretrained_param not in kwargs)
or isinstance(weights_arg, WeightsEnum)
or (isinstance(weights_arg, str) and weights_arg != "legacy")
or weights_arg is None
):
continue
# If the pretrained parameter was passed as positional argument, it is now mapped to
# `kwargs[weights_param]`. This happens because the @kwonly_to_pos_or_kw decorator uses the current
# signature to infer the names of positionally passed arguments and thus has no knowledge that there
# used to be a pretrained parameter.
pretrained_positional = weights_arg is not sentinel
if pretrained_positional:
# We put the pretrained argument under its legacy name in the keyword argument dictionary to have a
# unified access to the value if the default value is a callable.
kwargs[pretrained_param] = pretrained_arg = kwargs.pop(weights_param)
else:
pretrained_arg = kwargs[pretrained_param]
if pretrained_arg:
default_weights_arg = default(kwargs) if callable(default) else default
if not isinstance(default_weights_arg, WeightsEnum):
raise ValueError(f"No weights available for model {builder.__name__}")
else:
default_weights_arg = None
del kwargs[pretrained_param]
kwargs[weights_param] = default_weights_arg
return builder(*args, **kwargs)
return inner_wrapper
return outer_wrapper
def _ovewrite_named_param(kwargs: Dict[str, Any], param: str, new_value: V) -> None:
if param in kwargs:
if kwargs[param] != new_value:
raise ValueError(f"The parameter '{param}' expected value {new_value} but got {kwargs[param]} instead.")
else:
kwargs[param] = new_value
def _ovewrite_value_param(param: Optional[V], new_value: V) -> V:
if param is not None:
if param != new_value:
raise ValueError(f"The parameter '{param}' expected value {new_value} but got {param} instead.")
return new_value
class _ModelURLs(dict):
def __getitem__(self, item):
return super().__getitem__(item)