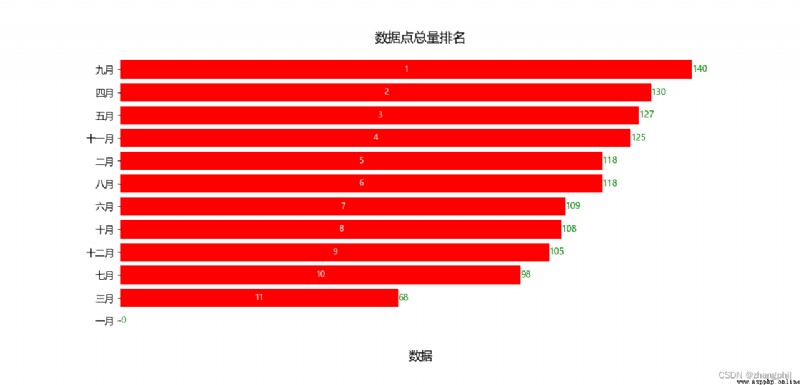
[月份維度]日志數據提取包含關鍵詞的事件,解析落入的月份計數,matplotlib繪制統計圖,python
日志數據提取事件關鍵詞,解析對應日期的星期計數,matplotlib繪制統計圖,python
https://zhangphil.blog.csdn.net/article/details/125941649 https://zhangphil.blog.csdn.net/article/details/125941649
https://zhangphil.blog.csdn.net/article/details/125941649
在此基礎上,對代碼修改,以月為維度,統計包含關鍵詞事件落入的月份。
from datetime import datetime
from pprint import pp
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from fuzzywuzzy import fuzz
import re
FILE_PATH = r'源數據路徑'
KEY = r'模糊匹配的關鍵詞' # 關鍵詞1,關鍵詞2
threshold = 80
SECTION = 'section'
SUM = 'sum'
def drawchart(df):
myfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\msyh.ttc')
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
plt.rc('font', family='YaHei', weight='bold')
order = []
name = []
mem = []
for d, i in zip(df.values, df.index):
order.append(i)
name.append(d[0])
mem.append(int(d[1]))
FONT_SIZE = 12
fig, ax = plt.subplots(figsize=(15, 13))
b = ax.barh(y=range(len(name)), width=mem, align='center', color='red')
# 為橫向水平的柱圖右側添加數據標簽。
i = 0
for rect in b:
w = rect.get_width()
ax.text(x=w, y=rect.get_y() + rect.get_height() / 2, s='%d' % (int(w)),
horizontalalignment='left', verticalalignment='center',
fontproperties=myfont, fontsize=FONT_SIZE - 2, color='green')
ax.text(x=w / 2, y=rect.get_y() + rect.get_height() / 2, s=str(order[i]),
horizontalalignment='center', verticalalignment='center',
fontproperties=myfont, fontsize=FONT_SIZE - 3, color='white')
i = i + 1
ax.set_yticks(range(len(name)))
ax.set_yticklabels(name, fontsize=FONT_SIZE - 1, fontproperties=myfont)
ax.invert_yaxis()
ax.set_xlabel('數據', fontsize=FONT_SIZE + 2, fontproperties=myfont)
ax.set_title('數據點總量排名', fontsize=FONT_SIZE + 3, fontproperties=myfont)
# 不要橫坐標上的label標簽。
plt.xticks(())
# 清除四周的邊框線
ax.get_yaxis().set_visible(True)
for spine in ["left", "top", "right", "bottom"]:
ax.spines[spine].set_visible(False)
plt.subplots_adjust(left=0.15) # 調整左側邊距
# ax.margins(y=0.01) #縮放 zoom in
ax.set_aspect('auto')
plt.show()
def read_file():
file = open(FILE_PATH, 'r', encoding='UTF-8')
all_case_time = []
case_count = 1
cnt = 1
for line in file:
pr = fuzz.partial_ratio(line, KEY)
if pr >= threshold:
print('-----')
print(f'第{case_count}件')
case_count = case_count + 1
try:
# 正則匹配 xxxx年xx月xx日xx時xx分
mat = re.search(r'\d{4}\年\d{1,2}\月\d{1,2}\日\d{1,2}\時\d{1,2}\分', line)
t_str = mat.group().replace('\n', '') # 去掉正則匹配到但是多余的 \n 換行符
try:
object_t = datetime.strptime(t_str, "%Y年%m月%d日%H時%M分")
all_case_time.append(object_t.date()) # 日期提取出來,放到數組中
print(f'{object_t.date().strftime("%Y-%m-%d")} {object_t.weekday()}')
except:
print('解析日期失敗')
pass
except:
t_str = '-解析異常-'
pass
s = '第{number}行,相似度{ratio},時間{case_time}\n{content}'
ss = s.format(number=cnt, ratio=pr, case_time=t_str, content=line)
pp(ss)
# 快速調試
# if case_count > 100:
# break
cnt = cnt + 1
file.close()
return all_case_time
def data_frame():
ts = read_file()
times = []
for i in range(12):
times.append({SECTION: i, SUM: 0})
for t in ts:
for tx in times:
if tx[SECTION] == t.month:
tx[SUM] = tx[SUM] + 1
break
return times
def number_to_month(number):
zh = ['一', '二', '三', '四', '五', '六', '七', '八', '九', '十', '十一', '十二']
m = f'{zh[number]}月'
return m
if __name__ == '__main__':
times = data_frame()
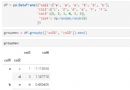
# 數據組裝成pandas數據幀。
pd_data = []
for t in times:
l = [number_to_month(t[SECTION]), t[SUM]]
pd_data.append(l)
col = ['月份', '次數']
df = pd.DataFrame(data=pd_data, columns=col)
df = df.sort_values(by=col[1], axis=0, ascending=False) # 降序
# 重置索引
df = df.reset_index(drop=True)
df.index = df.index + 1
# 前10名
pp(df.head(20))
# pp(df.values)
drawchart(df)
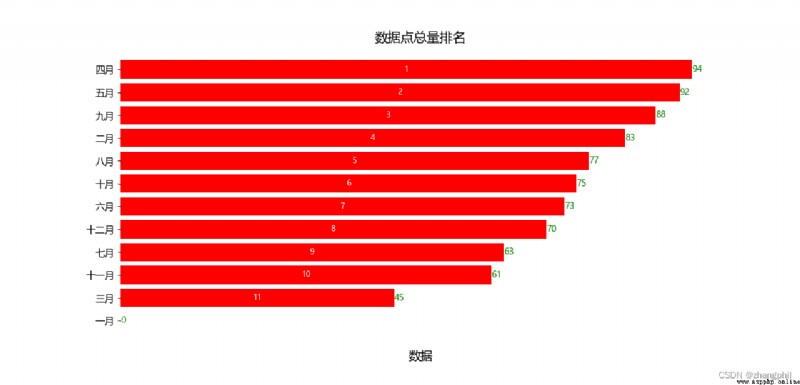
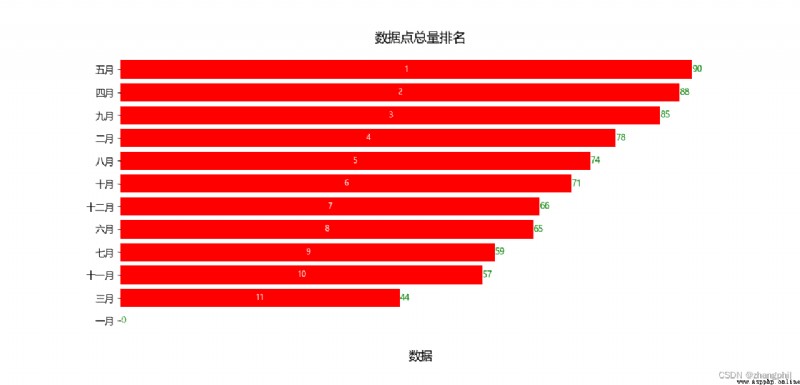
變換關鍵詞,查找後生成的統計圖: