活動地址:CSDN21天學習挑戰賽
線程 也叫輕量級進程,是操作系統能夠進行運算調度的最小單位,它被包涵在進程之中,是進程中的實際運作單位。線程自己不擁有系統資源,只擁有一點兒在運行中必不可少的資源,但它可與同屬一個進程的其他線程共享進程所擁有的全部資源。一個線程可以創建和撤銷另一個線程,同一個進程中的多個線程之間可以並發執行。
多線程 線程在程序中是獨立的、並發的執行流。與分隔的進程相比,進程中線程之間的隔離程度要小,它們共享內存、文件句柄和其他進程應有的狀態。

# 文件名 python1.py
# -*- coding:utf-8 -*-
# 線程直接使用
import threading
import time
# 需要多線程運行的函數
def fun(args):
print("我是線程%s" % args)
time.sleep(2)
print("線程%s運行結束" % args)
# 創建線程
t1 = threading.Thread(target=fun, args=(1,))
t2 = threading.Thread(target=fun, args=(2,))
start_time = time.time()
t1.start()
t2.start()
end_time = time.time()
print("兩個線程一共的運行時間為:", end_time-start_time)
print("主線程結束")
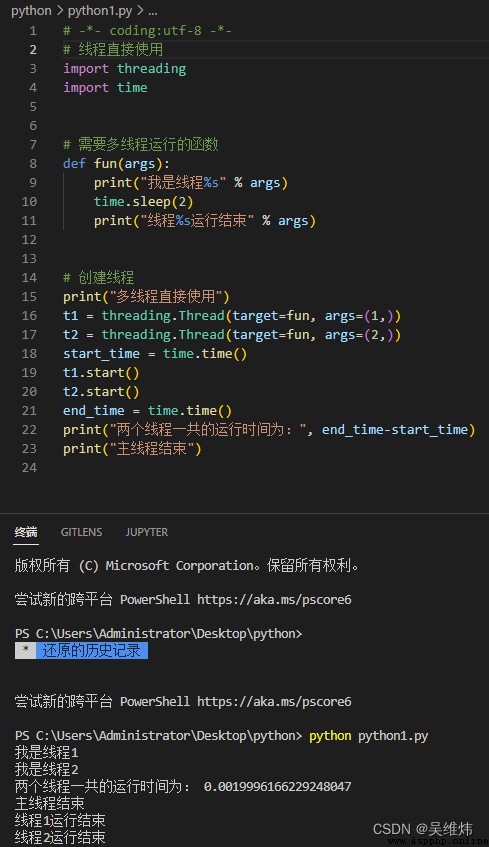
""" 執行 python python1.py 運行結果: 我是線程1 我是線程2兩個線程一共的運行時間為: 0.0019996166229248047 主線程結束 線程1運行結束 線程2運行結束 """
# 文件名 python2.py
# 繼承式調用
import threading
import time
class MyThreading(threading.Thread):
def __init__(self, name):
super(MyThreading, self).__init__()
self.name = name
# 線程要運行的代碼
def run(self):
print("我是線程%s" % self.name)
time.sleep(2)
print("線程%s運行結束" % self.name)
t1 = MyThreading(1)
t2 = MyThreading(2)
start_time = time.time()
t1.start()
t2.start()
end_time = time.time()
print("兩個線程一共的運行時間為:", end_time-start_time)
print("主線程結束")
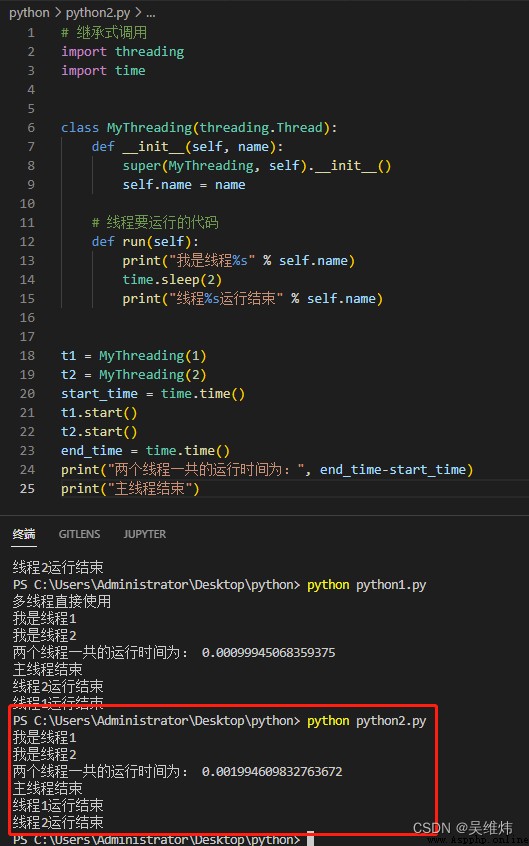
""" 執行 python python2.py 運行結果: 我是線程1 我是線程2 兩個線程一共的運行時間為: 0.0010724067687988281 主線程結束 線程2運行結束 線程1運行結束 """
Python多線程默認情況(設置線程setDaemon(False)),主線程執行完自己的任務後,就退出了,此時子線程會繼續執行自己的任務,直到子線程任務結束
代碼演示:threading中的兩個創建多線成的例子都是。
# 守護線程
import threading
import time
class MyThreading(threading.Thread):
def __init__(self, name):
super(MyThreading, self).__init__()
self.name = name
# 線程要運行的代碼
def run(self):
print("我是線程%s" % self.name)
time.sleep(2)
print("線程%s運行結束" % self.name)
t1 = MyThreading(1)
t2 = MyThreading(2)
start_time = time.time()
t1.setDaemon(True)
t1.start()
t2.setDaemon(True)
t2.start()
end_time = time.time()
print("兩個線程一共的運行時間為:", end_time-start_time)
print("主線程結束")
""" 執行 python python3.py 後續執行結果以截圖的形式呈現,文件名可自定義為xx.py,執行 python xx.py 指令即可. """
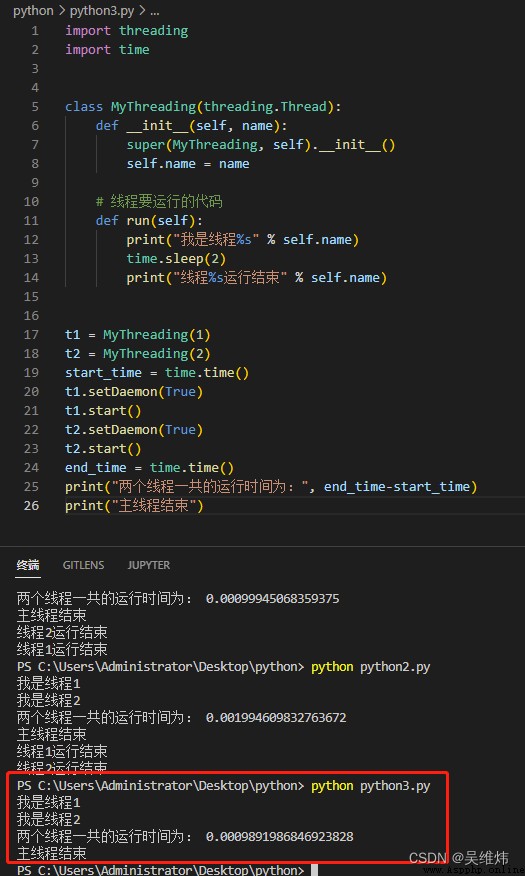
當不給程序設置守護進程時,主程序將一直等待子程序全部運行完成才結束
# join:線程同步
import threading
import time
class MyThreading(threading.Thread):
def __init__(self, name):
super(MyThreading, self).__init__()
self.name = name
# 線程要運行的代碼
def run(self):
print("我是線程%s" % self.name)
time.sleep(3)
print("線程%s運行結束" % self.name)
threading_list = []
start_time = time.time()
for x in range(50):
t = MyThreading(x)
t.start()
threading_list.append(t)
for x in threading_list:
x.join() # 為線程開啟同步
end_time = time.time()
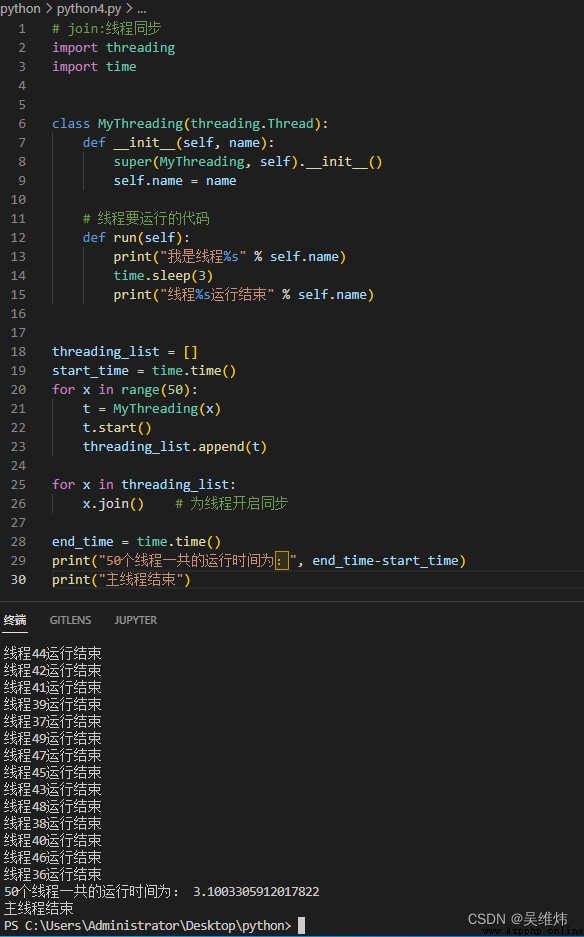
print("50個線程一共的運行時間為:", end_time-start_time)
print("主線程結束")
一個進程下可以啟用多個線程,多個線程共享父進程的內存空間,也就意味著每個線程可以訪問同一份數據。
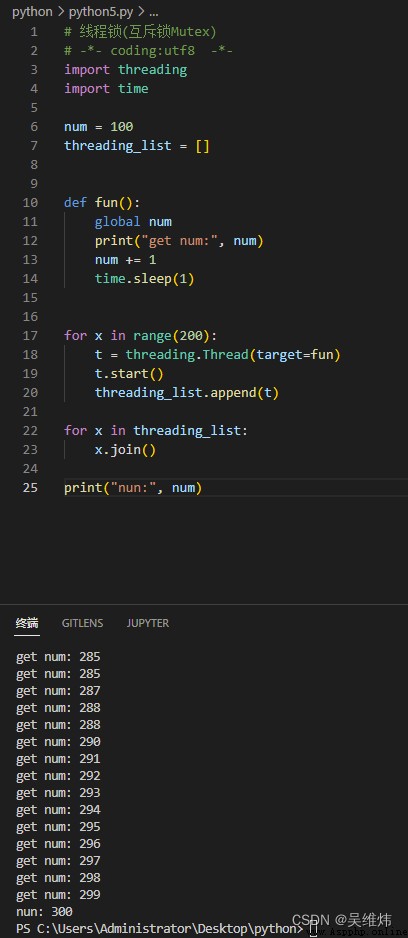
# 線程鎖(互斥鎖Mutex)
# -*- coding:utf8 -*-
import threading
import time
num = 100
threading_list = []
def fun():
global num
print("get num:", num)
num += 1
time.sleep(1)
for x in range(200):
t = threading.Thread(target=fun)
t.start()
threading_list.append(t)
for x in threading_list:
x.join()
print("nun:", num)
# RLock(遞歸鎖)
import threading, time
def run1():
lock.acquire()
print("grab the first part data")
global num
num += 1
lock.release()
return num
def run2():
lock.acquire()
print("grab the second part data")
global num2
num2 += 1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res, res2)
if __name__ == '__main__':
num, num2 = 0, 0
lock = threading.RLock()
for i in range(3):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print('----all threads done---')
print(num, num2)
注:在開發的過程中要注意有些操作默認都是 線程安全的(內部集成了鎖的機制),我們在使用的時無需再通過鎖再處理
# RLock(遞歸鎖)
import threading
data_list = []
lock_object = threading.RLock()
def task():
print("開始")
for i in range(1000000):
data_list.append(i)
print(len(data_list))
for i in range(2):
t = threading.Thread(target=task)
t.start()
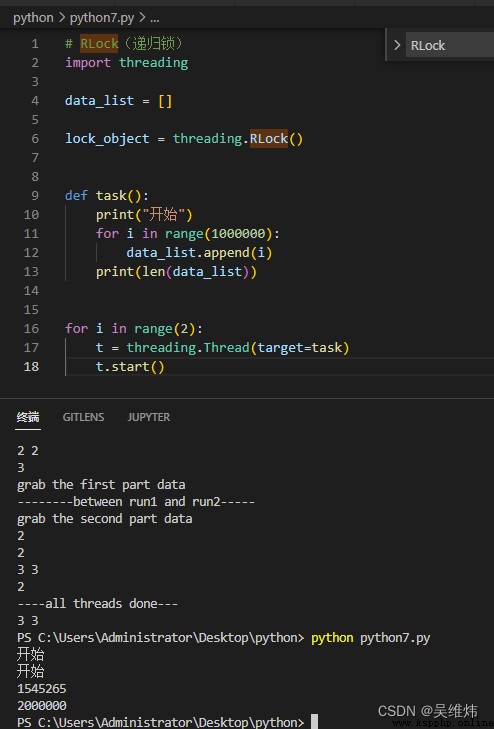
線程不是開的越多越好,開的多了可能會導致系統的性能更低了。
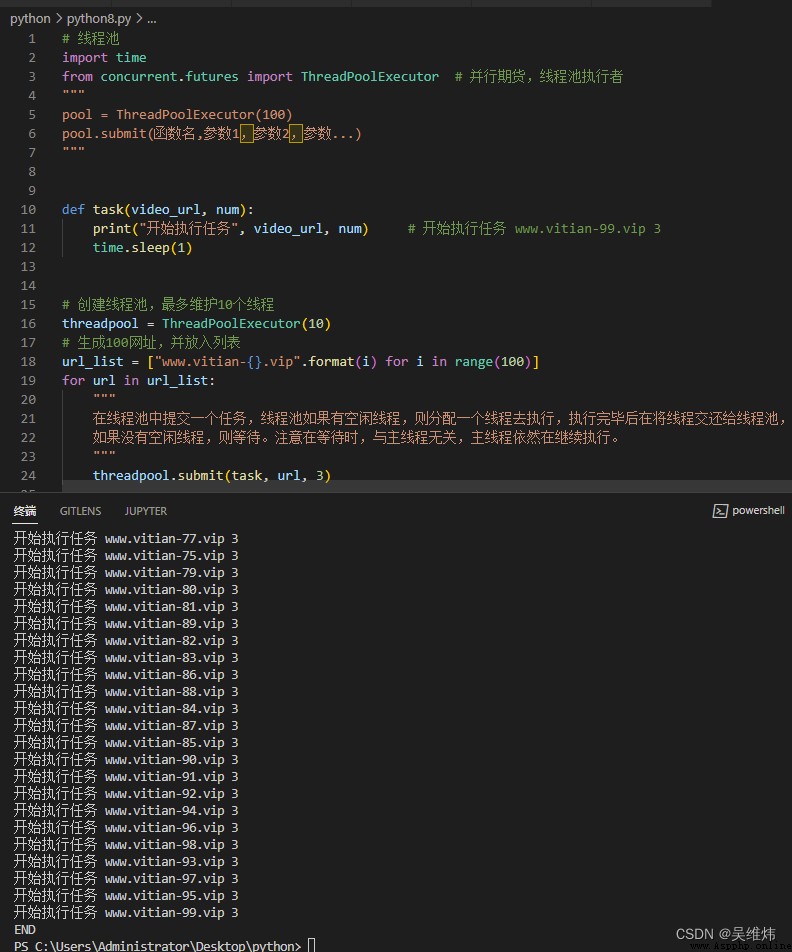
# 線程池
import time
from concurrent.futures import ThreadPoolExecutor # 並行期貨,線程池執行者
""" pool = ThreadPoolExecutor(100) pool.submit(函數名,參數1,參數2,參數...) """
def task(video_url, num):
print("開始執行任務", video_url, num) # 開始執行任務 www.vitian-99.vip 3
time.sleep(1)
# 創建線程池,最多維護10個線程
threadpool = ThreadPoolExecutor(10)
# 生成100網址,並放入列表
url_list = ["www.vitian-{}.vip".format(i) for i in range(100)]
for url in url_list:
""" 在線程池中提交一個任務,線程池如果有空閒線程,則分配一個線程去執行,執行完畢後在將線程交還給線程池, 如果沒有空閒線程,則等待。注意在等待時,與主線程無關,主線程依然在繼續執行。 """
threadpool.submit(task, url, 3)
print("等待線程池中的任務執行完畢中······")
threadpool.shutdown(True) # 等待線程池中的任務執行完畢後,在繼續執行
print("END")
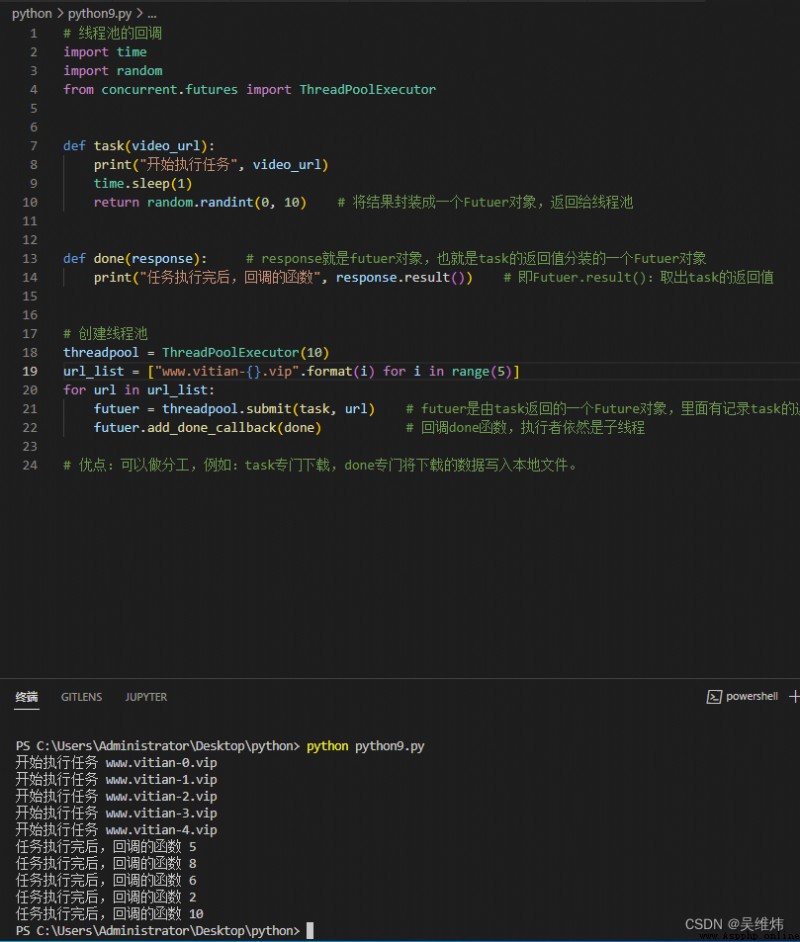
# 線程池的回調
import time
import random
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
print("開始執行任務", video_url)
time.sleep(1)
return random.randint(0, 10) # 將結果封裝成一個Futuer對象,返回給線程池
def done(response): # response就是futuer對象,也就是task的返回值分裝的一個Futuer對象
print("任務執行完後,回調的函數", response.result()) # 即Futuer.result():取出task的返回值
# 創建線程池
threadpool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(5)]
for url in url_list:
futuer = threadpool.submit(task, url) # futuer是由task返回的一個Future對象,裡面有記錄task的返回值
futuer.add_done_callback(done) # 回調done函數,執行者依然是子線程
# 優點:可以做分工,例如:task專門下載,done專門將下載的數據寫入本地文件。