公眾號:尤而小屋
作者:Peter
編輯:Peter
大家好,我是Peter~
本文主要是給大家介紹3個PandasDaily high frequency using the function:apply + agg + transform
Simulations of a simple data
In [1]:
import pandas as pd
import numpy as np
復制代碼In [2]:
df = pd.DataFrame(
{"name":["xiaoming","sunjun","jimmy","tom"],
"sex":["male","female","female","male"],
"chinese":[100,80,90,92],
"math":[90,100,88,90]
})
df
復制代碼Out[2]:
A very flexible function,To the wholeDataFrame或者SeriesTo perform a given function operation.
Function can be custom,也可以是python或者pandas內置的函數,Can also be anonymous functions.
改變字段類型:從int64變成float64
In [3]:
df.dtypes # 改變前
復制代碼Out[3]:
name object
sex object
chinese int64
math int64
dtype: object
復制代碼In [4]:
df["chinese"] = df["chinese"].apply(float)
復制代碼In [5]:
df.dtypes # 改變後
復制代碼Out[5]:
name object
sex object
chinese float64
math int64
dtype: object
復制代碼In [6]:
def change_sex(x): # male-0 female-1
return 0 if x == "male" else 1
復制代碼In [7]:
df["sex"] = df["sex"].apply(change_sex)
df # 改變後
復制代碼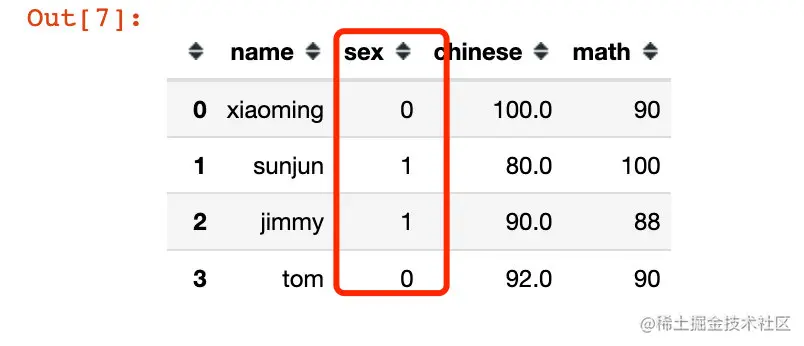
In [8]:
# float--->int
df["chinese"] = df["chinese"].apply(lambda x: int(x))
df.dtypes
復制代碼Out[8]:
name object
sex int64
chinese int64
math int64
dtype: object
復制代碼In [9]:
# 將name變成首字母大寫
df["name"] = df["name"].apply(lambda x: x.title())
df
復制代碼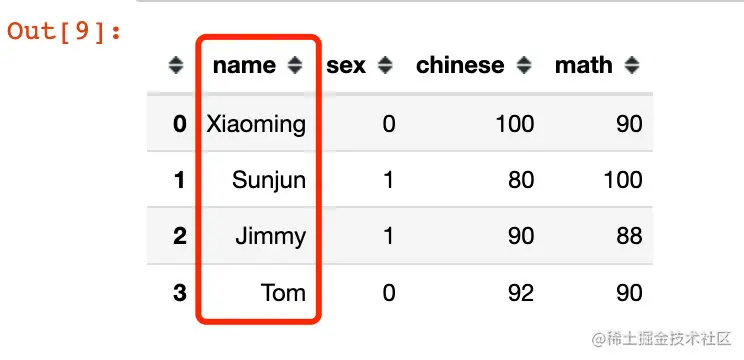
# At the same time operating two columns,記得axis=1
df["score"] = df.apply(lambda x: x["chinese"] + x["math"], axis=1)
df
復制代碼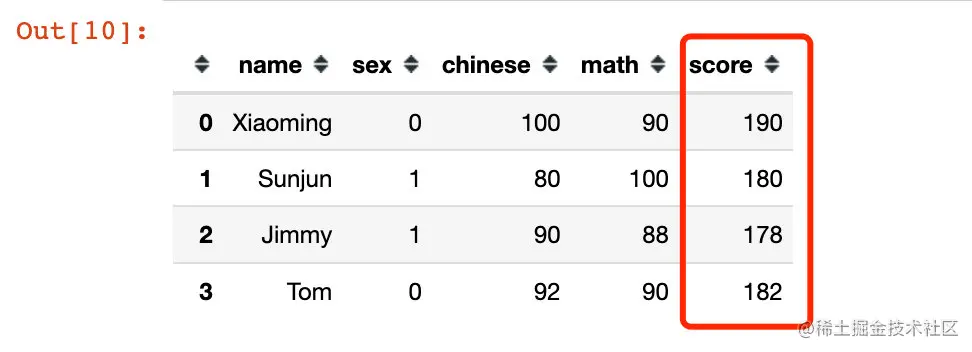
In [11]:
# 1
df["chinese"].agg(["mean", "sum"])
復制代碼Out[11]:
mean 90.5
sum 362.0
Name: chinese, dtype: float64
復制代碼In [12]:
# 2
df[["chinese","math"]].agg({"chinese":["sum"], "math":["mean"]})
復制代碼Out[12]:
In [13]:
# 3
df[["chinese","math"]].agg({"chinese":["sum","mean"], "math":["mean"]})
復制代碼Out[13]:
groupby + agg的聯合使用:
In [14]:
# 4
df.groupby("sex").agg(["mean","sum"])
復制代碼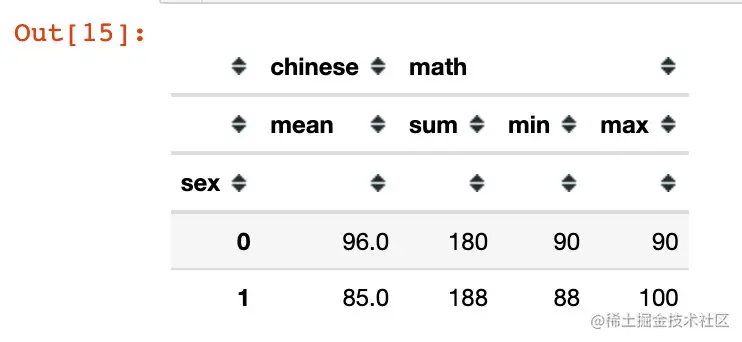
# 5
df.groupby("sex").agg({"chinese":["mean"], "math":["sum","min","max"]})
復制代碼
Can also custom newly generated field name:
df.groupby("sex").agg(chinese_mean=("chinese","mean"), math_min=("chinese","min"))
復制代碼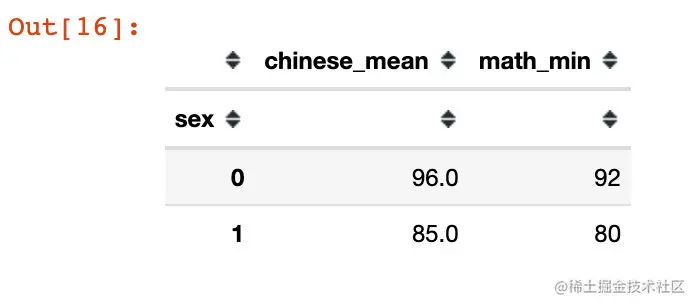
現在的df是這樣子:
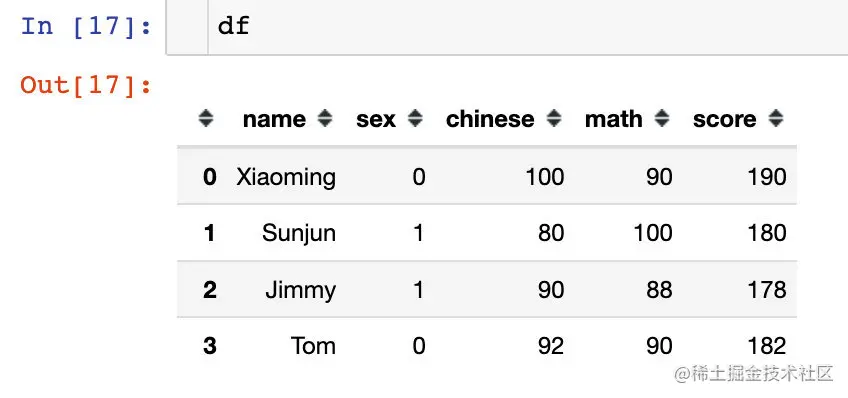
假設有一個需求:Statistical gender men and women sex 的chinese 的平均分(A new field on the back),如何實現?
In [18]:
# 1、先groupby
df1 = df.groupby("sex")["chinese"].mean().reset_index()
df1.columns = ["sex", "average"]
df1
復制代碼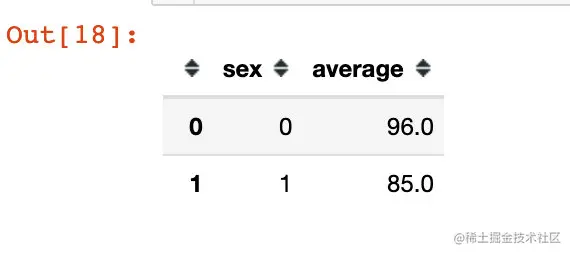
# 2、merge
# 結果
df = pd.merge(df, df1, on="sex")
df
復制代碼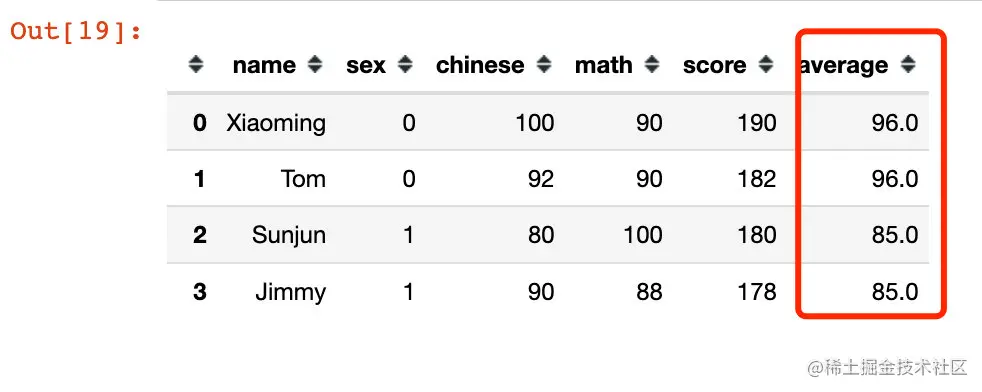
In [20]:
dic = df.groupby("sex")["chinese"].mean().to_dict()
dic
復制代碼Out[20]:
{0: 96.0, 1: 85.0}
復制代碼In [21]:
df["average_map"] = df["sex"].map(dic)
df
復制代碼
使用transform可以一步到位
df["average_tran"] = df.groupby("sex")["chinese"].transform("mean")
df
復制代碼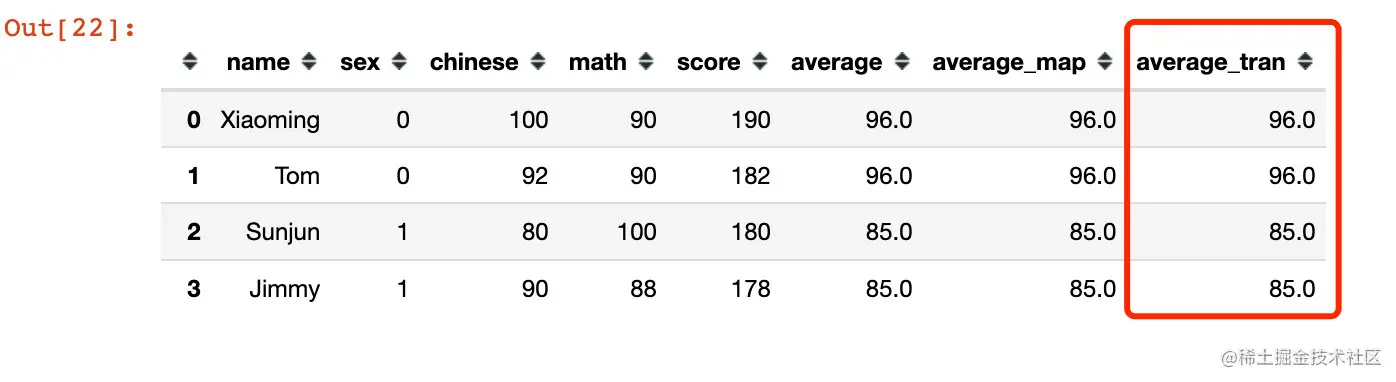
你學會了嗎?