最近在做一個ocr的項目,Mainly identification Numbers and English letters,So now trying various open source based onpython語言(其實是想在pytorch框架下使用)的ocr庫
Enclosed test images as before:
pip install easyocr
在大量warningAfter successful installation!!!
Because I mainly identification Numbers and English letters,Using the Chinese version the effect not beautiful,It calls the principle seems to beeasyocr.Reader()The first parameter to the list will only call first,After the switch to English error rate as1/14(Only with the above measure)
import easyocr
path='C:/Users/11027/Desktop/test1.jpg'
reader = easyocr.Reader(['en'],gpu = False)
result = reader.readtext(path)
print(result)
#22G1會識別成'2261'
輸出:
Using CPU. Note: This module is much faster with a GPU.
[([[307, 67], [349, 67], [349, 121], [307, 121]], '[0]', 0.2496181348819496), ([[82.817179374673, 18.268717498692013], [226.37590341350617, -1.1571357200124375], [232.182820625327, 75.73128250130799], [88.62409658649383, 95.15713572001243]], 'TBJU', 0.8707327246665955), ([[86.65181877371504, 84.3117294627456], [289.02336666519545, 60.9225513668679], [292.34818122628496, 138.6882705372544], [89.97663333480457, 162.0774486331321]], '004057', 0.9909699998969699), ([[88.96405360576286, 157.26340370189882], [224.4601580727819, 137.28127584248975], [231.03594639423716, 210.73659629810118], [96.5398419272181, 230.71872415751025]], '2261', 0.9822619656327679)]
In order not to let you see too hard,截了一個圖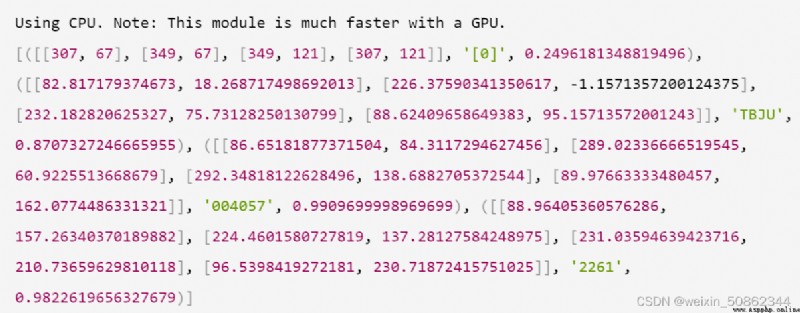
先去下載安裝包
然後在終端
pip install pytesseract
Give a piece of the installation is complete figure:
I started an error.
Didn't check the two points on the path:
①Environment path to increase the two system environment variables(To be honest I'm not sure whether the two are useful but nothing effect)
The specific variables increaseAccording to the location of the download.For example, I download location isD:\computervision\ocr\ocr_project\Tesseract-OCR.
The first is the addition of
第二個是加在path中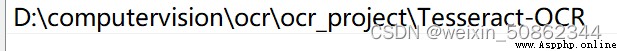
②修改pytesseract.py
This is also see their own Settings,我是直接pip install pytesseract在虛擬環境裡,So its position inD:\conda\envs\pytorch\Lib\site-packages\pytesseract
測試代碼
from PIL import Image
import pytesseract
path='C:/Users/11027/Desktop/test1.jpg'
text = pytesseract.image_to_string(path)
print(text)
Big to send!Didn't recognize anything to(是有效的,But not as for the English character and digital effects)
Retraining is too much trouble to skip
下載的話:
pip3 install cnocr -i https://mirrors.aliyun.com/pypi/simple/
會有一堆warning,但是不影響!
And then for differentocrTasks have different solutions,Specific can see officialgithub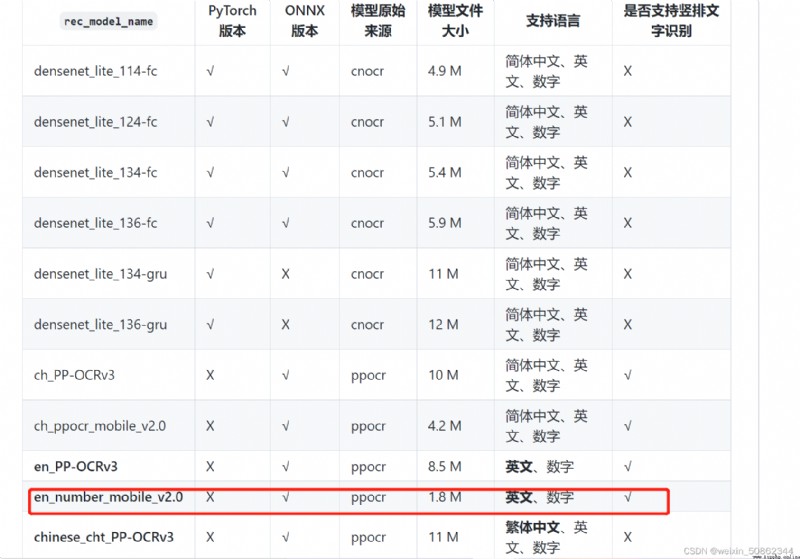
我用的是1.8MThe but it is still compares the other open sourceocrEffect of library is the most sweet
from cnocr import CnOcr
path='C:/Users/11027/Desktop/test1.jpg'
ocr = CnOcr(rec_model_name='en_number_mobile_v2.0')
out = ocr.ocr(path)
print(out)
# import testcnocr
# print(cnocr.__file__)
All can identify to!!!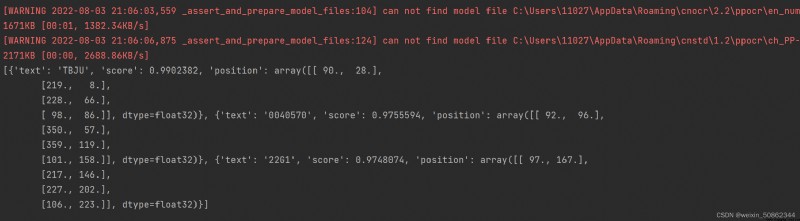
In fact I at first also quote a wrong:太蠢了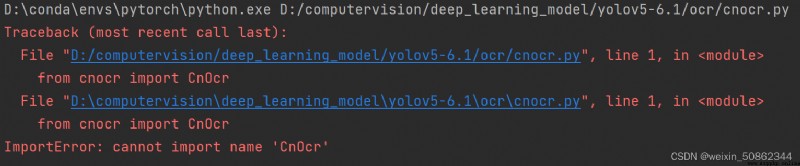
錯因:I put the test file namedcnocr了
Have to say that if it weren't forpaddleocr在paddle框架下,我覺得paddleocrThe overall effect is the best,當然cnocr也不錯!