活動地址:CSDN21天學習挑戰賽
以下是關於Python~Jsonpath庫的使用
🥧 續Urllib之Jsonpath庫的使用點擊跳轉到Urllib文章
🥧快,跟我一起爬起來
The more reptiles crawl, the better

JSONPath是一種Information extraction class library,是從JSON文檔中抽取指定信息的工具,提供多種語言實現版本,包括:Javascript, Python,PHP 和 Java,JsonPath 對於 JSON 來說,相當於 XPath 對於 XML.
Want to climb something? 數據類型 找接口 爬取數據

Json結構清晰,比 XML 簡潔得多,可讀性高,復雜度低,非常容易匹配,It is very intuitive to understand what is stored,如圖所示.
官網:https://goessner.net/articles/JsonPath/
注意:openThe method is downloaded by defaultgbk的編碼,If we were to download save the sweat word,那麼需要在open方法中指定編碼格式
Ⅰ爬取jsonData formatted datactrl + alt +L
ⅡThere are two ways to download data to the local:
方法1、 fs=open(保存的文件名,’類型‘,’等‘)
fs.write(要寫入 或 要讀取數據)
方法2、 with open(保存的文件名,’類型‘,‘等’) as fs:
fs.write(要寫入 或 要讀取數據)

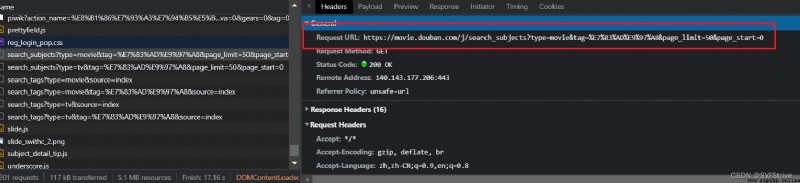
3. Find the interface and you can climb
代碼演示:
import urllib.request
//地址
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=%E5%8A%A8%E4%BD%9C'
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}
//1、請求頭的定制
request = urllib.request.Request(url=url, headers=headers)
//2、獲取響應數據
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
//3、將數據下載到本地
with open('6、python之urllib_ajax_get請求_爬電影/doBan.json', 'w', encoding='utf-8') as fs:
fs.write(content)
如下圖(爬取成功):
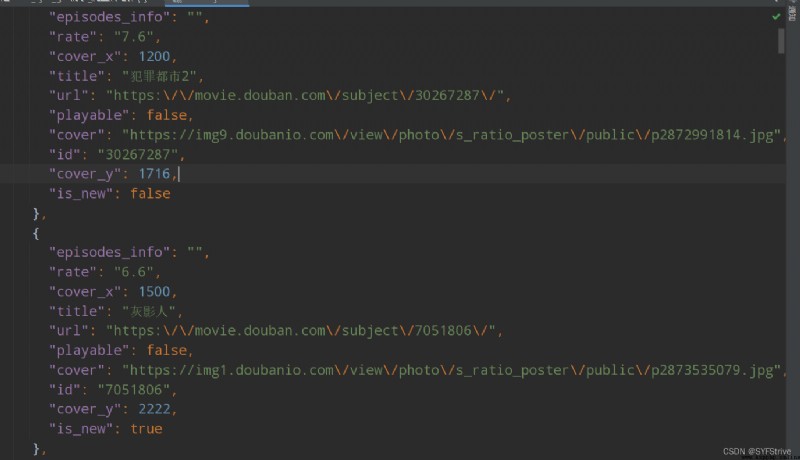
Get up with me now

步驟:Find the page numbering pattern
When I scroll down, I will find that the data is constantly updated(利用Axios技術)
At the same time, we get the interface for refreshing data 如
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=%E5%8A%A8%E4%BD%9C
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20&genres=%E5%8A%A8%E4%BD%9C
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=40&genres=%E5%8A%A8%E4%BD%9C
我們可以發現 如(So start here)
start=0
start=20
start=40
代碼演示:
import urllib.request
import urllib.parse
# 第一、請求對象的定制
def create_request(page):
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&'
url1 = '&genres=%E5%8A%A8%E4%BD%9C'
index = 20 //One page and twenty movies
data = {
'start': (page - 1)*index
}
data = urllib.parse.urlencode(data) //這裡不是post請求 所以不用encode(‘utf-8’)
url = url + data + url1 //拼接路徑
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
return request
# 第二、獲取響應數據
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 第三、下載數據
def download(c, content):
with open('6、python之urllib_ajax_get請求_爬電影/doBanS' + str(page) + '.json', 'w', encoding='utf-8') as fs:
fs.write(content)
# 程序入口
if __name__ == '__main__': // Simple understanding in order to prevent other programs from calling the module,trigger other actions
start_page = int(input("請輸入起始頁"))
end_page = int(input("Please enter the end page"))
//左閉右開+1
for page in range(start_page, end_page + 1):
Request custom return data
request = create_request(page)
Get response data return data
content = get_content(request)
下載數據
download(page, content)
如下圖(爬取成功):
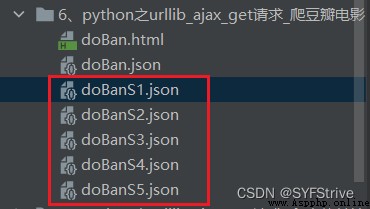
Get up with me now

步驟:Find the page numbering pattern
When I click on the next page, I will find that the data page changes
At the same time, we get the interface for refreshing data 如
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
cname: 汕頭
pid:
pageIndex: 1
pageSize: 10
http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
cname: 汕頭
pid:
pageIndex: 2
pageSize: 10
我們可以發現 如(So start here)
pageIndex: 1
pageIndex: 2
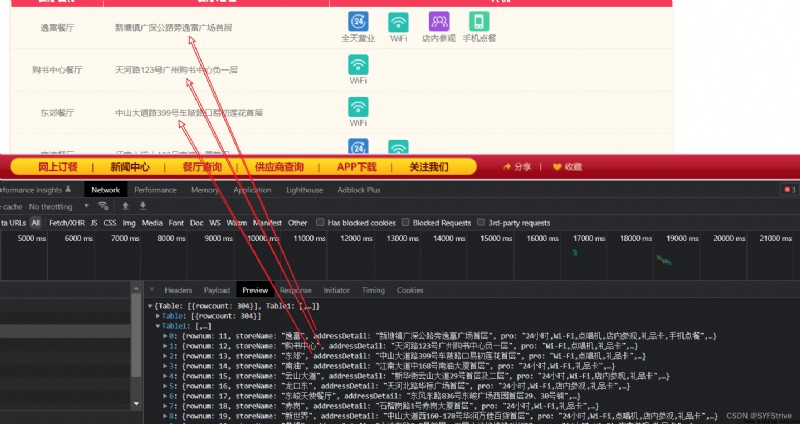
代碼演示:
import urllib.request
import urllib.parse
import json
# 第一、請求對象的定制
def create_request(page):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '廣州',
'pid': ' ',
'pageIndex': page,
'pageSize': '10',
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/102.0.0.0 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers, data=data)
return request
# 第二、獲取響應數據
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# 反序列化
result = str(json.loads(content)['Table1']).replace("'", '"')
return result
# 第三、下載數據
def download(page, content):
with open('7、python之urllib_ajax_get請求_Crawling address_前十頁/kfc' + str(page) + '.json', 'w', encoding='utf-8') as fs:
fs.write(content)
# 程序入口
if __name__ == '__main__':
start_page = int(input("請輸入起始頁"))
end_page = int(input("請輸入起始頁"))
for page in range(start_page, end_page + 1):
request = create_request(page)
content = get_content(request)
download(page, content)
如下圖(爬取成功):



安裝:pip intsall jsonpath(Since the library is small, mirroring can be omitted)
推薦一篇不錯的文章:點擊跳轉
JsonPathData to crawl
{
"firstName": "John",
"lastName": "doe",
"age": 26,
"address": {
"streetAddress": "naist street",
"city": "Nara",
"postalCode": "630-0192"
},
"phoneNumbers": [
{
"type": "iPhone",
"number": "0123-4567-8888"
},
{
"type": "home",
"number": "0123-4567-8910"
},
{
"type": "home"
}
]
}
代碼演示:
import json
import jsonpath
obj = json.load(open('jsonPath.json', 'r', encoding='utf-8'))
request = jsonpath.jsonpath(obj, '$.address.')
request1 = jsonpath.jsonpath(obj, '$.phoneNumbers[*]')
request2 = jsonpath.jsonpath(obj, '$.phoneNumbers[*]..type')
request3 = jsonpath.jsonpath(obj, '$.phoneNumbers[(@.length-3)]')
request4 = jsonpath.jsonpath(obj, '$.phoneNumbers[0,2]')
request5 = jsonpath.jsonpath(obj, '$.phoneNumbers[0:]')
request6 = jsonpath.jsonpath(obj, '$.phoneNumbers[?(@.type)]')
# 爬取地址
print(request)
# Crawl all phone information
print(request1)
# Crawl all names
print(request2)
# Climb the [email protected]個
print(request3)
# Crawl the penultimate and second to give
print(request4)
# 獲取從0data after the start
print(request5);
# 條件過濾
# Crawl hastype的數據
print(request6)
如下圖(獲取想要的數據):


代碼演示:
import urllib.request
import jsonpath
import json
url = "https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1659517543500_108&jsoncallback=jsonp109&action" \
"=cityAction&n_s=new&event_submit_doGetAllRegion=true "
headers = {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh,zh-CN;q=0.9,en;q=0.8',
'bx-v': '2.2.2',
'cookie': 't=b4c2e30684a007ae1b99fcc29f106fbc; cookie2=1861202b7779067257f60da8045ea2bc; v=0; _tb_token_=e88733b173ee1; cna=LyhxGzY8sCMCAbcHsQ0Ms5ot; xlly_s=1; tfstk=cQFdBAZwwGjnRgkjFyBiUYLTdC7cZiLKqeiJw7owg7LVt2ARiYN0MVhCd4oqvNC..; l=eBjmQEz7L7nUI0y8BOfwlurza77tcIRAguPzaNbMiOCP_LCH7F9cW6xwE18MCnGNh62JR3Wrj_IwBeYBqC2sjqj2nAHOrKHmn; isg=BM7Oll5OINPphJT3EqpdZWGYH6SQT5JJT641pPgXXVGUW261YN46WUYVk483w4ph',
'referer': 'https://dianying.taobao.com/index.htm?n_s=new',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
content = content.split('(')[1].split(')')[0]
with open('Tickets flutter.json', 'w', encoding='utf-8') as fs:
fs.write(content)
results = json.load(open('Tickets flutter.json', 'r', encoding='utf-8'))
receive =str(jsonpath.jsonpath(results, '$..regionName'))
print(receive)
with open('Amoy ticket area.text', 'w', encoding='utf-8') as fs:
fs.write(receive)
如下圖(獲取數據成功):

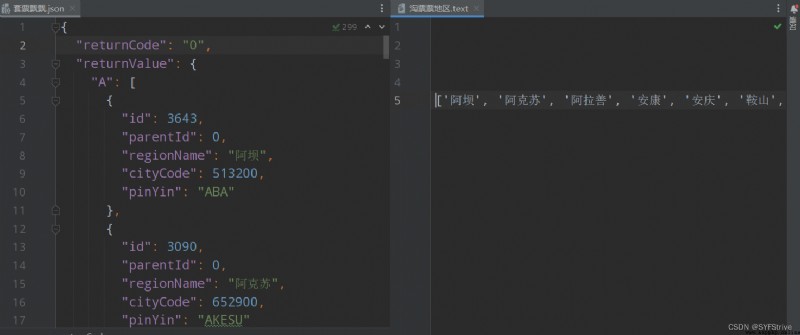

本文章到這裡就結束了,If you think it's good, please subscribe to my column,你的支持是我們更新的動力,感謝大家的支持,希望這篇文章能幫到大家
點擊跳轉到我的Python專欄

下篇文章再見ヾ( ̄▽ ̄)ByeBye