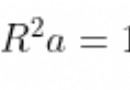目錄
一、學習資源
二、知識點介紹
1、scrapy介紹
2、scrapy安裝與錯誤解決
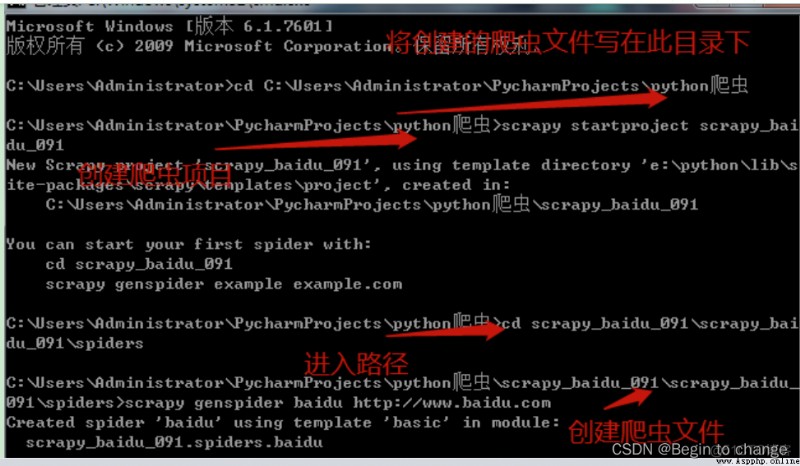
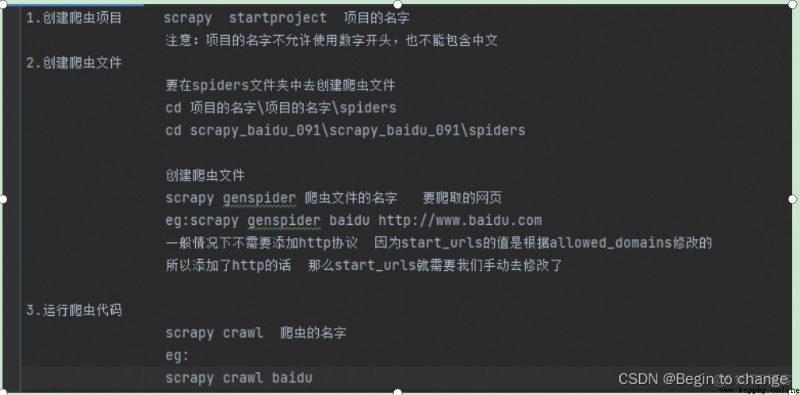
3、scrapy基本使用
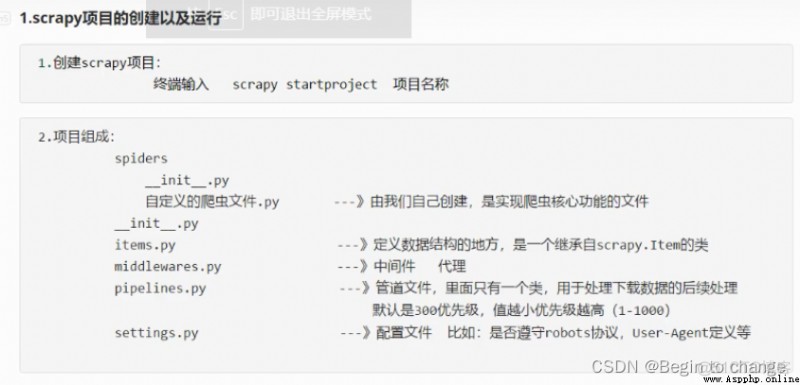
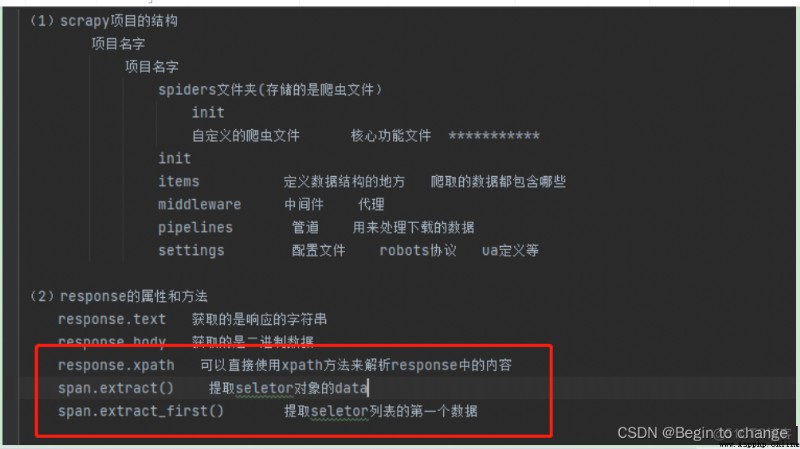
4、項目結構和基本方法
(1)實例:
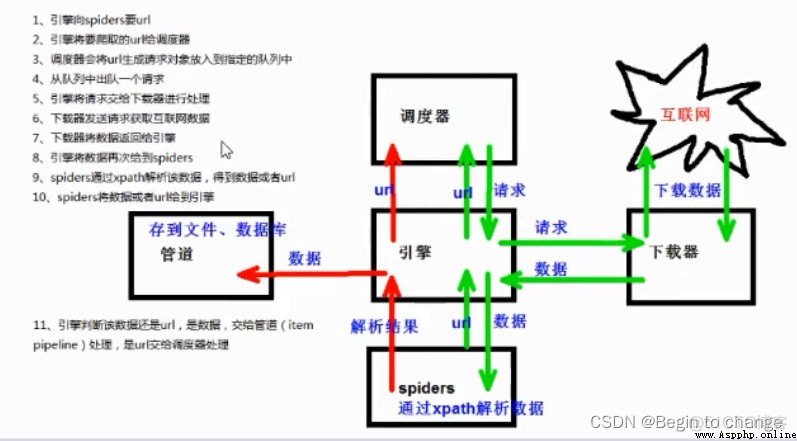
5、架構組成
6、scrapy工作原理
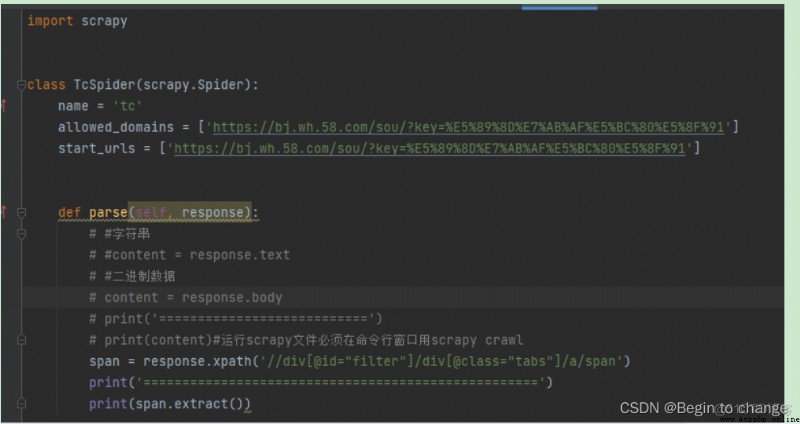
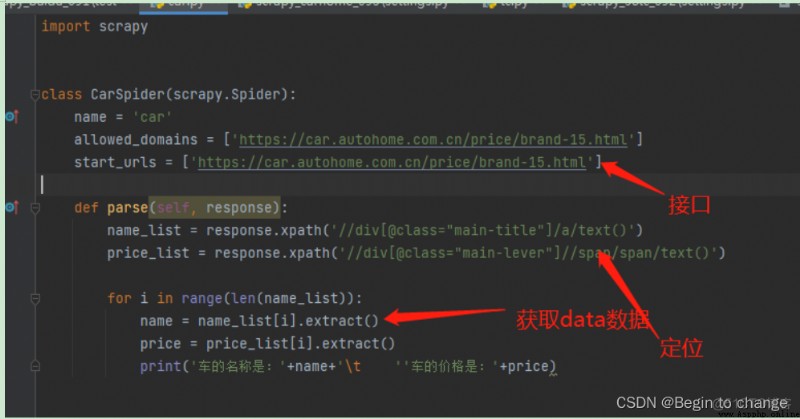
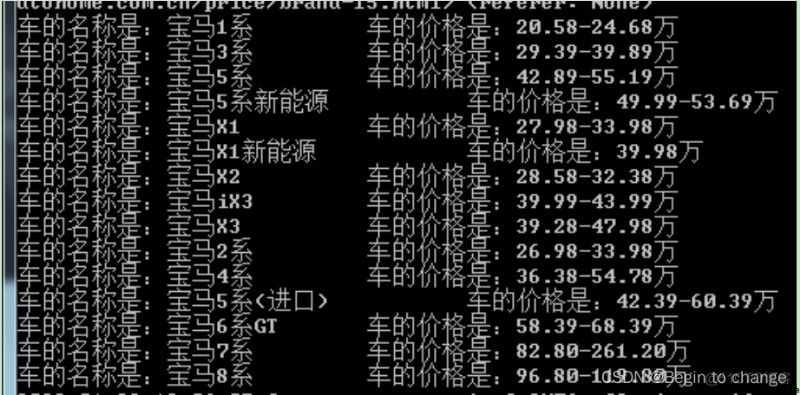
(2)實例:汽車之家
三、項目分析
(1)首先定位到要獲取的數據的標簽的屬性
(2)獲取數據
(3)檢查
問題①
原因及解決辦法
問題②
原因及解決辦法
(4)下載(單個管道)
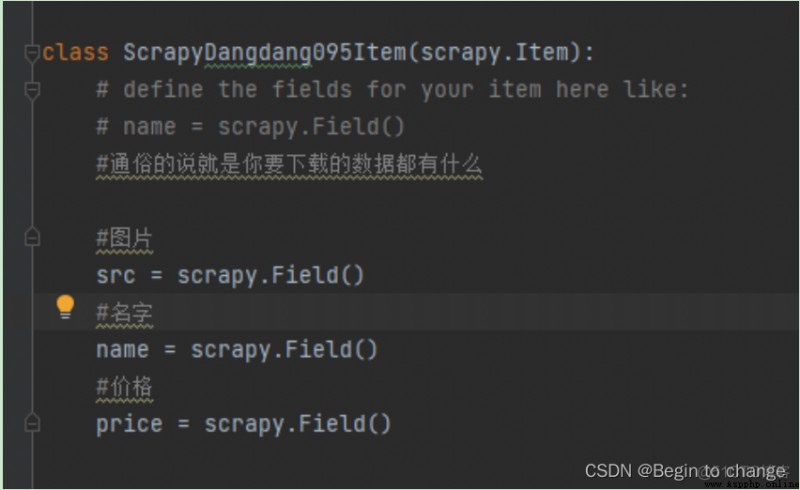
①先定義數據結構(items程序)
②管道下載
③下載數據到文件中
(5)多個管道下載
①定義管道類
②在settings中開啟管道
(6)多個管道下載實現
四、項目源碼

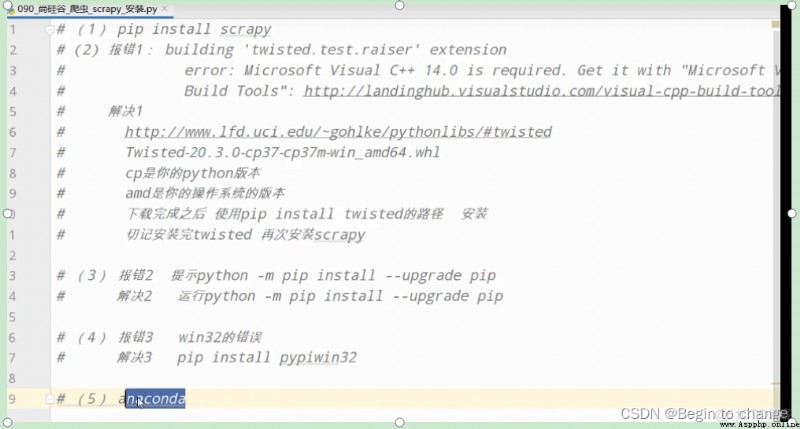


上一個案例用的是把所有的數據下下下來保存到一個列表中,然後再通過遍歷的方式去一個一個收數據的取,這裡介紹一個新的方法:seletor對象可以再次調用xpath方法,也就是說先把統一的路徑給分離出來,然後再調用xpath。
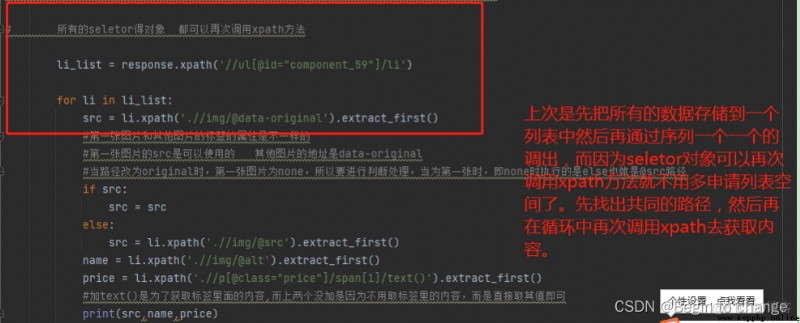
所有的圖片路徑都是一樣的
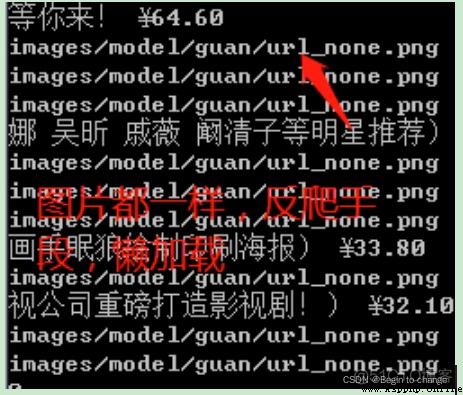
這是一種常見的反爬手段,圖片的懶加載,即圖片的真正路徑不是@src了(除了第一個以外),發現問題之後再去檢查網頁,發現除第一個以外的圖片路徑為@data-original。
第一次路徑:

之後的路徑:


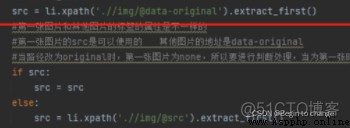
當把路徑改為@data-original之後,發現第一張圖片為none
檢查之後發現其實第一章圖片的位置沒有變,只是後面的懶加載所以變了,所以此處要進行判斷。當是第一張圖片的時候路徑就為@src,其它情況為@data-original。
(1)先在settings中開啟管道 解開ITEM_PIPELINES的注釋
(2)將獲取的值傳入管道中

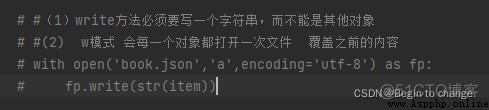
注:這種模式不推薦 因為每傳遞過來一個對象 那麼打開一個文件 對文件的操作過於頻
改進:

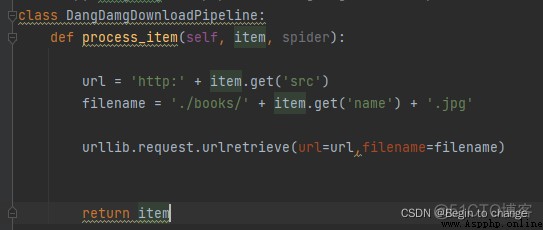
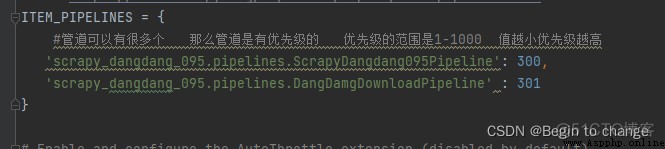
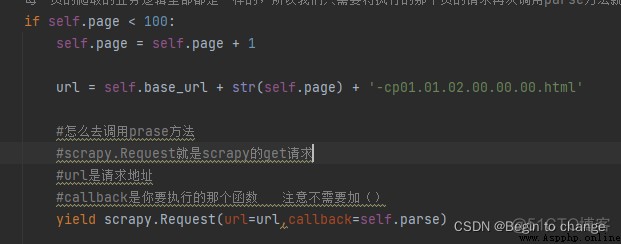
每一頁的爬取的業務邏輯全部都是一樣的,所以我們只需要將執行的那個頁的請求再次調用parse方法就可以了(注意頁碼的變化),頁碼的變化會引起url的變化,這是需要注意的點

此項目包含多個函數和文件,需要源碼的評論區留言即可。