參考書目:《深入淺出Pandas:利用Python進行數據處理與分析》
分類數據可以進行分組,然後分組進行統計計算。
讀取案例數據
import numpy as np
import pandas as pd
data = 'https://www.gairuo.com/file/data/dataset/team.xlsx'
df = pd.read_excel(data) groupby參數用法
df.groupby(self, by=None, axis=0, level=None,
as_index: bool=True, sort: bool=True,
group_keys: bool=True,
squeeze: bool=False,
observed: bool=False, dropna=True)df.groupby('team').sum() # 按團隊分組對應列相加
df.groupby('team').mean() # 按團隊分組對應列求平均
# 不同列不同的計算方法
df.groupby('team').agg({'Q1': sum, # 總和
'Q2': 'count', # 總數
'Q3':'mean', # 平均
'Q4': max}) # 最大值
df.groupby('team').agg({'Q1': [sum,'std',max] # 三個方法
'Q2': 'count', # 總數
'Q3':'mean', # 平均
'Q4': max}) # 最大值
#如果按一列聚合,只傳列名字符串,如果多個就要傳由列名組成的列表
#聚合方法可以使用 Pandas 的數學統計函數 或者 Numpy 的統計函數
#如果是 python 的內置統計函數,直接使用變量,不需要加引號
#如果需要將空值也進行聚合,需要傳入 dropna=Flasedf.groupby('team')
df.Q1.groupby('team')
grouped=df.groupby('col')
grouped=df.groupby('col',axis='columns')
grouped=df.groupby(['col1','col2'])
###分組用法
grouped=df.groupby('team')
grouped.get_group('D')
grouped2=df.groupby(['team',df.name.str[0]])
grouped2.get_group('B','H') #B組,名字H開頭
df.groupby('team').groups #查看分組內容(字典)
grouped.groups.indices #組名為鍵,組內索引為數組的字典
dgrouped.groups.keys() #查看分組名
grouped.Q1
grouped[['Q1','Q2']]
for name,group in grouped:
print(name) #組名str
print(group)#df### 將數據分為兩組
df.groupby(lambda x:x%2==0).sum() #索引是否為偶數分為兩組
df.groupby(df.index%2==0).sum()
df.groupby(lambda x:x>50) #索引是否大於50
df.groupby(df.index>=50).sum()
df.groupby(lambda x:'Q' in x ,axis=1).sum() #列名含有Q的
#其他篩選
df.groupby(df.index%2==0) #奇偶列
df.groupby(df.name.str[0]) #姓名首字母
df.groupby(df.team.isin(['A','B'])) #A和B,其他,分組
df.groupby([df.name.str[0],df.name.str[1]]) #姓名的第一二個字母
df.groupby([df.time.date,df.time.hour]) #日期小時分組df.groupby(df.time.apply(lambda x:x.year)).count() #從時間列time中提取年份來分組#案例 ,按姓名的首字母為元音,輔音分組
def get_letter_type(letter):
if letter[0].lower() in 'aeiou':
return '元音'
else:
return '輔音'
df.set_index('name').groupby(get_letter_type).sum()
df.groupby(['team',df.name.apply(get_letter_type)]).sum()
#Groupby 操作後分組字段會成為索引,如果不想讓它成為索引,可以使用 as_index=False 進行設置
#不想排序使用 sort=False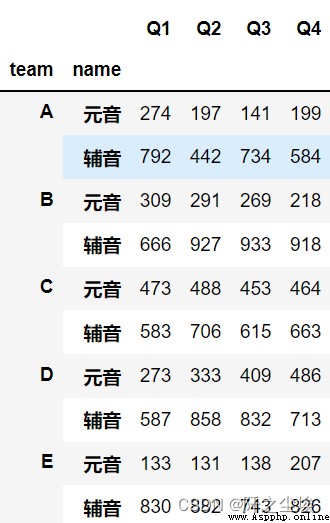
#調用pipe分組用法
df.pipe(pd.DataFrame.groupby,'team').sum()df.groupby('team').apply(lambda x: x*2)
df.groupby('team').apply(lambda x: x['name'].to_list()) #分組一列輸出為列表
df.groupby('team').apply(lambda x: x['name'].to_list()).A #查看某個組
df.name.groupby('team').apply(np.array) # 輸出一個 np.array# 各組 Q1(為參數) 成績的前3個
def first_5(df_, c):
return df_[c].sort_values(ascending = False).head(3)
# 調用函數
df.set_index('name').groupby('team').apply(first_5, 'Q1')
# group_keys 可以使分組字段不做為索引
df.set_index('name').groupby('team', group_keys=False).apply(first_5, 'Q1')df.groupby('team').mean()
df.groupby('team').mean().mean(1)
df.groupby('team').filter(lambda x:x.mean(1).mean()>51) #篩選所在組總平均分大於51的人
df.groupby('team').filter(lambda x: len(x) >= 3) # 值的長度都大於等於 3 的
df.groupby(['team']).filter(lambda x: (x['Q1'] > 97).any()) # Q1成績只要有一個大於97的組
df.groupby(['team']).filter(lambda x: (x.mean() >= 60).all())# 所有成員平均成績大於 60 的組
df.groupby('team').filter(lambda g: g.Q1.sum() > 1060) # Q1 所有成員成績之和超過 1060 的組df.groupby('team').first() # 組內第一個
df.groupby('team').last() # 組內最後一個
df.groupby('team').ngroups # 5 (分組數)
df.groupby('team').ngroup() # 分組序號
grouped=df.groupby('team')
grouped.backfill()
grouped.bfill()
grouped.head(2)#每組前2個
grouped.tail(1)#每組最後一個
grouped.rank() #組內排序值
grouped.fillna(0)
#分組中第幾個值
grouped.nth(1)#第一個
grouped.nth(-1)#最後一個
grouped.nth([2,-1])
grouped.shift(-1)#組內移動
grouped.tshift(1)#時間周期移動#僅series可用 返回還有索引
grouped.Q1.nlargest(2) #每組最大兩個
grouped.Q1.nsmallest(3) #每組最小兩個
grouped.Q1.nunique() #每組去重數量
grouped.Q1.unique() #每組去重值
grouped.Q1.value_counts() #每組值種類和數量統計
grouped.Q1.is_monotonic_increasing #每組是否單調遞增
grouped.Q1.is_monotonic_decreasing #每組是否單調遞減
#僅df
grouped.corrwith(df2) #計算相關性
df.groupby('team').describe() # 描述性統計
df.groupby('team').sum() # 求和
df.groupby('team').count() # 每組數量,不包括缺失值
df.groupby('team').max() # 求最大值
df.groupby('team').min() # 求最小值
df.groupby('team').size() # 分組數量
df.groupby('team').mean() # 平均值
df.groupby('team').median() # 中位數
df.groupby('team').std() # 標准差
df.groupby('team').var() # 方差
grouped.corr() # 相關性系數
grouped.sem() # 標准誤差
grouped.prod() # 乘積
grouped.cummax() # 每組的累計最大值
grouped.cumsum() # 累加
grouped.mad() # 平均絕對偏差
grouped.median()#中位數
grouped.quantile()#中位數
grouped.quantile(0.75)#四分位
grouped.diff() #組內前後差值# 所有列使用一個計算計算方法
df.groupby('team').aggregate(sum)
df.groupby('team').agg(sum)
grouped.agg(np.size)
grouped['Q1'].agg(np.mean)
# 所有列指定多個計算方法
grouped.agg([np.sum, np.mean, np.std])
# 指定列使用多個計算方法
grouped[['Q1','Q3']].agg([sum, np.mean, np.std])
# 一列使用多個計算方法
df.groupby('team').agg({'Q1': ['min', 'max'], 'Q2': 'sum'})
# 指定列名,列表是為原列和方法
df.groupby('team').Q1.agg(Mean='mean', Sum='sum')
df.groupby('team').agg(Mean=('Q1', 'mean'), Sum=('Q2', 'sum'))
df.groupby('team').agg(Q1_max=pd.NamedAgg(column='Q1', aggfunc='max'),
Q2_min=pd.NamedAgg(column='Q2', aggfunc='min'))
# 如果列名不是有效的 python 變量,則可以用以下方法
df.groupby('team').agg(**{'1_max':pd.NamedAgg(column='Q1', aggfunc='max')})# lambda/函數 所有方法都可以用
def max_min(x):
return x.max() - x.min() # 定義函數
df.groupby('team').agg(max_min)
df.groupby('team').Q1.agg(Mean='mean',
Sum='sum',
Diff=lambda x: x.max() - x.min(),
Max_min=max_min)
# 不同列不同的計算方法
df.groupby('team').agg({'Q1': sum, # 總和
'Q2': 'count', # 總數
'Q3':'mean', # 平均
'Q4': max}) # 最大值
idx = pd.date_range('1/1/2000', periods=100, freq='T')
df2 = pd.DataFrame(data=1 * [range(2)],index=idx,
columns=['a', 'b'])
# 三個周期一聚合(一分鐘一個周期)
df2.groupby('a').resample('3T').sum()
# 30 秒一分組
df2.groupby('a').resample('30S').sum()
# 每月
df2.groupby('a').resample('M').sum()
# 以右邊時間點為標識
df2.groupby('a').resample('3T', closed='right').sum()pd.cut(df.Q1, bins=[0, 60, 100]) #將Q1成績分成兩個區間
df.Q1.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count() #變成分類變量然後分組統計
df.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count() #整個數據框分組
pd.cut(df.Q1, bins=[0, 60, 100],labels=False) # 不顯示區間,使用數字做為標簽(0,1,2,n)
pd.cut(df.Q1, bins=[0, 60, 100],labels=['不及格','及格',]) # 指定標簽名
pd.cut(df.Q1, bins=[0, 60, 100], include_lowest=True) # 包含最低部分
pd.cut(df.Q1, bins=[0, 89, 100], right=False) # 是否包含右邊,閉區間,下例 [89, 100)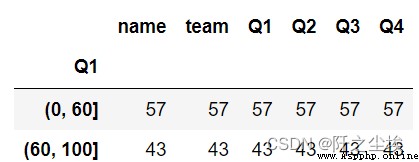
#不同分數映射案例
df3 = pd.DataFrame({'A':[1, 3, 5, 7, 9]})
df3.assign(B=pd.cut(df3.A, [0,5,7, float('inf')], labels=['差','中','好']))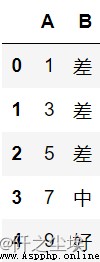
pd.qcut(df.Q1,q=2) #自動分為2組,且樣本長度相同
pd.qcut(df.Q1,q=2).unique()
pd.qcut(df.Q1,q=3).value_counts()
df.groupby(pd.qcut(df.Q1,2)).count() #應用到分組上
#其他參數
pd.qcut(range(5), 4)
pd.qcut(range(5), 4, labels=False)
# 指定標簽名
pd.qcut(range(5), 3, labels=["good", "medium", "bad"])
# 返回箱子標簽 array([ 1. , 51.5, 98. ]))
pd.qcut(df.Q1,q=2, retbins=True)
# 分箱位小數位數
pd.qcut(df.Q1,q=2,precision=3)
# 排名分3個層次
pd.qcut(df.Q1.rank(method='first'),3)
grouped=df.set_index('name').groupby('team')
grouped.plot(figsize=(4,0.8))
grouped.hist() #直方圖hist()
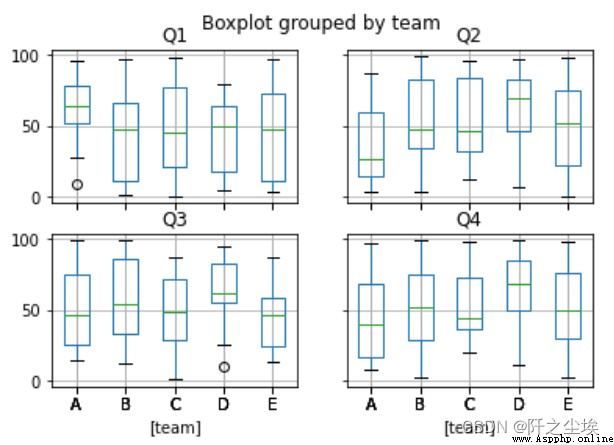
grouped.boxplot()#箱線圖
##或者是
df.boxplot(by='team')