編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
# helloworld示例 import paddle.fluid as fluid # 創建兩個類型為int64, 形狀為1*1張量 x = fluid.layers.fill_constant(shape=[1], dtype="int64", value=5) y = fluid.layers.fill_constant(shape=[1], dtype="int64", value=1) z = x + y # z只是一個對象,沒有run,所以沒有值 # 創建執行器 place = fluid.CPUPlace() # 指定在CPU上執行 exe = fluid.Executor(place) # 創建執行器 result = exe.run(fluid.default_main_program(), fetch_list=[z]) # 返回哪個結果 print(result) # result為多維張量
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯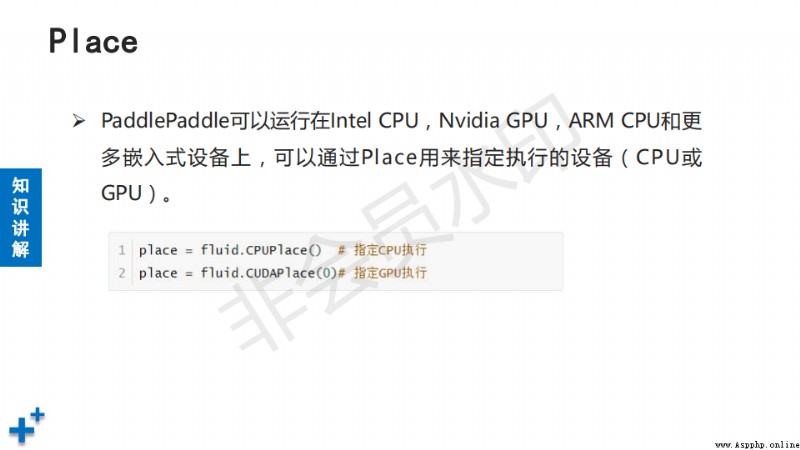
 編輯
編輯
 編輯
編輯
 編輯
編輯
import paddle.fluid as fluid
import numpy
# 創建x, y兩個2行3列,類型為float32的變量(張量)
x = fluid.layers.data(name="x", shape=[2, 3], dtype="float32")
y = fluid.layers.data(name="y", shape=[2, 3], dtype="float32")
x_add_y = fluid.layers.elementwise_add(x, y) # 兩個張量按元素相加
x_mul_y = fluid.layers.elementwise_mul(x, y) # 兩個張量按元素相乘
place = fluid.CPUPlace() # 指定在CPU上執行
exe = fluid.Executor(place) # 創建執行器
exe.run(fluid.default_startup_program()) # 初始化網絡
a = numpy.array([[1, 2, 3],
[4, 5, 6]]) # 輸入x, 並轉換為數組
b = numpy.array([[1, 1, 1],
[2, 2, 2]]) # 輸入y, 並轉換為數組
params = {"x": a, "y": b}
outs = exe.run(fluid.default_main_program(), # 默認程序上執行
feed=params, # 喂入參數
fetch_list=[x_add_y, x_mul_y]) # 獲取結果
for i in outs:
print(i)
 編輯
編輯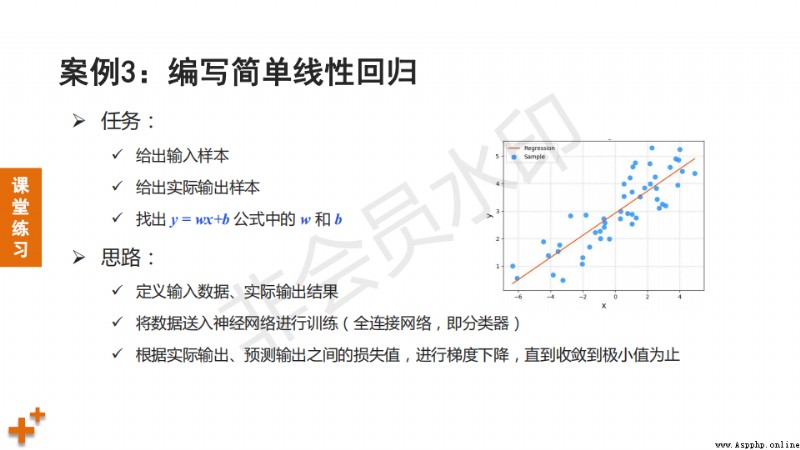
 編輯
編輯
 編輯
編輯
# 簡單線性回歸
import paddle
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
train_data = np.array([[0.5], [0.6], [0.8], [1.1], [1.4]]).astype('float32')
y_true = np.array([[5.0], [5.5], [6.0], [6.8], [6.8]]).astype('float32')
# 定義數據數據類型
x = fluid.layers.data(name="x", shape=[1], dtype="float32")
y = fluid.layers.data(name="y", shape=[1], dtype="float32")
# 通過全連接網絡進行預測
y_preict = fluid.layers.fc(input=x, size=1, act=None)
# 添加損失函數
cost = fluid.layers.square_error_cost(input=y_preict, label=y)
avg_cost = fluid.layers.mean(cost) # 求均方差
# 定義優化方法
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
optimizer.minimize(avg_cost) # 指定最小化均方差值
# 搭建網絡
place = fluid.CPUPlace() # 指定在CPU執行
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program()) # 初始化系統參數
# 開始訓練, 迭代100次
costs = []
iters = []
values = []
params = {"x": train_data, "y": y_true}
for i in range(200):
outs = exe.run(feed=params, fetch_list=[y_preict.name, avg_cost.name])
iters.append(i) # 迭代次數
costs.append(outs[1][0]) # 損失值
print("i:", i, " cost:", outs[1][0])
# 線性模型可視化
tmp = np.random.rand(10, 1) # 生成10行1列的均勻隨機數組
tmp = tmp * 2 # 范圍放大到0~2之間
tmp.sort(axis=0) # 排序
x_test = np.array(tmp).astype("float32")
params = {"x": x_test, "y": x_test} # y參數不參加計算,只需傳一個參數避免報錯
y_out = exe.run(feed=params, fetch_list=[y_preict.name]) # 預測
y_test = y_out[0]
# 損失函數可視化
plt.figure("Trainging")
plt.title("Training Cost", fontsize=24)
plt.xlabel("Iter", fontsize=14)
plt.ylabel("Cost", fontsize=14)
plt.plot(iters, costs, color="red", label="Training Cost") # 繪制損失函數曲線
plt.grid() # 繪制網格線
plt.savefig("train.png") # 保存圖片
# 線性模型可視化
plt.figure("Inference")
plt.title("Linear Regression", fontsize=24)
plt.plot(x_test, y_test, color="red", label="inference") # 繪制模型線條
plt.scatter(train_data, y_true) # 原始樣本散點圖
plt.legend()
plt.grid() # 繪制網格線
plt.savefig("infer.png") # 保存圖片
plt.show() # 顯示圖片
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯
 編輯
編輯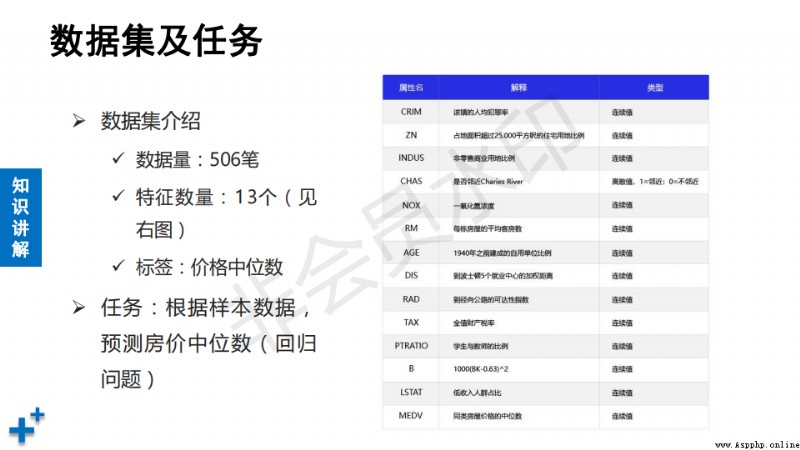
 編輯
編輯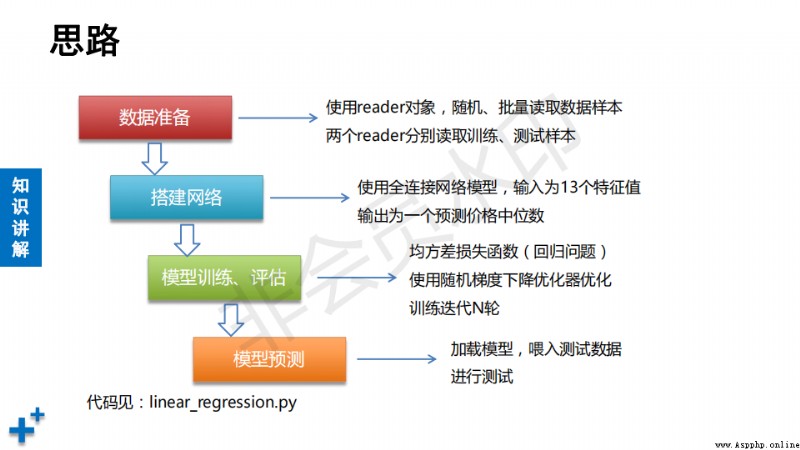
 編輯
編輯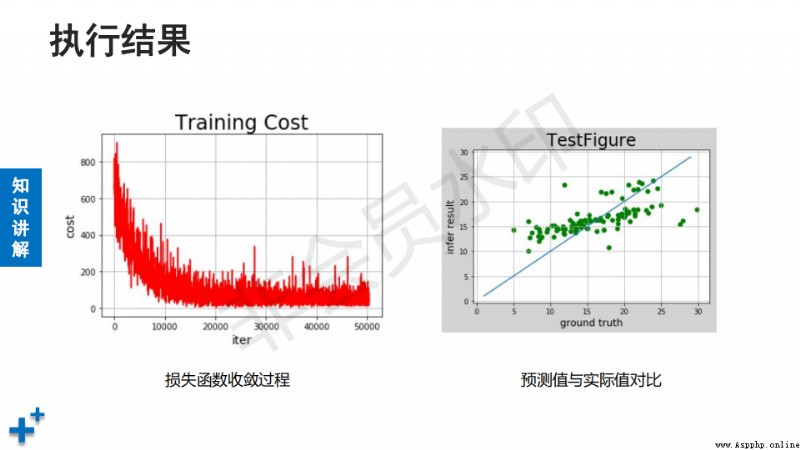
 編輯
編輯
 編輯
編輯
# 多元回歸示例:波士頓房價預測
''' 數據集介紹:
1) 共506行,每行14列,前13列描述房屋特征信息,最後一列為價格中位數
2) 考慮了犯罪率(CRIM) 宅用地占比(ZN)
非商業用地所占尺寸(INDUS) 查爾斯河虛擬變量(CHAS)
環保指數(NOX) 每棟住宅的房間數(RM)
1940年以前建成的自建單位比例(AGE) 距離5個波士頓就業中心的加權距離(DIS)
距離高速公路便利指數(RAD) 每一萬元不動產稅率(TAX)
教師學生比(PTRATIO) 黑人比例(B)
房東屬於中低收入比例(LSTAT)
'''
import paddle
import paddle.fluid as fluid
import numpy as np
import os
import matplotlib.pyplot as plt
# step1: 數據准備
# paddle提供了uci_housing訓練集、測試集,直接讀取並返回數據
BUF_SIZE = 500
BATCH_SIZE = 20
# 訓練數據集讀取器
random_reader = paddle.reader.shuffle(paddle.dataset.uci_housing.train(),
buf_size=BUF_SIZE) # 創建隨機讀取器
train_reader = paddle.batch(random_reader, batch_size=BATCH_SIZE) # 訓練數據讀取器
# 打印數據
#train_data = paddle.dataset.uci_housing.train()
#for sample_data in train_data():
# print(sample_data)
# step2: 配置網絡
# 定義輸入、輸出,類型均為張量
x = fluid.layers.data(name="x", shape=[13], dtype="float32")
y = fluid.layers.data(name="y", shape=[1], dtype="float32")
# 定義個簡單的線性網絡,連接輸出層、輸出層
y_predict = fluid.layers.fc(input=x, # 輸入數據
size=1, # 輸出值個數
act=None) # 激活函數
# 定義損失函數,並將損失函數指定給優化器
cost = fluid.layers.square_error_cost(input=y_predict, # 預測值,張量
label=y) # 期望值,張量
avg_cost = fluid.layers.mean(cost) # 求損失值平均數
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001) # 使用隨機梯度下降優化器
opts = optimizer.minimize(avg_cost) # 優化器最小化損失值
# 創建新的program用於測試計算
test_program = fluid.default_main_program().clone(for_test=True)
# step3: 模型訓練、模型評估
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
iter = 0
iters = []
train_costs = []
EPOCH_NUM = 120
model_save_dir = "../model/uci_housing" # 模型保存路徑
for pass_id in range(EPOCH_NUM):
train_cost = 0
i = 0
for data in train_reader():
i += 1
train_cost = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost])
if i % 20 == 0: # 每20筆打印一次損失函數值
print("PassID: %d, Cost: %0.5f" % (pass_id, train_cost[0][0]))
iter = iter + BATCH_SIZE # 加上每批次筆數
iters.append(iter) # 記錄筆數
train_costs.append(train_cost[0][0]) # 記錄損失值
# 保存模型
if not os.path.exists(model_save_dir): # 如果存儲模型的目錄不存在,則創建
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir, # 保存模型的路徑
["x"], # 預測需要喂入的數據
[y_predict], # 保存預測結果的變量
exe) # 模型
# 訓練過程可視化
plt.figure("Training Cost")
plt.title("Training Cost", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost", fontsize=14)
plt.plot(iters, train_costs, color="red", label="Training Cost")
plt.grid()
plt.savefig("train.png")
# step4: 模型預測
infer_exe = fluid.Executor(place) # 創建用於預測的Executor
infer_scope = fluid.core.Scope() # 修改全局/默認作用域, 運行時中的所有變量都將分配給新的scope
infer_result = [] #預測值列表
ground_truths = [] #真實值列表
# with fluid.scope_guard(infer_scope):
# 加載模型,返回三個值
# program: 預測程序(包含了數據、計算規則)
# feed_target_names: 需要喂入的變量
# fetch_targets: 預測結果保存的變量
[infer_program, feed_target_names, fetch_targets] = \
fluid.io.load_inference_model(model_save_dir, # 模型保存路徑
infer_exe) # 要執行模型的Executor
# 獲取測試數據
infer_reader = paddle.batch(paddle.dataset.uci_housing.test(),
batch_size=200) # 測試數據讀取器
test_data = next(infer_reader()) # 獲取一條數據
test_x = np.array([data[0] for data in test_data]).astype("float32")
test_y = np.array([data[1] for data in test_data]).astype("float32")
x_name = feed_target_names[0] # 模型中保存的輸入參數名稱
results = infer_exe.run(infer_program, # 預測program
feed={x_name: np.array(test_x)}, # 喂入預測的值
fetch_list=fetch_targets) # 預測結果
# 預測值
for idx, val in enumerate(results[0]):
print("%d: %.2f" % (idx, val))
infer_result.append(val)
# 真實值
for idx, val in enumerate(test_y):
print("%d: %.2f" % (idx, val))
ground_truths.append(val)
# 可視化
plt.figure('scatter')
plt.title("TestFigure", fontsize=24)
plt.xlabel("ground truth", fontsize=14)
plt.ylabel("infer result", fontsize=14)
x = np.arange(1, 30)
y = x
plt.plot(x, y)
plt.scatter(ground_truths, infer_result, color="green", label="Test")
plt.grid()
plt.legend()
plt.savefig("predict.png")
plt.show()
 編輯
編輯