在進行單次分析前,我們要選擇好研究的數據對象。如某列,某行,某個數據等…
選擇某一列——>直接選中某一列
選擇某幾列——>選中一列,摁住Ctrl不放,再選其他列
df[列名]
df[[列名1,列名2,···]]
Series對象DataFrame對象如:
df = pd.DataFrame({
"姓名": ["張三", "李四", "王五", "趙六"],
"語文": [110, 92, 98, 121],
"數學": [120, 130, 111, 90],
"英語": [88, 91, 110, 113]
})
names=df["姓名"]
print(type(names))
# <class 'pandas.core.series.Series'>
print(names)
""" 0 張三 1 李四 2 王五 3 趙六 Name: 姓名, dtype: object """
grades=df[["語文","數學","英語"]]
print(type(grades))
# <class 'pandas.core.frame.DataFrame'>
print(grades)
""" 語文 數學 英語 0 110 120 88 1 92 130 91 2 98 111 110 3 121 90 113 """
df.iloc[:,n]
df.iloc[:,[n1,n2,···]]
,前代表哪幾行,,後代表哪幾列:代表所有行如:
names=df.iloc[:,0]
print(names)
""" 0 張三 1 李四 2 王五 3 趙六 Name: 姓名, dtype: object """
grades=df.iloc[:,[1,2,3]]
print(grades)
""" 語文 數學 英語 0 110 120 88 1 92 130 91 2 98 111 110 3 121 90 113 """
拖動選擇即可
同樣有普通索引和位置索引兩種方式。
但位置索引較為簡單。
df.iloc[:,n1:n2]
n1:n2代表選中第n1列到第n2列(從0計數,包含n1,不包含n2)如:
grades=df.iloc[:,1:4]
print(grades)
""" 語文 數學 英語 0 110 120 88 1 92 130 91 2 98 111 110 3 121 90 113 """
同列,Ctrl多選
df.loc[行名]
df.loc[[行名1,行名2,···]]
Series對象DataFrame對象如:
df.set_index("姓名",inplace=True) # 設置"姓名"列為行索引
student1=df.loc["張三"]
print(student1)
""" 語文 110 數學 120 英語 88 Name: 張三, dtype: int64 """
students=df.loc[["李四","王五"]]
print(students)
""" 語文 數學 英語 姓名 李四 92 130 91 王五 98 111 110 """
df.iloc[r] # df.iloc[r,:]
df.iloc[[r1,r2,···]] # df.iloc[[r1,r2,···],:]
如:
student1=df.iloc[0]
print(student1)
""" 語文 110 數學 120 英語 88 Name: 張三, dtype: int64 """
students=df.iloc[[1,2]]
print(students)
""" 語文 數學 英語 姓名 李四 92 130 91 王五 98 111 110 """
同列,拖動即可
同樣有普通索引和位置索引兩種方式。
但位置索引較為簡單(切片索引)。
df.iloc[r1:r2] # df.iloc[r1:r2,:]
r1:r2代表選中第r1行到第r2行(從0計數,包含r1,不包含r2)如:
students=df.iloc[1:4]
print(students)
""" 語文 數學 英語 姓名 李四 92 130 91 王五 98 111 110 趙六 121 90 113 """
“數據”>“排序和篩選”>“篩選”
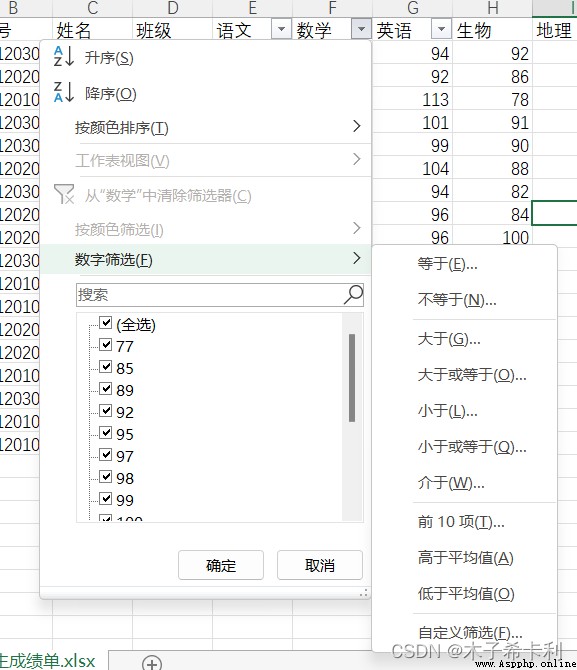
點擊某列的篩選圖標>“數字篩選”,選擇對應條件
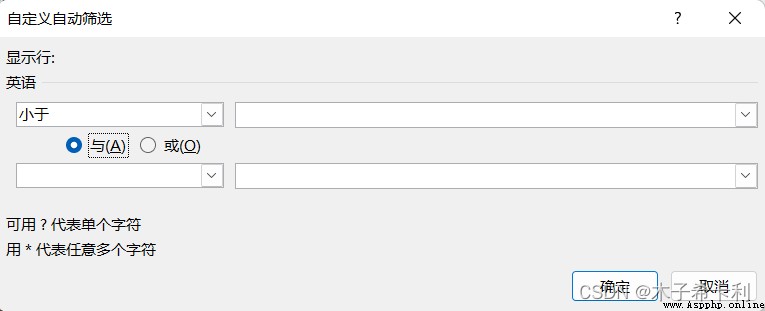
可以進行邏輯運算"與",“或”
df[條件]
df[(條件1) 邏輯運算符 (條件2)]
&(與),|(或),~(非)如:
result1=df[df["語文"]>100] # 語文成績大於100
print(result1)
""" 語文 數學 英語 姓名 張三 110 120 88 趙六 121 90 113 """
result2=df[(df["語文"]>90) & (df["數學"]>90) & df["英語"]>90] #三門成績都大於90
print(result2)
""" 語文 數學 英語 姓名 李四 92 130 91 王五 98 111 110 """
拖動選擇或Ctrl多選
區域選擇,就是選定行和列,取交匯區域。
可以直接行列索引一起進行。也可以先行索引得到一個新的對象,再對新的對象進行列索引。
普通索引,位置索引(包括切片索引),布爾索引(一般用於行)可以自行組合
以下為常見的
df.loc[[行名1,行名2,···],[列名1,列名2,···]]
如:
area1=df.loc[["張三","李四"],["數學","英語"]]
print(area1)
""" 數學 英語 姓名 張三 120 88 李四 130 91 """
df.iloc[[r1,r2,···],[n1,n2,···]] # 第r1,r2,···行和第n1,n2···列交匯區域
df.iloc[r1:r2,n1:n2] #第r1行到r2行(包含r1,不包含r2)和第n1列到n2列(包含n1,不包含n2)交匯區域
如:
area2=df.iloc[[0,2,3],[0,2]]
print(area2)
""" 語文 英語 姓名 張三 110 88 王五 98 110 趙六 121 113 """
area3=df.iloc[1:3,0:3]
print(area3)
""" 語文 數學 英語 姓名 李四 92 130 91 王五 98 111 110 """
df[條件索引][[列名1,列名2,···]]
df[條件索引]返回的DataFrame對象再進行一次列的普通索引如:
area4=df[df["語文"]>100][["數學","英語"]]
print(area4)
""" 數學 英語 姓名 張三 120 88 趙六 90 113 """