文章目錄
- 數據、文獻
- 1. 缺失值處理
- 1.1 缺失值刪除
- 1.1.1 適用情況
- 1.1.2 代碼實現
- 1.1.2.1 情況一代碼
- 1.1.2.2 情況二代碼
- 1.2 缺失值填補
- fillna()
- 1.2.1 使用常數填補缺失值
- 1.2.2 使用上一個或下一個非缺失值填補
- 1.2.3 使用平均值填補缺失值
- 1.2.4 使用眾數填補缺失值
- 1.2.5 使用中位數填補缺失值
- 1.2.6 使用缺失值前一個與後一個非缺失值的均值填補
- 1.2.7 使用拉格朗日插值法對缺失值進行填補
- 1.2.7.1 拉格朗日插值法
- 1.2.7.2 代碼
- 1.2.8 使用預測模型對缺失值進行填補
- 2. 異常值處理
- 2.1 異常值的檢測
- 2.1.1 3σ 准則(拉依達准則)
- 相關概念
- 數據分布圖繪制
- 2.1.2 箱線圖檢測
- 相關概念
- 箱線圖繪制
- 2.2 異常值的處理
- 2.2.1 對不在指定取值范圍內的異常值處理
- 刪除異常值
- 異常值置為空值
- 2.2.2 基於 3σ 准則(拉依達准則)的異常值處理
- 2.2.3 基於箱線圖檢測的異常值處理
- 3. 重復值處理
數據、文獻:
「[Python] 數據預處理(缺失…異常值、重復值)」
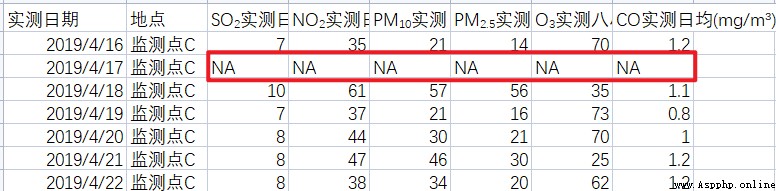
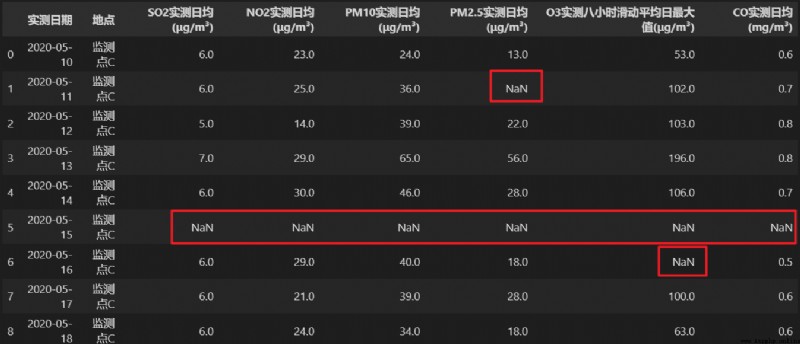
1.對於數據表中的一行,如果整行數據缺失,或者是在一行中所需要使用的數據列對應的數據缺失,那麼可以將這一行直接進行刪除。
如:
2.如果在一行或者一列中存在大量的數據缺失,那麼可以對該行或該列直接進行刪除。
在一行或一列中,數據的缺失量是否達到需要刪除該行或該列,需要視情況而定,這沒有十分准確的標准。
如:
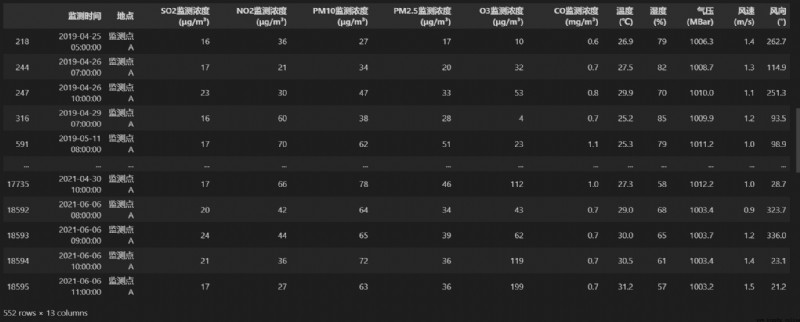
表1:
表2:
通過調用 dropna() 方法,刪除整行數據缺失的行,或者在一行中所需要使用的數據列對應的數據缺失的行。
# 包的導入
import pandas as pd
# 讀取數據
data = pd.read_excel('../../監測點C逐日污染物濃度實測數據.xlsx')
# 刪除數據缺失的行
# 當 subset 指定的列全部缺失才刪除對應的行
data_new = data.dropna(
how='all',
subset=[
'SO2實測日均(μg/m³)',
'NO2實測日均(μg/m³)',
'PM10實測日均(μg/m³)',
'PM2.5實測日均(μg/m³)',
'O3實測八小時滑動平均日最大值(μg/m³)',
'CO實測日均(mg/m³)'
]
)
# print(data_new)
# 導出處理後的數據
data_new.to_excel('./1.xlsx')
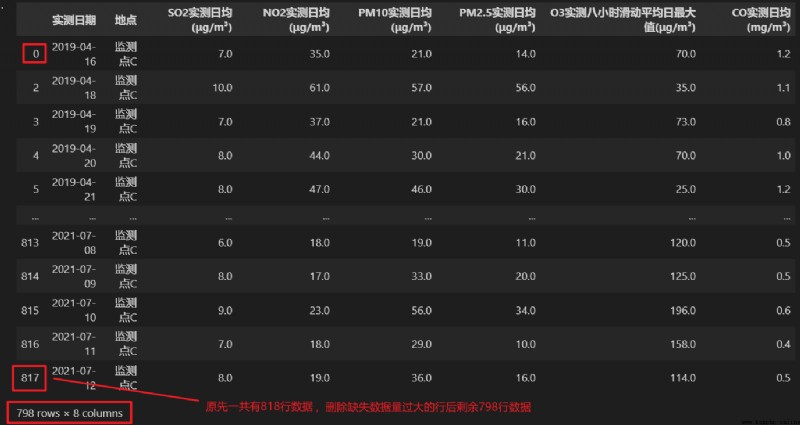
如果在一行中存在大量的數據缺失,直接刪除該行。
數據表表1中一共有8列數據,除去第一第二列,剩下六列數據,當一行中缺失的數據大於等於4個時,將該行刪除。
先調用 apply() 方法對數據表的每行進行處理,然後再對數據表中需要刪除的行進行刪除。
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐日污染物濃度實測數據.xlsx')
# 當一行中的數據,除去第一第二列,
# 缺失的數據個數大於等於4(該表中一共8列數據)
# 返回空行
# 否則將原來的行返回
def fun(row):
sub_row = row[2:]
cnt = sub_row.count()
if cnt<=2 :
# return None
return np.nan
else :
return row
# 調用 apply() 方法對每行數據進行處理
re = data.apply(fun, axis=1)
# 刪除整行數據為空的行,直接修改原表
re.dropna(how='all', inplace=True)
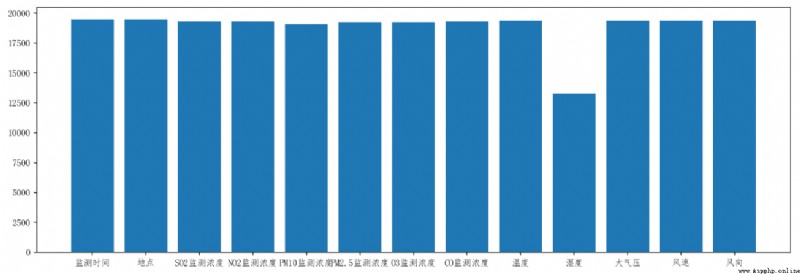
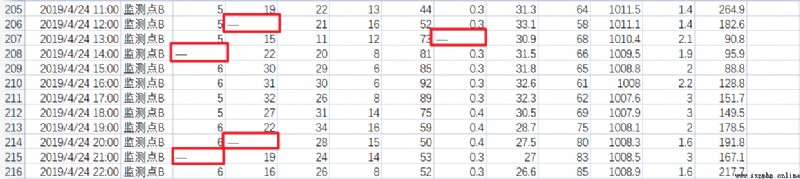
如果在一列中存在大量的數據缺失,直接刪除該列。
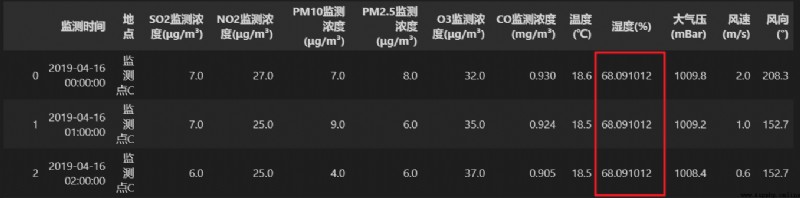
通過對表2中,每列非空數據的統計,發現濕度這一列存在大量的數據缺失,所以將這列數據整列進行刪除。
(1)使用 pop() 方法刪除指定列:
# 包的導入
import pandas as pd
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 刪除指定列
data.pop('濕度(%)')
data
(2)使用 drop() 方法刪除指定列:
# 包的導入
import pandas as pd
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 刪除指定列
re = data.drop('濕度(%)', axis=1)
re
# 包的導入
import pandas as pd
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 刪除指定列
re = data.drop(['濕度(%)'], axis=1)
re
(3)使用 apply() 方法對每列進行處理,然後使用 dropna() 方法刪除數據量缺失過大的列:
假設數據的缺失達到0.3為數據缺失過多,需要將該列進行刪除。
濕度這列非空的數據個數為13310,表2中的總行數為19491,濕度列的數據缺失已達0.3,所有要將濕度這一列進行刪除。
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 獲取所有列中非空數據個數最多的列的數據個數
max_num = data.count().max()
# 處理數據表中的每列
# 數據缺失過多,將整列修改為空
def fun(col):
# print(col.count())
# 計算每列的非空數據個數
num = col.count()
# 假設數據缺失達到0.3為數據缺失過多
# 需要對該列進行刪除
if (num/max_num < 0.7):
# 返回空
return np.nan
else:
return col
# re = data.apply(fun)
re = data.apply(fun, axis=0)
# 刪除整列為空的列
re.dropna(how='all', inplace=True, axis=1)
使用哪種缺失值填補方法對缺失值進行填補,需要根據數據所在的實際場景進行分析與選擇,使得缺失值填補後,對最後的結果造成的影響盡可能的小。
一般缺失值的填補是針對存在少量數據缺失的行或列,或者是刪除整行數據缺失的行和大量數據缺失的行與列後數據集中仍有部分數據缺失的行或列。
如:
以下的舉例均不考慮實際的應用情況和實際場景。
每個例子使用的都為原始的表格,沒有經過預處理。
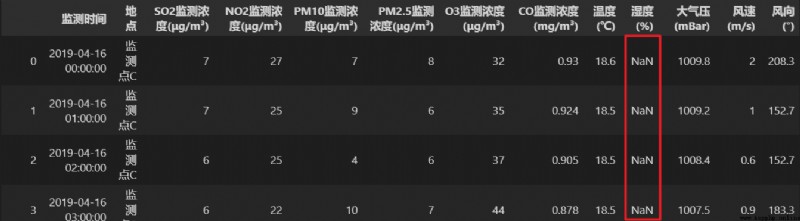
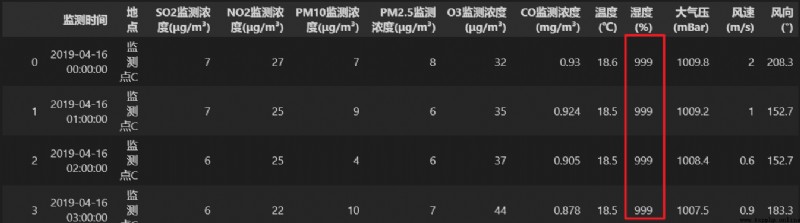
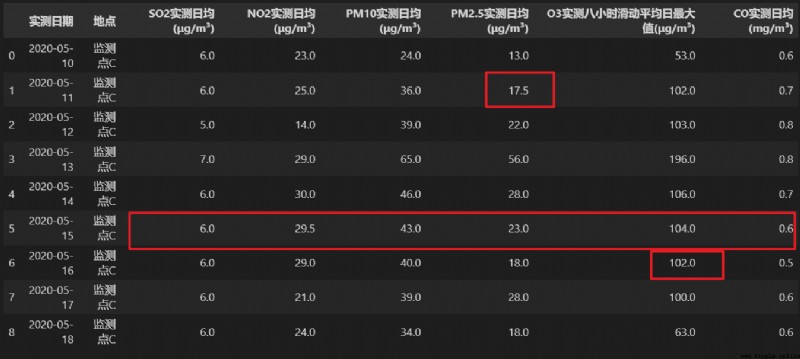
調用 fillna() 方法,使用一個常數對數據表中所有的缺失值進行填補。
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 使用 999 填補數據表中的所有缺失值
re = data.fillna(value=999)
re
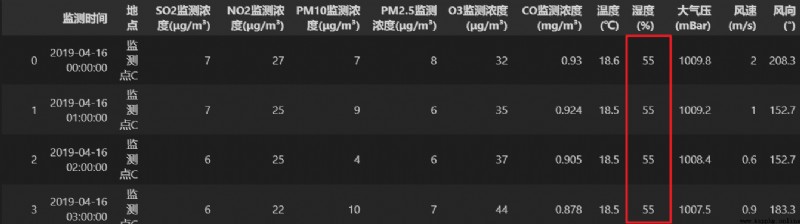
調用 fillna() 方法,使用缺失值的上一個或下一個非缺失值對數據表中所有的缺失值進行填補。
由於濕度這一列第一行的數據為空,所以使用缺失值的下一行非缺失值對缺失的數據進行填補。
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 使用缺失值的下一行非缺失值填補數據表中的所有缺失值
re = data.fillna(method='bfill', axis=0)
re
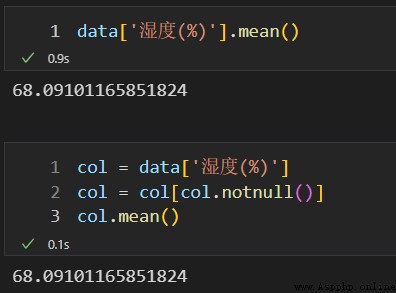
調用 fillna() 方法,使用每列的平均值對數據表中對應列的缺失值進行填補。
經過驗證,調用 mean() 方法計算列的均值,空值(缺失值)不會計算在內。
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 由於表格中的部分缺失值使用字符串類型的'—' 'NULL' 'NA' 表示
# 所有先對這些數據進行處理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法會遍歷並處理表格中每個單元格的數據
# fun 為傳入的函數參數,用於處理每個單元格
# fun 函數會接收一個參數,為表格中每個單元格的數據
data = data.applymap(fun)
# 使用每列的均值對每列中的缺失值進行填補
# def fun_mean(col):
# 如果當前列是第二列直接退出函數
# 第二列的數據為字符串類型
# if (col.name == '地點'): return col
# col.fillna(value=col.mean(), inplace=True)
# return col
# re = data.apply(fun_mean)
# 循環處理第三列及往後的每列
# 使用每列的均值對每列中的缺失值進行填補
for col_name in data.columns[2:]:
# 當前要處理的列
col = data[col_name]
# 使用當前列的均值填補缺失值
col.fillna(value=col.mean(), inplace=True)
# 更新原數據表
data[col_name] = col
data
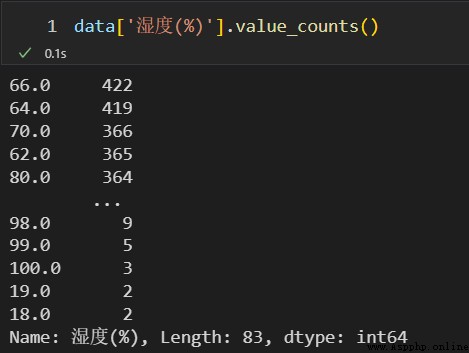
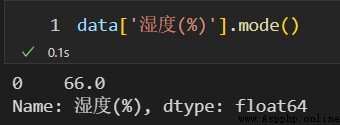
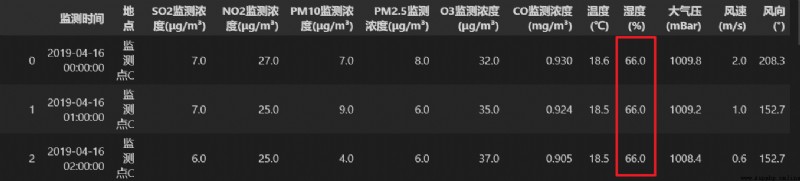
調用 fillna() 方法,使用每列的眾數對數據表中對應列的缺失值進行填補。
濕度這一列的取值情況如下:
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 由於表格中的部分缺失值使用字符串類型的'—' 'NULL' 'NA' 表示
# 所有先對這些數據進行處理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法會遍歷並處理表格中每個單元格的數據
# fun 為傳入的函數參數,用於處理每個單元格
# fun 函數會接收一個參數,為表格中每個單元格的數據
data = data.applymap(fun)
# 使用每列的眾數對每列中的缺失值進行填補
def fun_(col):
# 獲取第一個眾數填補缺失值
col.fillna(value=col.mode()[0], inplace=True)
return col
re = data.apply(fun_)
re
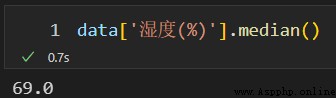
調用 fillna() 方法,使用每列的中位數對數據表中對應列的缺失值進行填補。
濕度這一列的中位數如下:
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../監測點C逐小時污染物濃度與氣象實測數據.xlsx')
# 由於表格中的部分缺失值使用字符串類型的'—' 'NULL' 'NA' 表示
# 所有先對這些數據進行處理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法會遍歷並處理表格中每個單元格的數據
# fun 為傳入的函數參數,用於處理每個單元格
# fun 函數會接收一個參數,為表格中每個單元格的數據
data = data.applymap(fun)
# 使用每列的中位數對每列中的缺失值進行填補
def fun_(col):
# 如果當前列是第二列直接退出函數
# 第二列的數據為字符串類型
if (col.name == '地點'): return col
col.fillna(value=col.median(), inplace=True)
return col
re = data.apply(fun_)
re
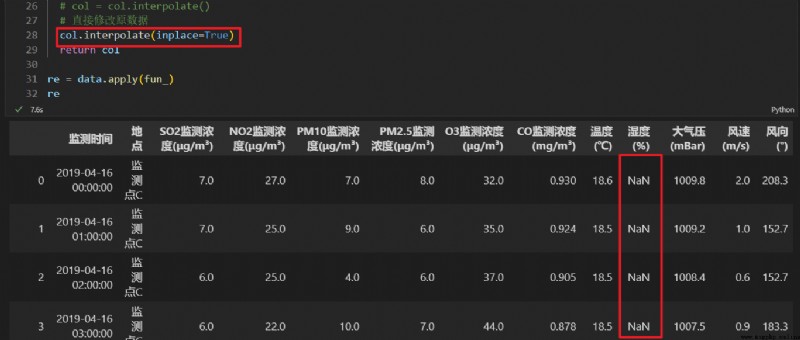
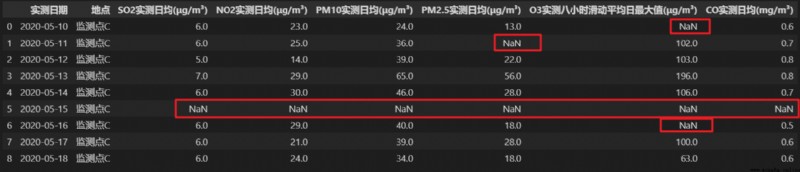
調用 interpolate() 方法,使用每列的缺失值前一個與後一個非缺失值的均值對數據表中對應列的缺失值進行填補。
如果第一行就存在缺失值,則本方法不適用,缺失值不會被填補,仍然為 NaN。
當前的測試數據如下:
# 包的導入
import pandas as pd
import numpy as np
# 讀取數據
data = pd.read_excel('../../1.xlsx')
# 由於表格中的部分缺失值使用字符串類型的'—' 'NULL' 'NA' 表示
# 所有先對這些數據進行處理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法會遍歷並處理表格中每個單元格的數據
# fun 為傳入的函數參數,用於處理每個單元格
# fun 函數會接收一個參數,為表格中每個單元格的數據
data = data.applymap(fun)
# 使用每列的缺失值前一個與後一個非缺失值的均值
# 對每列中的缺失值進行填補
def fun_(col):
# 第一列為時間類型直接退出函數
if (col.name == '實測日期'): return col
# 如果當前列是第二列直接退出函數
# 第二列的數據為字符串類型
if (col.name == '地點'): return col
# col = col.interpolate()
# 直接修改原數據
col.interpolate(inplace=True)
return col
re = data.apply(fun_)
re
以下內容來自:
[1]趙莉,孫娜,李麗萍,崔傑.拉格朗日插值法在數據清洗中的應用[J].遼寧工業大學學報(自然科學版),2022,42(02):102-105+117.DOI:10.15916/j.issn1674-3261.2022.02.007.
文獻知網連接
拉格朗日多項式插值法的基本思想是:給出一個恰好穿過二維平面上幾個已知點的多項式,利用最小次數的多項式來構建一條光滑曲線,使曲線通
過所有已知點。
對於平面中的n個已知點(一條直線上無兩點),可以找到一個n-1次多項式:
y = a 0 + a 1 x 2 + a 2 x + ⋯ + a n − 1 x n − 1 y=a_{0}+a_{1} x^{2}+a_{2} x+\cdots+a_{n-1} x^{n-1} y=a0+a1x2+a2x+⋯+an−1xn−1
使得此多項式對應的曲線通過這n個點。將n個點的坐標 ( x 1 x_1 x1, y 1 y_1 y1), ( x 2 x_2 x2, y 2 y_2 y2), …, ( x n x_n xn, y n y_n yn)代入多項式中得到:
y 1 = a 0 + a 1 x 1 + a 2 x 1 2 + a n − 1 x 1 n − 1 y 2 = a 0 + a 1 x 2 + a 2 x 2 2 + a n − 1 x 2 n − 1 … y n = a 0 + a 1 x n + a 2 x n 2 + a n − 1 x n n − 1 \begin{array}{c} y_{1}=a_{0}+a_{1} x_{1}+a_{2} x_{1}^{2}+a_{n-1} x_{1}^{n-1} \\ y_{2}=a_{0}+a_{1} x_{2}+a_{2} x_{2}^{2}+a_{n-1} x_{2}^{n-1} \\ \ldots \\ y_{n}=a_{0}+a_{1} x_{n}+a_{2} x_{n}^{2}+a_{n-1} x_{n}^{n-1} \end{array} y1=a0+a1x1+a2x12+an−1x1n−1y2=a0+a1x2+a2x22+an−1x2n−1…yn=a0+a1xn+a2xn2+an−1xnn−1
解得拉格朗日插值多項式如下:
L ( x ) = ∑ i = 0 n y i ∏ j = 0 , j ≠ i n x − x j x i − x j L(x)=\sum_{i=0}^{n} y_{i} \prod_{j=0, j \neq i}^{n} \frac{x-x_{j}}{x_{i}-x_{j}} L(x)=i=0∑nyij=0,j=i∏nxi−xjx−xj
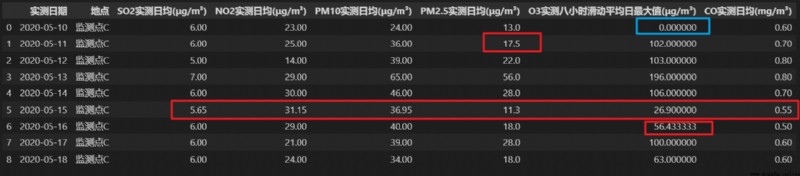
例如,平面上有 4 個點,(4, 10)、(5, 5.25)、(6, 1)、(18, ?),根據拉格朗日插值法計算缺失“?”的值:
L ( x ) = 10 ( x − 5 ) ( x − 6 ) ( 4 − 5 ) ( 4 − 6 ) + 5.25 ( x − 4 ) ( x − 6 ) ( 5 − 4 ) ( 5 − 6 ) + ( x − 4 ) ( x − 5 ) ( 6 − 4 ) ( 6 − 5 ) = 1 4 ( x 2 − 28 x + 136 ) \begin{aligned} L(x)=& 10 \frac{(x-5)(x-6)}{(4-5)(4-6)}+5.25 \frac{(x-4)(x-6)}{(5-4)(5-6)}+\\ & \frac{(x-4)(x-5)}{(6-4)(6-5)}=\frac{1}{4}\left(x^{2}-28 x+136\right) \end{aligned} L(x)=10(4−5)(4−6)(x−5)(x−6)+5.25(5−4)(5−6)(x−4)(x−6)+(6−4)(6−5)(x−4)(x−5)=41(x2−28x+136)
將 x=18 代入可以得到 L(18)=-11,因此缺失的值是-11。
當前將要進行缺失值填補的數據:
為了防止取缺失值前後的非缺失值時索引越界,對文獻中的代碼進行了修改
import numpy as np
import pandas as pd
# 引入拉格朗日插值法所需的方法
from scipy.interpolate import lagrange
# 文件讀取
data = pd.read_excel('../../1.xlsx')
# 字符串表示的空值預處理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
data = data.applymap(fun)
# 生成拉格朗日插值
def interpolate_columns(data_col, missing_val_idx, k=5):
""" data_col: 需要進行缺失值填補的列 missing_val_idx: 數據缺失的單元格在該列對應的索引 k: 缺失值前後取值的個數, 默認為5個 return: 返回拉格朗日插值 """
# 防止取缺失值前後的非缺失值時下標越界
# 向缺失值前取值的個數,默認為 k
f_k = k
# 如果缺失值前還有的數值個數小於 k
# 更改取值個數
if(missing_val_idx < k): f_k = missing_val_idx
# 向缺失值後取值的個數,默認為 k
b_k = k
# 如果缺失值後還有的數值個數小於 k
# 更改取值個數
if((data_col.size-missing_val_idx-1) < k): b_k = data_col.size-missing_val_idx-1
# 獲取二者的較小值
if(f_k <= b_k): k = f_k
else: k = b_k
# 取出當前缺失值位置前後 k 個值
y = data_col[
list(range(missing_val_idx-k, missing_val_idx)) + list(range(missing_val_idx+1, missing_val_idx+1+k))
]
# 去除空值
y = y[ y.notnull() ]
# 生成拉格朗日插值函數
f = lagrange(y.index, list(y))
# 計算並返回缺失值將要填補的數據值
return f(missing_val_idx)
# 遍歷數據表
# 每列
for i in data.columns[2:]:
# 遍歷每列中的每個單元格
for j in range(data[i].size):
# 如果單元格為空
# 進行拉格朗日插值
if data[i].isnull()[j]:
data[i][j] = interpolate_columns(data[i], j)
data
此代碼無法對數據表第一行與最後一行存在的缺失值進行填補,由於代碼修改,當缺失值在第一行或最後一行時,取缺失值前後的非缺失值的個數為0,所以無法使用拉格朗日插值法進行數據的填補。
文獻中的代碼:
預測模型較多,後面補上
3σ(西格瑪)准則(拉依達准則) 是指先假設一組檢測數據只含有隨機誤差,對其進行計算處理得到標准偏差,按一定概率確定一個區間,認為凡超過這個區間的誤差,就不屬於隨機誤差而是粗大誤差,含有該誤差的數據應予以剔除。
這種判別處理原理及方法 僅局限於對正態或近似正態分布 的樣本數據處理,它是 以測量次數充分大為前提 的,當測量次數少的情形用准則剔除粗大誤差是不夠可靠的。因此,在測量次數較少的情況下,最好不要選用該准則。
來源於百度百科 鏈接
在正態分布中:
x = μ x=\mu x=μ 為正態分布圖像的對稱軸。
數值分布在橫軸區間 ( μ − σ , μ + σ ) (μ-σ,μ+σ) (μ−σ,μ+σ)內的概率為68.268949%。
數值分布在橫軸區間 ( μ − 2 σ , μ + 2 σ ) (μ-2σ,μ+2σ) (μ−2σ,μ+2σ)內的概率為95.449974%。
數值分布在橫軸區間 ( μ − 3 σ , μ + 3 σ ) (μ-3σ,μ+3σ) (μ−3σ,μ+3σ)內的概率為99.730020%。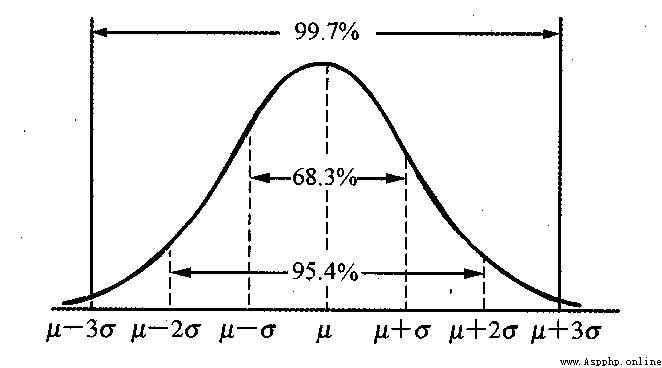
“小概率事件”和假設檢驗的基本思想:“小概率事件” 通常指發生的概率小於5% 的事件,認為在一次試驗中該事件是 幾乎不可能發生 的。由此可見 X落在(μ-3σ,μ+3σ)以外 的概率小於千分之三,在實際問題中常認為相應的事件 不會發生 ,基本上可以把區間(μ-3σ,μ+3σ)看作是隨機變量X實際可能的取值區間,這稱之為正態分布的“3σ”原則。
來源於百度百科 鏈接
設對被測量進行等精度測量,獨立得到 x 1 x_{1} x1, x 2 x_{2} x2,…, x n x_{n} xn,算出其算術平均值 x 及剩余誤差 v i = x i − x v_{i} = x_{i} - x vi=xi−x (i=1,2,…,n),並按貝塞爾公式算出標准偏差 σ ,若某個測量值 x b x_{b} xb 的剩余誤差 v b v_{b} vb (1<=b<=n),滿足下式
∣ v b ∣ = ∣ x b − x ∣ > 3 σ |v_{b}|=|x_{b}-x|>3σ ∣vb∣=∣xb−x∣>3σ
則認為 x b x_{b} xb 是含有粗大誤差值的壞值,應予剔除。
在整理試驗數據時,往往會遇到這樣的情況,即在一組試驗數據裡,發現少數幾個偏差特別大的可疑數據,這類數據稱為 Outlier 或 Exceptional Data ,他們往往是由於過失誤差引起。
來源於百度百科 鏈接
參考:
【Python可視化 | Seaborn之seaborn.distplot()】鹿港小小鎮
【sns.distplot()用法】小小喽啰
數據文件名:
監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_補全數據_去除負數.xlsx
這裡只進行簡單的測試,更加詳細的測試【待寫】
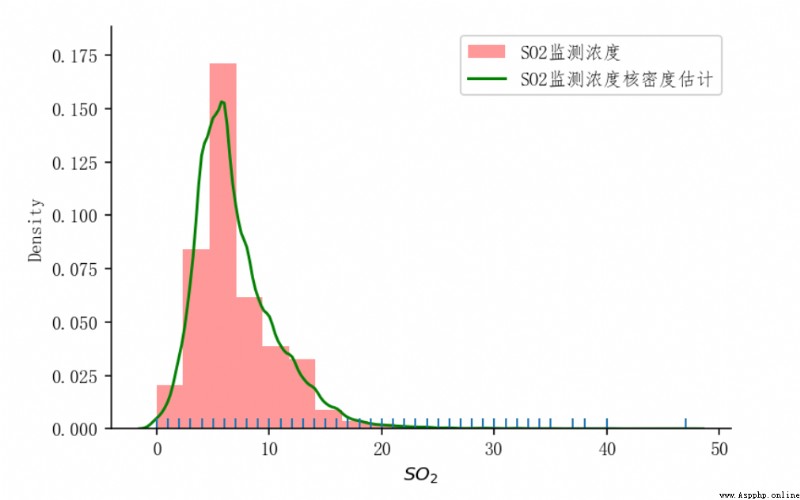
繪制 SO2監測濃度 的數據分布圖
import pandas as pd
# 畫圖所需的包
import matplotlib.pyplot as plt
# 繪制數據分布圖所需的包
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作圖的分辨率
%config InlineBackend.figure_format = 'retina'
# 處理中文與負號的顯示問題
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題
# 讀取數據
data = pd.read_excel('./監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_補全數據_去除負數.xlsx')
# 修改列名
data.columns = ['監測時間', '地點', 'SO2監測濃度', 'NO2監測濃度', 'PM10監測濃度',
'PM2.5監測濃度', 'O3監測濃度', 'CO監測濃度', '溫度', '濕度',
'氣壓', '風速', '風向']
# 繪制數據分布圖
# ax 接收返回的坐標軸對象
ax = sns.distplot(
# 繪制圖形的數據
data['SO2監測濃度'],
# 直方圖柱 20個
bins=20,
# 顯示變量的分布情況
rug=True,
# 直方圖樣式設置
hist_kws={
'label': 'SO2監測濃度',
'color': 'red'
},
# 核密度估計曲線樣式設置
kde_kws={
'label': 'SO2監測濃度核密度估計',
'color': 'green'
},
# 設置x軸的標簽
axlabel= r'$SO_{2}$'
)
# 取消上軸和右軸的顯示
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 顯示圖例
plt.legend()
plt.show()
以下內容來自:
[1]孫向東,劉擁軍,陳雯雯,賈智寧,黃保續.箱線圖法在動物衛生數據異常值檢驗中的運用[J].中國動物檢疫,2010,27(07):66-68.
知網文獻鏈接
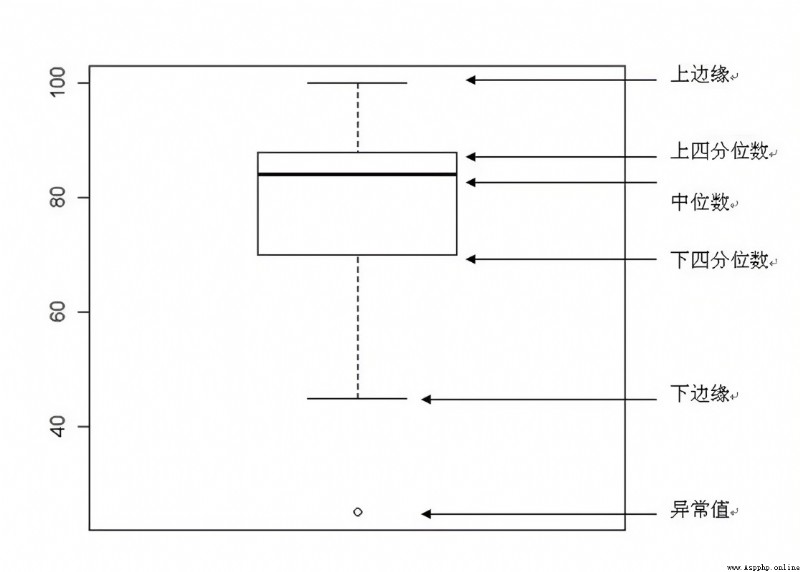
箱線圖(Boxplot)也稱箱須圖(Box-whisker Plot),是美國著名統計學家 John W. Tukey 於 1977 年發明的。箱線圖法利用數據中的五個統計量:最小值、下四分位數(Q1)、中位數(Q2)、上四分位數(Q3)與最大值 來描述數據。
以下內容(本文)僅討論其在異常值鑒別中的應用。
箱線圖根據實際數據繪制,既 不需要事先假定數據服從特定的概率分布 ,也 沒有對數據作任何限制性要求 ,能夠真實、直觀地表現數據形狀的本來面貌。
箱線圖判斷異常值的標准以四分位數和四分位距為基礎,較多數據的變化對四分位數影響不大,所以箱線圖判斷異常值的標准具有較強的魯棒性(Robust),檢測結果比較客觀。
箱線圖法采用中位數代替平均數檢測異常值是統計檢測方法上的一大改進。箱線圖法能夠有效克服數據中存在異常值時,不能測出異常值的這種掩蓋效應(masking effect)。
箱線圖的結構:
箱線圖由參照系(坐標軸)、標志物(箱體、上下四分位線、中位線、異常值截斷點)、檢測數據(箱體兩端的延伸線、異常值)三種成分構成,具體
見圖1。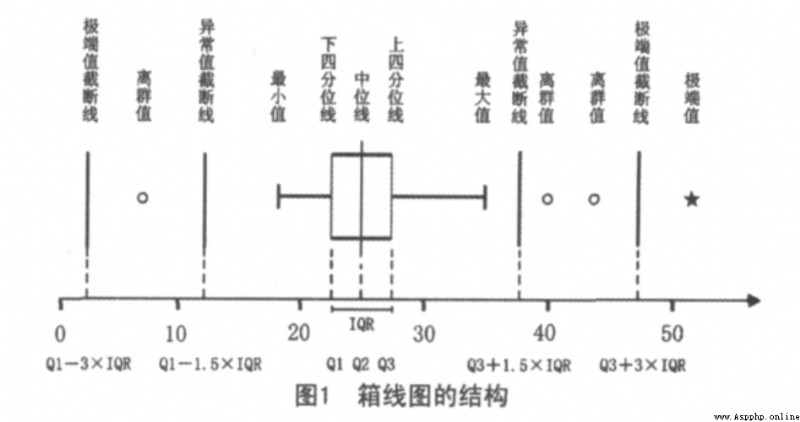
其中 箱體的兩端分別對應下四分位數 Q1 和上四分位數 Q3 , Q1和 Q3之間稱作四分位距 (Inter Quartile Range,IQR)。 上四分位點右邊 1.5倍 IQR 和下四分位點左邊 1.5 倍 IQR位置對應的點是異常值截斷點 ,異常值截斷點之間是內限。上四分位點右邊 3 倍 IQR 和下四分位點左邊 3 倍IQR 位置對應的點是極端值截斷點,極端值截斷點之間是外限。
異常值截斷點以外的數據稱作異常值 ,其中在內限與外限之間的異常值為溫和異常值或離群值(Outlier,mild outliers),在外限以外的為極端異常值或極端值(Extreme,extreme outliers)。
箱線圖的結構與標准正態分布函數 N(0, 1) 之間的比較見圖2。
其中 Q3 與 Q1 之間包含了 50%的數據點,異常值截斷點之間包含了 99.3%的數據點,非異常值誤判為異常值的概率不大於 0.7%。
箱線圖的結構圖
以下博客對於繪制箱線圖的方法參數介紹的很詳細,這裡不在進行介紹。
matplotlib.pyplot.boxplot()
將方法的參數及其說明復制在這:
x:指定要繪制箱線圖的數據,可以是一組數據也可以是多組數據;
notch:是否以凹口的形式展現箱線圖,默認非凹口;
sym:指定異常點的形狀,默認為藍色的+號顯示;
vert:是否需要將箱線圖垂直擺放,默認垂直擺放;
whis:指定上下須與上下四分位的距離,默認為1.5倍的四分位差;
positions:指定箱線圖的位置,默認為range(1, N+1),N為箱線圖的數量;
widths:指定箱線圖的寬度,默認為0.5;
patch_artist:是否填充箱體的顏色,默認為False;
meanline:是否用線的形式表示均值,默認用點來表示;
showmeans:是否顯示均值,默認不顯示;
showcaps:是否顯示箱線圖頂端和末端的兩條線,默認顯示;
showbox:是否顯示箱線圖的箱體,默認顯示;
showfliers:是否顯示異常值,默認顯示;
boxprops:設置箱體的屬性,如邊框色,填充色等;
labels:為箱線圖添加標簽,類似於圖例的作用;即箱線圖對應x軸點的名字
flierprops:設置異常值的屬性,如異常點的形狀、大小、填充色等;
medianprops:設置中位數的屬性,如線的類型、粗細等;
meanprops:設置均值的屬性,如點的大小、顏色等;
capprops:設置箱線圖頂端和末端線條的屬性,如顏色、粗細等;
whiskerprops:設置須的屬性,如顏色、粗細、線的類型等;
manage_ticks:是否自適應標簽位置,默認為True;
autorange:是否自動調整范圍,默認為False;
seaborn.boxplot()
將方法的參數及其說明復制在這:
x, y, hue:數據或向量數據中的變量名稱
用於繪制長格式數據的輸入。
data:DataFrame,數組,數組列表
用於繪圖的數據集。
如果x和y都缺失,那麼數據將被視為寬格式。
否則數據被視為長格式。
order, hue_order:字符串列表
控制分類變量(對應的條形圖)的繪制順序,
若缺失則從數據中推斷分類變量的順序。
orient:“v”或“h”
控制繪圖的方向(垂直或水平)。
這通常是從輸入變量的 dtype 推斷出來的,
但是當“分類”變量為數值型或繪制寬格式數據時
可用於指定繪圖的方向。
color:matplotlib顏色
所有元素的顏色,或漸變調色板的種子顏色。
palette:調色板名稱,列表或字典
用於hue變量的不同級別的顏色。
可以從color_palette()得到一些解釋,
或者將色調級別映射到matplotlib顏色的字典。
saturation:float
控制用於繪制顏色的原始飽和度的比例。
通常大幅填充在輕微不飽和的顏色下看起來更好,
如果您希望繪圖顏色與輸入顏色規格完美匹配
可將其設置為1。
width:float
不使用色調嵌套時完整元素的寬度,
或主要分組變量一個級別的所有元素的寬度。
dodge:bool
使用色調嵌套時,元素是否應沿分類軸移動。
fliersize:float
用於表示異常值觀察的標記的大小。
linewidth:float
構圖元素的灰線寬度。
whis:float
控制在超過高低四分位數時 IQR (四分位間距)的比例,
因此需要延長繪制的觸須線段。超出此范圍的點將被識別為異常值。
notch:boolean
是否使矩形框“凹陷”以指示中位數的置信區間。
還可以通過plt.boxplot的一些參數來控制
ax:matplotlib軸
繪圖時使用的 Axes 軸對象,否則使用當前 Axes 軸對象
kwargs:鍵值映射
其他在繪圖時傳給plt.boxplot的參數
設置方法與 plt.boxplot 一樣
數據文件名:
監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_補全數據_去除負數.xlsx
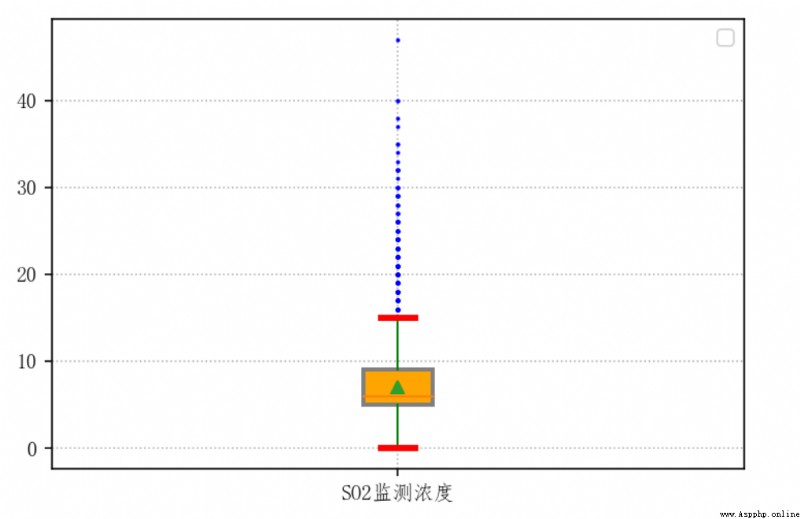
繪制 SO2監測濃度 的箱線圖
測試一些經常會使用的參數和參數的常用設置
matplotlib.pyplot.boxplot()
import pandas as pd
# 畫圖所需的包
import matplotlib.pyplot as plt
# 提高 matplotlib 在 jupyter 中作圖的分辨率
%config InlineBackend.figure_format = 'retina'
# 處理中文與負號的顯示問題
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題
# 讀取數據
data = pd.read_excel('./監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_補全數據_去除負數.xlsx')
# 修改列名
data.columns = ['監測時間', '地點', 'SO2監測濃度', 'NO2監測濃度', 'PM10監測濃度',
'PM2.5監測濃度', 'O3監測濃度', 'CO監測濃度', '溫度', '濕度',
'氣壓', '風速', '風向']
# 繪制箱線圖
plt.boxplot(
# 繪圖數據
data['SO2監測濃度'],
# 箱子是否內凹
# notch=True,
# 設置異常點的形狀
# sym='.',
# 填充箱體顏色
patch_artist=True,
# 顯示平均值,默認使用點顯示
showmeans=True,
# 設置箱子的寬度
widths=0.1,
# 設置箱子的樣式,需要 patch_artist=True
boxprops={
# 箱子的邊框為灰色
'color': 'gray',
# 箱子的填充色為橙色
'facecolor': 'orange',
# 設置邊框線的寬度
'linewidth': '2'
},
# 設置異常值點的樣式
flierprops={
# 設置點的形狀
'marker': '.',
# 設置點的填充色
'markerfacecolor': 'blue',
# 設置點的邊框色
'markeredgecolor': 'blue',
# 設置點的大小
'markersize': '2'
},
# 添加箱線圖在x軸對應位置的名字
# x軸坐標點名
labels=['SO2監測濃度'],
# 設置須的樣式
whiskerprops={
# 設置線的顏色
'color': 'green'
},
# 設置箱線圖最值線的樣式
capprops={
# 設置線的顏色
'color': 'red',
# 設置線的寬度
'linewidth': '3'
}
)
plt.grid(linestyle=':')
# 顯示圖例
plt.legend()
plt.show()
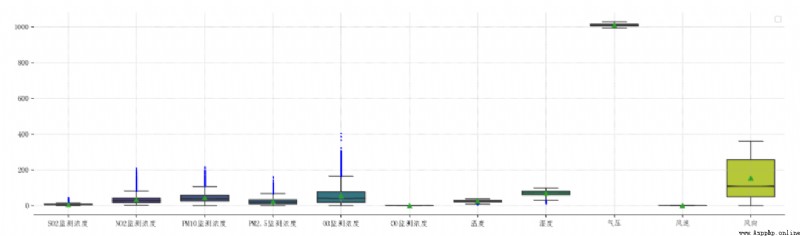
繪制 所有列 的箱線圖
測試一些經常會使用的參數和參數的常用設置
seaborn.boxplot()
import pandas as pd
# 畫圖所需的包
import matplotlib.pyplot as plt
# 繪制數據分布圖所需的包
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作圖的分辨率
%config InlineBackend.figure_format = 'retina'
# 處理中文與負號的顯示問題
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題
# 讀取數據
data = pd.read_excel('./監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_補全數據_去除負數.xlsx')
# 修改列名
data.columns = ['監測時間', '地點', 'SO2監測濃度', 'NO2監測濃度', 'PM10監測濃度',
'PM2.5監測濃度', 'O3監測濃度', 'CO監測濃度', '溫度', '濕度',
'氣壓', '風速', '風向']
# 設置畫布大小
plt.figure(figsize=(18, 5))
# 繪制箱線圖
# 會返回一個坐標軸對象
ax = sns.boxplot(
# x = data['NO2監測濃度'],
# 繪圖的數據
# y = data['SO2監測濃度'],
# 傳入 DataFrame 類型的數據,會繪制每列的箱線圖
data=data,
# 箱子的填充色
# 有多個箱子,多個箱子的顏色都會一致
# color='red',
# 設置調色板,會根據調色板的顏色映射規則對箱子填充顏色
palette='viridis',
# 設置箱子的寬度
width=0.7,
# 異常值點的大小
fliersize=2,
# 箱線圖中邊框、線的寬度
linewidth=1.2,
# 箱子內凹
notch=True,
# 其他樣式設置, 與 matplotlib.pyplot.boxplot() 一樣
# 顯示均值
showmeans=True,
# 設置異常值點的樣式
flierprops={
# 設置點的形狀
'marker': '.',
# 設置點的填充色
'markerfacecolor': 'blue',
# 設置點的邊框色
'markeredgecolor': 'blue',
# 設置點的大小
'markersize': '2'
}
)
# 取消上軸和右軸的顯示
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_color('none')
plt.grid(linestyle=':')
# 顯示圖例
plt.legend()
plt.show()
數據文件名:
監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_數據填補.xlsx
data['SO2監測濃度(μg/m³)'].value_counts()
統計 SO2監測濃度(μg/m³) 的取值情況:
存在16個數據取值為負數,由於濃度大於等於0,所以對取值為負數的異常值進行處理。
未處理前的數據情況:
由於 SO2監測濃度(μg/m³) 取值為負數的數據個數並不多,所以將 SO2監測濃度(μg/m³) 取值為負數的行直接刪除。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 讀取數據
data = pd.read_excel('../22/監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_數據填補.xlsx')
# 刪除 SO2監測濃度(μg/m³) 取值為負數的行
# 即取出 SO2監測濃度(μg/m³) 取值大於等於0的行
re = data[data['SO2監測濃度(μg/m³)']>=0]
re.count()
未處理前的數據情況:
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 讀取數據
data = pd.read_excel('../22/監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_數據填補.xlsx')
# 深復制一份數據
data1 = data.copy()
# 將 SO2監測濃度(μg/m³) 列中取值為負數的數據置為空值
data1['SO2監測濃度(μg/m³)'][data1['SO2監測濃度(μg/m³)']<0] = pd.NA
data1.count()
這裡只進行異常值的篩選,不進行處理,若要處理可以采用與 2.2.1 中類似的方法進行處理,刪除異常值或者置為空值後填補異常值。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作圖的分辨率
%config InlineBackend.figure_format = 'retina'
# 處理中文與負號的顯示問題
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題
# 讀取數據
data = pd.read_excel('../22/監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_數據填補.xlsx')
# 獲取 SO2監測濃度(μg/m³) 列
so2 = data['SO2監測濃度(μg/m³)']
# 計算均值與標准差
mean_so2 = so2.mean()
std_so2 = so2.std()
print(mean_so2, std_so2)
# 計算 μ-3σ μ+3σ
left = mean_so2 - 3*std_so2
right = mean_so2 + 3*std_so2
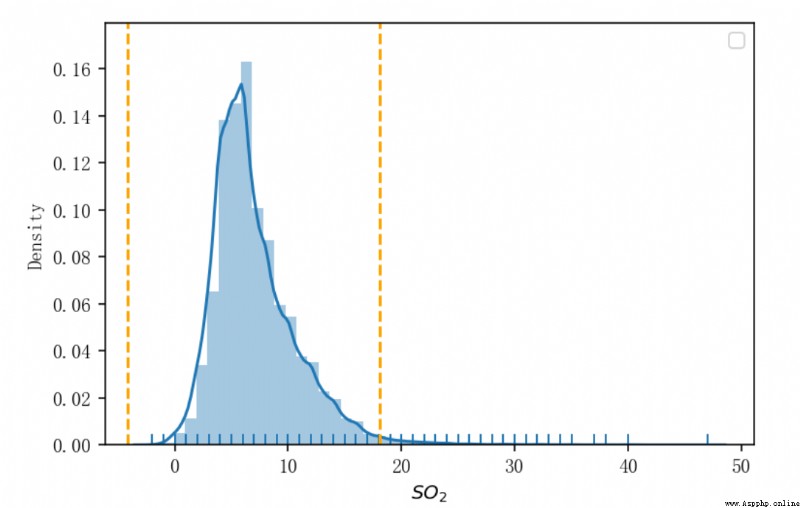
# 繪制數據分布圖
# ax 接收返回的坐標軸對象
ax = sns.distplot(
# 繪制圖形的數據
data['SO2監測濃度(μg/m³)'],
# 顯示變量的分布情況
rug=True,
# 設置x軸的標簽
axlabel= r'$SO_{2}$'
)
# 繪制 μ-3σ μ+3σ
plt.axvline(left, linestyle='--', color='orange')
plt.axvline(right, linestyle='--', color='orange')
# 顯示圖例
plt.legend()
plt.show()
# 復制數據集
data1 = data.copy()
# 篩選出 SO2監測濃度(μg/m³) 列取值不在 (μ-3σ, μ+3σ) 內的行
data1 = data1[np.abs(data1['SO2監測濃度(μg/m³)']-mean_so2) > 3*std_so2]
data1
均值與標准差
基於 3σ 准則(拉依達准則) 篩選出的 SO2監測濃度(μg/m³) 取值異常的行:
這裡只進行異常值的篩選,不進行處理,若要處理可以采用與 2.2.1 中類似的方法進行處理,刪除異常值或者置為空值後填補異常值。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作圖的分辨率
%config InlineBackend.figure_format = 'retina'
# 處理中文與負號的顯示問題
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存圖像是負號'-'顯示為方塊的問題
# 讀取數據
data = pd.read_excel('../22/監測點A逐小時污染物濃度與氣象實測數據_去除整行缺失_數據填補.xlsx')
# 獲取 SO2監測濃度(μg/m³) 列
so2 = data['SO2監測濃度(μg/m³)']
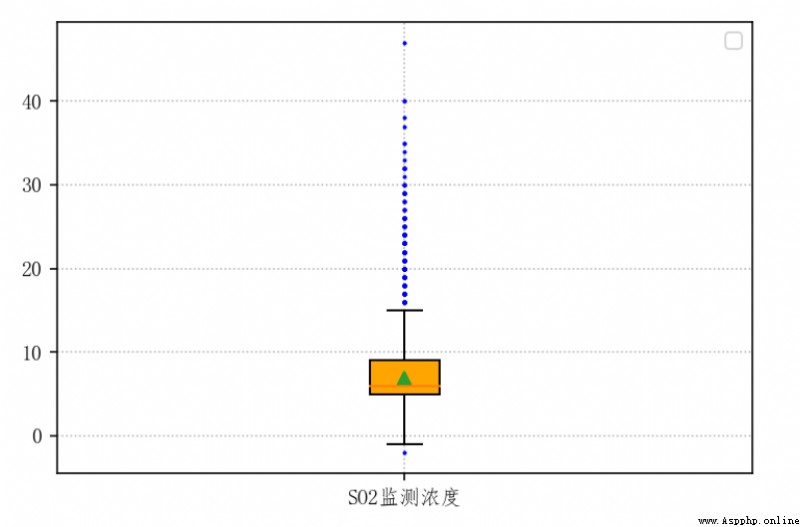
# 繪制箱線圖
plt.boxplot(
# 繪圖數據
so2,
# 填充箱體顏色
patch_artist=True,
# 顯示平均值,默認使用點顯示
showmeans=True,
# 設置箱子的寬度
widths=0.1,
# 設置箱子的樣式,需要 patch_artist=True
boxprops={
# 箱子的邊框為黑色
'color': 'k',
# 箱子的填充色為橙色
'facecolor': 'orange',
},
# 設置異常值點的樣式
flierprops={
# 設置點的形狀
'marker': '.',
# 設置點的填充色
'markerfacecolor': 'blue',
# 設置點的邊框色
'markeredgecolor': 'blue',
# 設置點的大小
'markersize': '2'
},
# 添加箱線圖在x軸對應位置的名字
# x軸坐標點名
labels=['SO2監測濃度'],
)
plt.grid(linestyle=':')
# 顯示圖例
plt.legend()
plt.show()
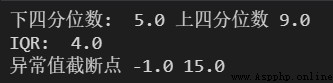
# 獲取 SO2監測濃度(μg/m³) 的上下四分位數
bottom, top = so2.quantile([.25, .75])
print('下四分位數: ', bottom, '上四分位數', top)
# 計算 IQR
IQR = top - bottom
print('IQR: ', IQR)
# 計算異常值截斷點
top_error = top + 1.5*IQR
bottom_error = bottom - 1.5*IQR
print('異常值截斷點', bottom_error, top_error)
# 復制數據集
data1 = data.copy()
data1 = data1[(so2>top_error) | (so2<bottom_error)]
data1
基於箱線圖檢測篩選出的 SO2監測濃度(μg/m³) 取值異常的行:
對於重復值可以根據需要,選擇對全部列進行去重,也可以選擇對某些列進行去重。
可以使用 DataFrame.drop_duplicates() 方法來處理重復值。
默認情況下,對所有的列進行去重,不在原表上進行修改,有重復值時默認保留重復值的第一個。
代碼示例:
l = [
np.array([1,2,3]),
np.array([1,1,2]),
np.array([1,1,2]),
np.array([1,1,1])
]
df = pd.DataFrame(l)
print(df)
print()
print(df.drop_duplicates())
print()
print(df)
l = [
np.array([1,2,3]),
np.array([1,1,2]),
np.array([1,1,2]),
np.array([1,1,1])
]
df = pd.DataFrame(l)
print(df)
print()
# 在原表上進行修改,無返回值
# 不在原表上進行修改,會返回修改後的新表
# 對第一第二列的數據進行去重,保留重復值的最後一個
print(df.drop_duplicates(subset=[0,1], inplace=True, keep='last'))
print()
print(df)