dask入門教程
並行計算庫Dask官方教程(中文翻譯)
dask和numpy的計算對比
並行計算:這是一台計算機的概念,即一台計算機中多個處理器被組織起來,大任務下達的時候,將大任務分成若干個小任務,然後分配給若干個處理器進行運算。
並行計算(Parallel Computing)是指同時使用多種計算資源解決計算問題的過程,是提高計算機系統計算速度和處理能力的一種有效手段。它的基本思想是用多個處理器來協同求解同一問題,即將被求解的問題分解成若干個部分,各部分均由一個獨立的處理器來並行計算。並行計算系統既可以是專門設計的、含有多個處理器的超級計算機,也可以是以某種方式互連的若干台的獨立計算機構成的集群。通過並行計算集群完成數據的處理,再將處理的結果返回給用戶。
並行計算可分為時間上的並行和空間上的並行。
時間上的並行:是指流水線技術,比如說工廠生產食品的時候步驟分為:
1. 清洗:將食品沖洗干淨。
2. 消毒:將食品進行消毒處理。
3. 切割:將食品切成小塊。
4. 包裝:將食品裝入包裝袋。
如果不采用流水線,一個食品完成上述四個步驟後,下一個食品才進行處理,耗時且影響效率。但是采用流水線技術,就可以同時處理四個食品。這就是並行算法中的時間並行,在同一時間啟動兩個或兩個以上的操作,大大提高計算性能。
空間上的並行:是指多個處理機並發的執行計算,即通過網絡將兩個以上的處理機連接起來,達到同時計算同一個任務的不同部分,或者單個處理機無法解決的大型問題。
比如小李准備在植樹節種三棵樹,如果小李1個人需要6個小時才能完成任務,植樹節當天他叫來了好朋友小紅、小王,三個人同時開始挖坑植樹,2個小時後每個人都完成了一顆植樹任務,這就是並行算法中的空間並行,將一個大任務分割成多個相同的子任務,來加快問題解決速度。
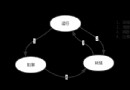
分布式計算:這個一組計算機的概念,通過計算機網絡連接起來,大任務下達的時候,將大任務分成若干個小任務,然後分配給若干個計算機進行運算。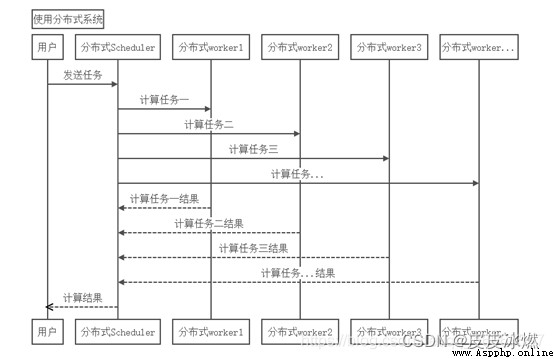
研究如何把一個需要非常巨大的計算能力才能解決的問題分成許多小的部分,然後把這些部分分配給許多計算機進行處理,最後把這些計算結果綜合起來得到最終的結果。
最近的分布式計算項目已經被用於使用世界各地成千上萬位志願者的計算機的閒置計算能力,通過因特網,可以分析來自外太空的電訊號,尋找隱蔽的黑洞,並探索可能存在的外星智慧生命;可以尋找超過1000萬位數字的梅森質數;也可以尋找並發現對抗艾滋病病毒的更為有效的藥物。這些項目都很龐大,需要驚人的計算量,僅僅由單個的電腦或是個人在一個能讓人接受的時間內計算完成是絕不可能的。
顯然,分布式計算非常強調計算機網絡中的計算機合作,並行式計算強調一個計算機的多個處理器合作。
(1)並行計算投入更多機器,數據大小不變,計算速度更快,而分布式計算投入更多的機器,能處理更大的數據;
(2)並行計算必須要求時間同步,而分布式計算沒有時間限制。
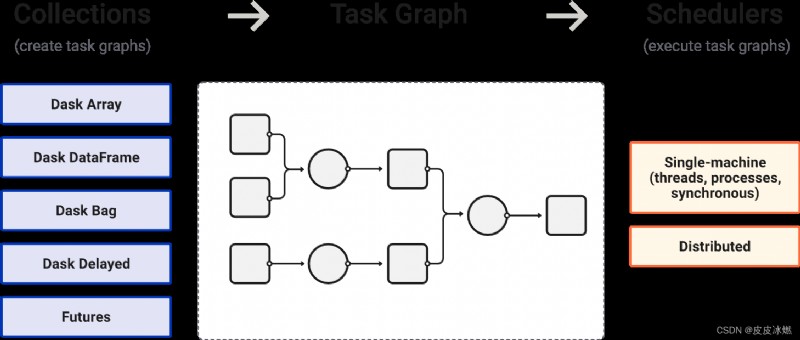
Dask是一個用於分析計算的靈活的並行計算庫。
pip install dask
python -m pip install "dask[array]"
python -m pip install "dask[distributed]"
python -m pip install "dask[dataframe]"
#dask求解10個數的平均值
import dask.array as da
import numpy as np
x=np.arange(10000000)
#chunks表示劃分時每塊的大小(大數據超過內存容量時,需要對數據進行按塊劃分)
y=da.from_array(x,chunks=(100,))
print(y)
print(y.mean())
print(y.mean().compute())
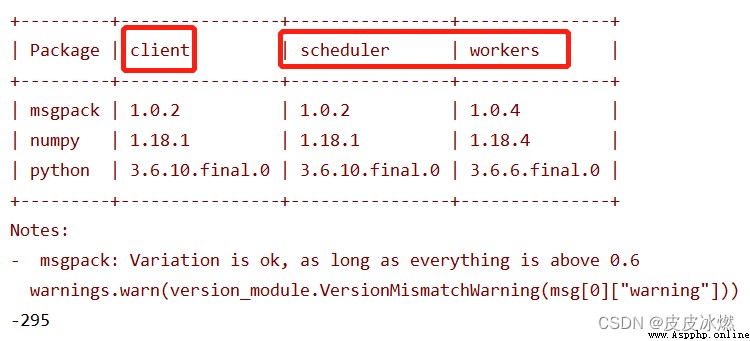
首先在命令行窗口執行dask-scheduler命令,得到以下輸出:
其中,tcp://192.168.1.4:8786可以做為當前電腦的url地址,在同一局域網下,可以在另一主機上通過client方法進行主機的連接。
(1)client內容為空或者為127.0.0.1.8786時,默認啟動本地調度工作程序(此時客戶端和本地客戶端應建立連接),客戶端將自身注冊為默認的Dask調度程序。
from dask.distributed import Client
if __name__ == "__main__":
client = Client()
a = client.map(lambda x:x**2,range(10))
b = client.map(lambda x:x+1,a)
c = client.map(lambda x:-x,b)
re = client.submit(sum, c).result()
print(re)
(2)當client不為空,為另一主機的url時:
這時首先在當前客戶機輸入命令:
dask-worker 192.168.1.4:8786
此時將scheduler和workers綁定在一起。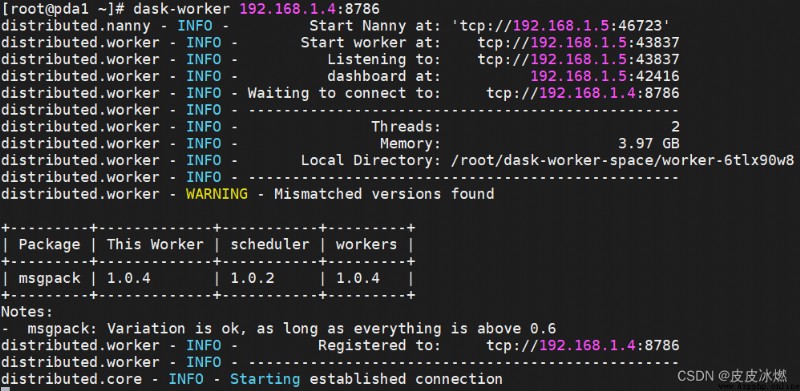
結果表示客戶機與主機連接成功,此時就能夠分布式利用不同主機間運行程序。
from dask.distributed import Client
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
a = client.map(lambda x:x**2,range(10))
b = client.map(lambda x:x+1,a)
c = client.map(lambda x:-x,b)
re = client.submit(sum, c).result()
print(re)
(1)submit(方法,數值), 對數值執行某種方法。
(2)若想顯示出來直觀的結果,則調用result()方法。
from dask.distributed import Client
def inc(x):
return x+1
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x1 = client.submit(inc,10)
print(x1)
print(x1.result())
x2 = client.map(inc,range(2))
print(x2)
print(client.gather(x2))
x3 = client.submit(sum,x2)
print(x3)
print(x3.result())
輸出如下:
<Future: pending, key: inc-d3f5af4d5bb89c246f58e2a8fa150373>
11
[<Future: pending, key: inc-9e50b1e0389d7a9c0a888ae20ae00cae>,
<Future: pending, key: inc-d78d089440e3814014b4f8e92775a40e>]
[1, 2]
<Future: pending, key: sum-36d98f2f40c36fc256240b1a9c0feadd>
3
(3)對於map()方法來說,map(方法,數值列表),通過遍歷數值列表的數值進行數值計算,想直觀的看到map()運行後的結果,需要調用client.garher(參數值)方法。
(4)對於submit和map等函數運行結果中都出現了key關鍵詞,可以試驗並且發現,當調用的函數是純函數時,所得的key應是完全一樣的,這就是dask中避免重復計算所才用的策略,當出現重復的計算時,只需要比較key的值就能利用舊的結果,而不需要重新計算。
from dask.distributed import Client
from operator import add
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x = client.submit(add,1,2)
y = client.submit(add,1,2)
print(x.key)
print(y.key)

(5)當函數不純時,眾所周知的就是random函數,每次執行的值都不同,但是函數是不變的,所以在dask中加入了一個參數:pure,當pure=False時,禁用以上功能。
from dask.distributed import Client
import numpy as np
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x = client.submit(np.random.random,3,pure=False)
y = client.submit(np.random.random,3,pure=False)
print(x.key)
print(y.key)
print(x.result())
print(y.result())

from dask.distributed import Client
import dask.dataframe as dd
if __name__ == "__main__":
client = Client("192.168.1.4:8786")
df = dd.read_csv("data.csv")
df = client.persist(df)
client.publish_dataset(my_data=df)
my_data是把數據集命一個新的名稱,在與調度機相連的任意客戶機都能訪問此數據集。
from dask.distributed import Client
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
print(client.list_datasets())
df = client.get_dataset("my_data")