活動地址:CSDN21天學習挑戰賽
學習的最大理由是想擺脫平庸,早一天就多一份人生的精彩;遲一天就多一天平庸的困擾。
正則表達式(regular expression,常寫為regex或RE),又稱規則表達式。正則表達式不是某種編譯語言特有的,而是計算機科學的一個概念,通常被用來檢索和替換符合某些規則的文本。幾乎所有字符串操作都可以通過正則表達式來完成,正則表達式的本質是一個特殊的字符序列,可以方便地查找一個字符串是否與我們定義的字符序列的某種模式相匹配。
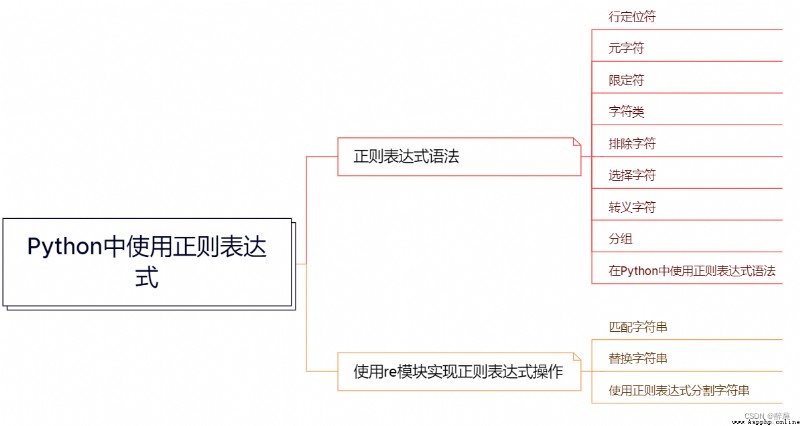
知識構架:
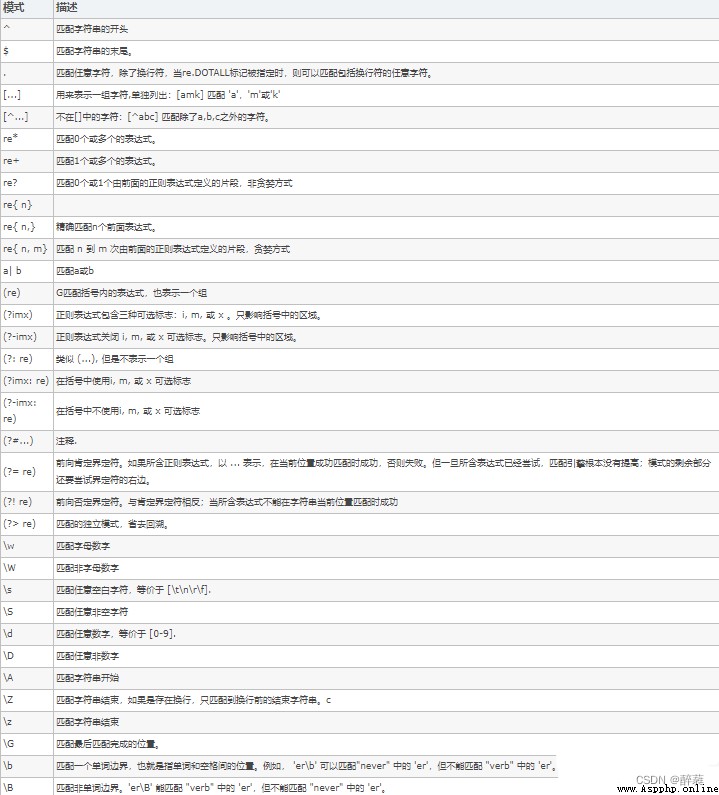
行定位符是描述字符串邊界的。例如“^”表示行的開始,“$”表示行的結尾。
舉個栗子:
1、^tm
2、tm$
第一個表達式表示要匹配字符串以tm開頭,如tm equal Tomorrow就可以匹配,而Tomorrow Moon equal tm 就不匹配,反而第二個式子能匹配這一個。如果要匹配的字符串可以出現在字符串的任意部分,那麼可以直接寫成“tm”
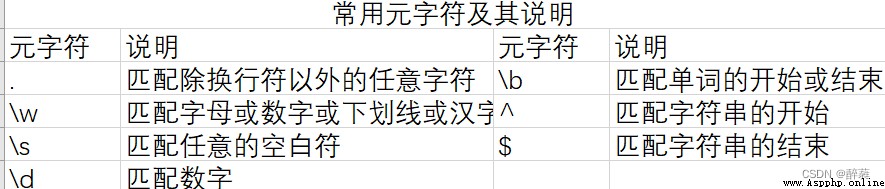
\bmr\w*\b
上面這個例子,匹配的是以字母mr開頭的單詞,先匹配單詞開始處(\b),然後匹配字母mr,接著匹配任意數量的字母或數字(\w*),最後匹配單詞結束處(\b)。即,該表達式可以匹配形如“mrsoft”,“mrbook”,“mr1234567”等。
在上面,我們使用了“\w*”來匹配任意數量的字母或數字。如果想匹配特定數量的數字則需要正則表達式的限定符(指定數量的字符)來實現。例如要匹配8位QQ可使用:
^d{8}$
匹配沒有預定義元字符的字符集合只需要在方括號裡列出他們即可。例如元音字母a,e,i,o,u。那麼,[aeiou]即匹配任何一個英文元音字母。[.?!]即可匹配標點符號“.”、“?”、“!”。當然,[0—9]代表含義於\d是一樣的,即代表一位數字。同理,如果只考慮英文的話,[a-z0-9A-Z]也完全等於\w。
正則表達式提供的字符“^”,表示行的開始,但這裡將會把它放進方括號中,表示排除的意思。
[^a-zA-Z] 用於匹配一個非字母的字符
選擇字符(|)。該字符可以理解為“或”。下面,以匹配身份證為例。
匹配身份證的表達式可以寫為:
(^\d{15}$)|(^\d{18}$)|(^\d{17})(\d|X|x)$
上述表達式的意思是可以匹配15位或18位或17位的數字和最後一位。需要注意的是最後一位可能是x也可能是X。
轉義字符(\)是將特殊字符“?”、“!”、“.”等變為普通字符的字符。
例如,我們要使用正則表達式匹配IP 127.0.0.1
直接用點字符寫會寫成:
[1-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}
但是這顯然是不對的!因為“.”可以匹配任意一個字符,因此,不僅是 127.0.0.1會被匹配,連1271011011也會被匹配。所以,在使用點字符時,需要使用轉義字符,即該IP應寫為:
[1-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}
通過剛才對身份證匹配的例子,我們發現小括號字符的第一個作用就是可以改變限定符的作用范圍,如“|”、“*”、“^”、等。
(one|two)th
這個表達式的意思是匹配單詞one或two。如果不用小括號的話就變成了匹配one和two了。
小括號的第二個作用就是分組,也就是子表達式。
如:
(.[0-9]{1,3}){3}
這個表達式就是對分組(.[0-9]{1,3})重復三次操作。
PS:括號在正則表達式中也算一個元字符。
在python中使用正則表達式是將其作為模式字符串使用的。
1、將匹配一個非字母字符的時候正則表達式轉換為模式字符串,可使用
‘[^a-zA-Z]’
2、匹配以字母m開頭的單詞的正則表達式轉換為模式字符串,則不能在其兩側添加引號定界符 ‘\bm\w*\b
由於模式字符串中可能包括大量的特殊字符和反斜槓,因此需要寫為原生字符串,即,在模式字符串前加r或R。如:r’\bm\w*\b’
貪婪匹配:正則表達式中包含重復的限定符時,通常的行為是匹配盡可能多的字符。
懶惰匹配:匹配盡可能少的字符。
例如: a.*b,它將會匹配最長的以a開始,以b結束的字符串。如果用它來搜索aabab的話,它會匹配整個字符串aabab。但此時需要匹配的是ab這樣的話就需要用到懶惰匹配了。
附: