參考教程:點這裡
目錄
pandas的series和dataFrame
pandas選擇數據
pandas設置值
pandas處理丟失數據NaN
pandas導入導出
pandas數據合並
pandas結合plot繪圖
END
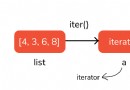
pandas和numpy的關系:numpy是列表,pandas是字典,pandas基於numpy構建。
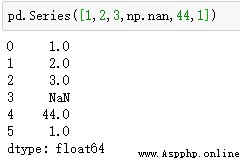
Series的形式:索引在左邊,值在右邊。沒有為數據指定索引會自動創建0到N-1(N為長度)的整數型索引。
DataFrame是一個表格型的數據結構,每列可以是不同的值類型,既有行索引也有列索引。
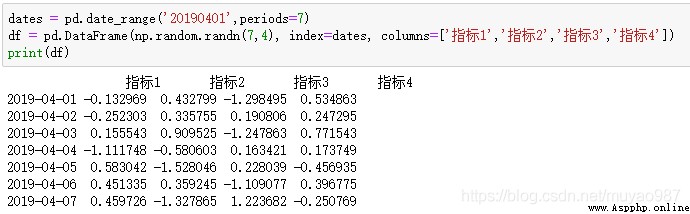
取df的“指標1”列:df['指標1']
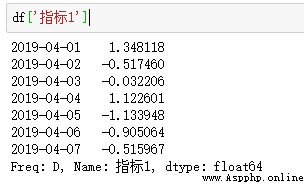
創建一組沒有給定行標簽和列標簽的數據:pd.DataFrame(np.arange(12).reshape((3,4)))
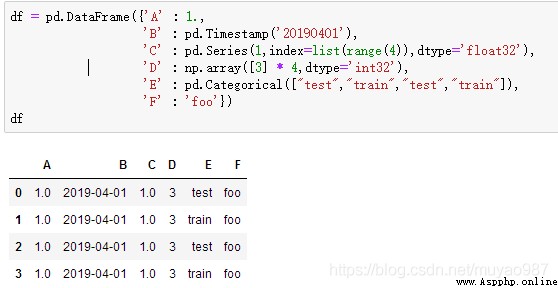
創建對每一列的數據進行特殊對待的數據:
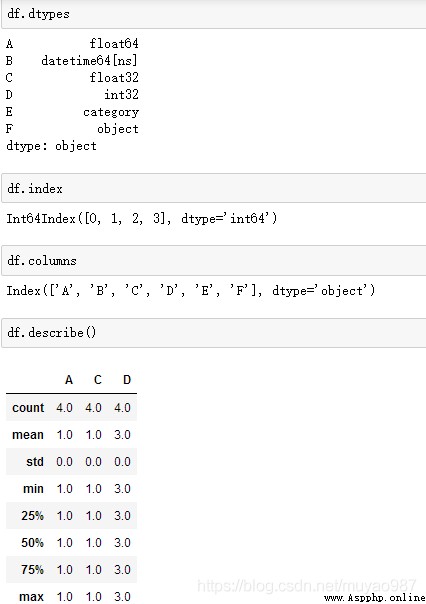
查看數據類型:df.dtypes
查看索引(行)的序號:df.index
查看每種數據(列)的名:df.columns
查看df的所有值:df.values
查看數據的總結(計數、平均值、最值等):df.describe()
翻轉數據:df.T
對數據的 index 進行排序:df.sort_index(axis=1, ascending=False)
對數據的 值 進行排序:df.sort_values(by='A')
選擇某列A: df['A'] 或 df.A
選擇0到2多列:df[0:2]
根據標簽選擇1行:df.loc[0] 【選擇索引為0的一行】
選擇所有行(: 代表所有行):df.loc[:,['A','B']] 【選擇所有行的A、B兩列】
df.loc[3,['A','B']] 【選擇第3行的A、B兩列】
根據位置(索引)進行選擇數據:df.iloc[3,1] 【第3行第1列的數據】
df.iloc[2:3,0:3] 【第2到3行,第0到3列的數據】
df.iloc[[0,3],0:3] 【第0、3行,第0到3列的數據】
通過判斷的篩選:df[df.A==2] 【選擇列A的值為2的行】
利用索引:df.iloc[2,2] = 1111 【修改第2行、 第2列】
利用標簽:df.loc['20190401','B'] = 2222 【修改行‘20190401’、 列‘B’】
根據條件:df.B[df.A>4] = 0 【列A大於4的都改成0】
按行或列:df['F'] = np.nan 【加上新列F,並設值為NaN】
df_original['title_keywords'] = ['' for _ in range(content_num)]
添加數據:df['G'] = pd.Series([1,2,3,4,5,6], index=pd.date_range('20190401',periods=6))

直接去掉有 NaN 的行或列(pd.dropna()):

將 NaN 的值用其他值代替(pd.fillna()):df.fillna(value=0) 【全替換成0】
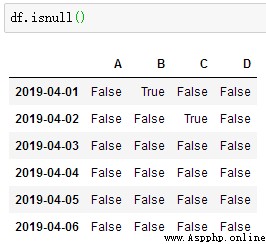
判斷每個值是否是缺失數據:df.isnull()
檢測整個數據表中是否存在 NaN, 如果存在就返回 True:np.any(df.isnull()) == True
pandas可以讀取與存取的格式:csv、excel、json、html、pickle等 【官方文檔】
讀取csv:data = pd.read_csv('student.csv')
將資料存取成pickle:data.to_pickle('student.pickle')
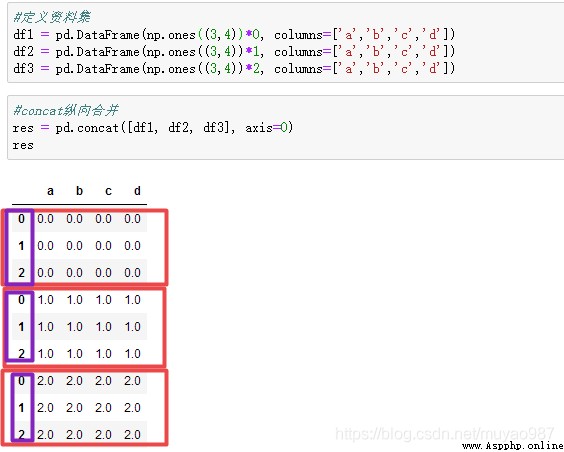
concat縱向合並:res = pd.concat([df1, df2, df3], axis=0) 【可以發現索引沒變】
concat參數之ignore_index (重置 index) :res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
concat參數之join (合並方式,默認join='outer') :res = pd.concat([df1, df2], axis=0, join='outer') 【依照column來做縱向合 並,有相同的column上下合並在一起,其他獨自的column個自成列,原本 沒有值的位置皆以NaN填充。】
concat參數之join (合並方式,改為join='inner') :res = pd.concat([df1, df2], axis=0, join='inner') 【只有相同的column合並 在一起,其他的會被拋棄】
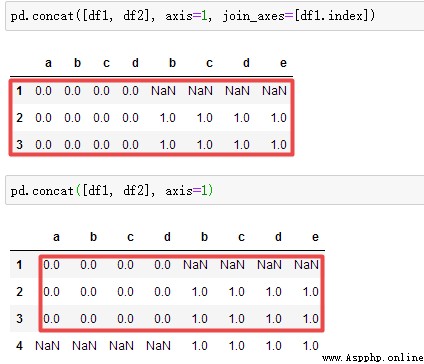
concat參數之join_axes:【根據df1的行索引來join,下圖2為去掉join_axes】
append只有縱向合並,沒有橫向合並:
df1.append(df2, ignore_index=True) 【將df2合並到df1的下面,重置index】
df1.append([df2, df3], ignore_index=True) 【合並多個df,將df2與df3合並至df1的下面,重置index】
df1.append(s1, ignore_index=True) 【合並series,將s1合並至df1,重置index】
merge用於兩組有key column的數據【樣例數據如下】
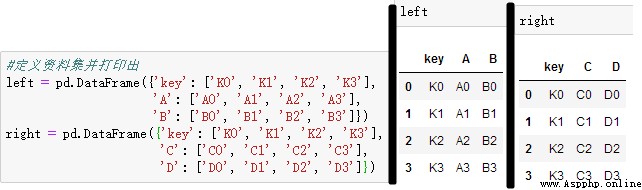
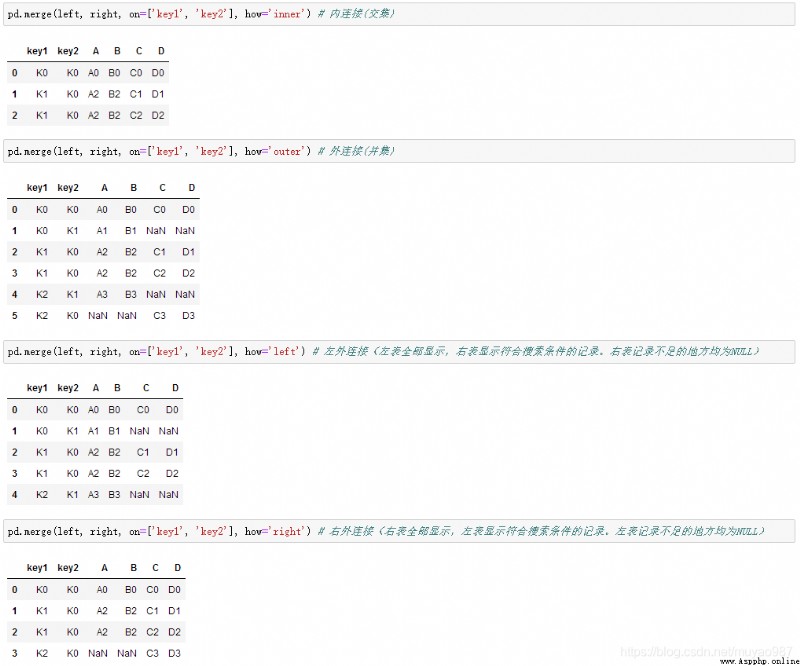
依據key1與key2 columns進行合並,並打印出四種結果['left', 'right', 'outer', 'inner']:
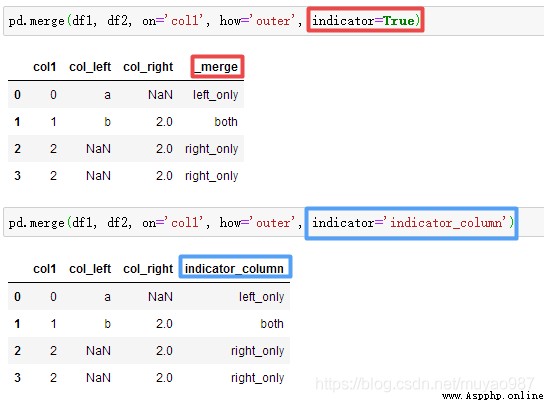
merge參數之indicator=True會將合並的記錄放在新的一列
merge參數之indicator=str,自定義列名
根據index合並:res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
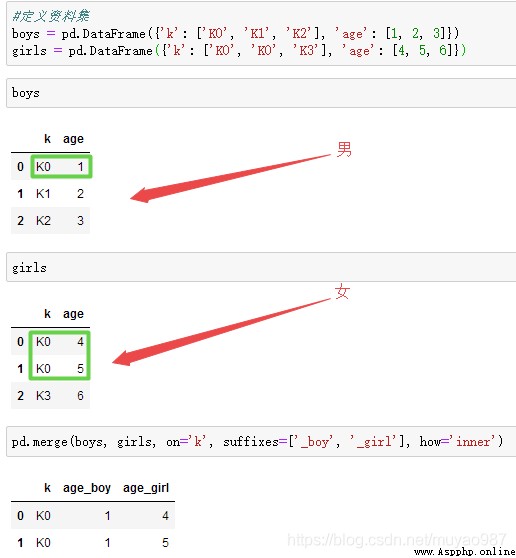
merge參數之suffixes解決overlapping(重疊)的問題 【名為K0的有一個1歲男、1個4歲女、1個5歲女】
import matplotlib.pyplot as plt
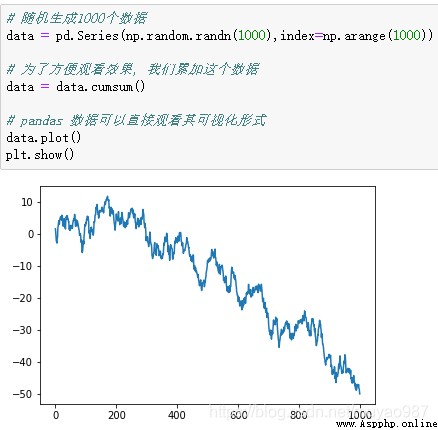
隨機生成1000個數據,Series 默認的 index 就是從0開始的整數
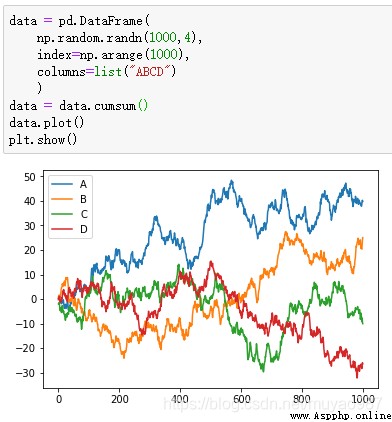
生成一個1000*4 的DataFrame,並對他們累加
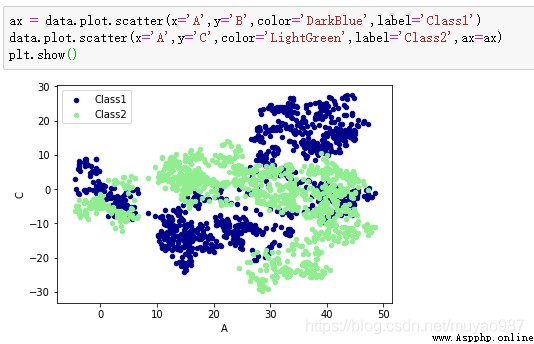
散點圖scatter只有x,y兩個屬性,我們我們就可以分別給x, y指定數據【下圖line1】
再畫一個在同一個ax上面,選擇不一樣的數據列,不同的 color 和 label【下圖line2】
顯示圖片【下圖line3】
 Analysis of level 2 real questions (judgment questions) of Python programming level examination for youth software programming of electronic society in June, 2021
Analysis of level 2 real questions (judgment questions) of Python programming level examination for youth software programming of electronic society in June, 2021
2021 year 6 month Python Analy
 Detailed explanation of Python TCP concurrent programming and code implementation - Taking the chat room implemented by Bio & NiO & AIO model as an example
Detailed explanation of Python TCP concurrent programming and code implementation - Taking the chat room implemented by Bio & NiO & AIO model as an example
Python TCP Concurrent programm