藍橋杯大賽的舉辦得到了教育部、工業和信息化部有關領導的高度重視,相關司局的大力支持,也得到了各省教育廳和各有關院校的積極響應,更得到了參賽師生的廣泛好評,參賽學校超過 1200 余所,參賽規模已達四十萬人次,取得了良好的社會效果。
省級在我們學校為B類,國家級則為A類,省級中獲一等獎的可參加國家級,因此比賽含金量高,建議大家好好把握
其中個人賽軟件類分:
本次競賽不分組別。所有研究生、重點本科、普通本科和高職高專院校均可報名該組,統一評獎。
全國選拔賽時長:4 小時。
總決賽時長:4 小時。
詳細賽程安排以組委會公布信息為准。
個人賽,一人一機,全程機考。選手機器通過局域網連接到賽場的競賽服務器。選手答題過程中無法訪問互聯網,也不允許使用本機以外的資源(如USB 連接)。競賽系統以“服務器-浏覽器”方式發放試題、回收選手答案。
選手機器配置:
X86兼容機器,內存不小於 4G ,硬盤不小於 60G
操作系統:Windows7 及以上
編程環境:
編譯器:Python 3.8.6
編輯器:IDLE Python 自帶編輯器
競賽題目完全為客觀題型。根據選手所提交答案的測評結果為評分依據。共有兩種題型。
結果填空題
題目描述一個具有確定解的問題。要求選手對問題的解填空。
不要求解題過程,不限制解題手段(可以使用任何開發語言或工具,甚至是手工計算),只要求填寫最終的結果。最終的解是一個整數或者是一個字符串,最終的解可以使用ASCII 字符表達。
編程大題
題目包含明確的問題描述、輸入和輸出格式,以及用於解釋問題的樣例數據。
編程大題所涉及的問題一定是有明確客觀的標准來判斷結果是否正確,並可以通過程序對結果進行評判。果進行評判。
選手應當根據問題描述,編寫程序(使用 Python 編寫)來解決問題,在評測時選手的程序應當從標准輸入讀入數據,並將最終的結果輸出到標准輸出中。
在問題描述中會明確說明給定的條件和限制,明確問題的任務,選手的程序應當能解決在給定條件和限制下的所有可能的情況。在給定條件和限制下的所有可能的情況。
選手的程序應當具有普遍性,不能只適用於題目的樣例數據。
為了測試選手給出解法的性能,評分時用的測試用例可能包含大數據量的壓力測試用例,選手選擇算法時要盡可能考慮可行性和效率問題。
Python程序設計基礎:包含使用 Python編寫程序的能力。該部分不考查選手對某一語法的理解程度,選手可以使用自己喜歡的語句編寫程序。
計算機算法:枚舉、排序、搜索、計數、貪心、動態規劃、圖論、數論、博弈論、概率論、計算幾何、字符串算法等。
數據結構:數組、對象/結構、字符串、隊列、棧、樹、圖、堆、平衡樹結構、字符串、隊列、棧、樹、圖、堆、平衡樹/線段樹、復雜數據線段樹、復雜數據結構、嵌套數據結構等。
選手只有在比賽時間內提交的答案內容是可以用來評測的,比賽之後的任何提交均無效。
選手應使用考試指定的網頁來提交代碼,任何其他方式的提交(如郵件、U盤)都不作為評測依據。
選手可在比賽中的任何時間查看自己之前提交的代碼,也可以重新提交任何題目的答案,對於每個試題,僅有最後的一次提交被保存並作為評測的依據。在比賽中,評測結果不會顯示給選手,選手應當在沒有反饋的情況下自行設計數據調試自己的程序。
對於每個試題,選手應將試題的答案內容拷貝粘貼到網頁上進行提交。
Python程序僅可以使用Python自帶的庫,評測時不會安裝其他的擴展庫。
程序中應只包含計算模塊,不要包含任何其他的模塊,比如圖形、系統接口調用、系統中斷等。對於系統接口的調用都應通過標准庫來進行。
程序中引用的庫應該在程序中以源代碼的方式寫出,在提交時也應當和程序的其他部分一起提交。
全部使用機器自動評分。對於結果填空題,題目保證只有唯一解,選手的結果只有和解完全相同才得分,出現格式錯誤或有多余內容時不得分。
對於編程大題,評測系統將使用多個評測數據來測試程序。每個評測數據有對應的分數。選手所提交的程序將分別用每個評測數據作為輸入來運行。對於某個評測數據,如果選手程序的輸出與正確答案是匹配的,則選手獲得該評測數據的分數。
評測使用的評測數據一般與試題中給定的樣例輸入輸出不一樣。因此建議選手在提交程序前使用不同的數據測試自己的程序。
提交的程序應嚴格按照輸出格式的要求來輸出,包括輸出空格和換行的要求。如果程序沒有遵循輸出格式的要求將被判定為答案錯誤。請注意,程序在輸出的時候多輸出了內容也屬於沒有遵循輸出格式要求的一種,所以在輸出的時候請不要輸出任何多余的內容,比如調試輸出。
試題由本人從歷年搜集並附了程序解答,由於本人編程能力有限,可能有錯或並非最優解,歡迎指正!
當初本人刷完題,將解答過程分享給老魏,最終老魏獲得了省二(成為我心中的陰影),說明刷題還是有一定幫助,希望大家能認真做好每一題。
題目描述
小藍給學生們組織了一場考試,卷面總分為100分,每個學生的得分都是一個0到100的整數。如果得分至少是60分,則稱為及格。如果得分至少為85分,則稱為優秀。請計算及格率和優秀率,用百分數表示,百分號前的部分四捨五入保留整數。
輸入描述
輸入的第一行包含一個整數 n (1≤n≤ 1 0 4 10^4 104),表示考試人數。接下來n行,每行包含一個0至100的整數,表示一個學生的得分。
輸出描述
輸出兩行,每行一個百分數,分別表示及格率和優秀率。百分號前的部分四捨五入保留整數。
n = int(input())
# 及格的數量
passNum = 0
# 優秀的數量
goodNum = 0
for _ in range(n):
score = int(input())
if score >= 60:
passNum += 1
if score >= 85:
goodNum += 1
print(str(round(passNum/n*100))+'%')
print(str(round(goodNum/n*100))+'%')
題目描述
FJ在沙盤上寫了這樣一些字符串:
A1 = “A”
A2 = “ABA”
A3 = “ABACABA”
A4 = “ABACABADABACABA”
… …
你能找出其中的規律並寫所有的數列AN嗎?
輸入描述
僅有一個數:N ≤ 26。
輸出描述
請輸出相應的字符串AN,以一個換行符結束。輸出中不得含有多余的空格或換行、回車符。
輸入樣例
3
輸出樣例
ABACABA
n = int(input())
result = ''
for i in range(n):
result = result + chr(ord('A') + i) + result
print(result)
題目描述
如果一個自然數N的K進制表示中任意的相鄰的兩位都不是相鄰的數字,那麼我們就說這個數是K好數。求L位K進制數中K好數的數目。例如K = 4,L = 2的時候,所有K好數為11、13、20、22、30、31、33 共7個。由於這個數目很大,請你輸出它對1000000007取模後的值。
輸入描述
輸入包含兩個正整數,K和L。
輸出描述
輸出一個整數,表示答案對1000000007取模後的值。
輸入樣例
4 2
輸出樣例
7
對於30%的數據,KL <= 106;
對於50%的數據,K <= 16, L <= 10;
對於100%的數據,1 <= K, L <= 100。
K, L = map(int, input().split())
count = 0
# dp[i][j]表示i + 1位上存放j的方法個數。
dp = [[0 for _ in range(K)] for _ in range(L)]
# 當只有一位時不管這位放哪個數字都只有一種方法
for i in range(0, K):
dp[0][i] = 1
# 當位數大等2位時
for i in range(1, L):
# 以2為數為例,j為十位,m為個位
for j in range(K):
for m in range(K):
# 不相鄰才能存放
if abs(j - m) != 1:
# 當前位數的放j情況的總個數 = 當前位置放j的個數 + 上一位置放[0,k)的總個數
dp[i][j] = dp[i][j]+dp[i-1][m]
dp[i][j] %= 1000000007
# 不斷遞歸下去,如三位數放k進制的個數 = 三位數的最高位(看成十位)放k進制的個數+兩位數(看成一個整體為個位)放k進制的個數
# L位數K好數的總個數
# i從1開始排除L位為最高位放0的情況
for i in range(1, K):
count += dp[L-1][i]
count %= 1000000007
print(count)
題目描述
在N*N的方格棋盤放置了N個皇後,使得它們不相互攻擊(即任意2個皇後不允許處在同一排,同一列,也不允許處在與棋盤邊框成45角的斜線上。
你的任務是,對於給定的N,求出有多少種合法的放置方法。
輸入描述
輸入N。
輸出描述
輸出一個整數,表示總共有多少種放法。
# 遞歸回溯思想解決n皇後問題,cur代表當前行,從0開始一行行遍歷
def queen(A, cur=0):
# 判斷上行放置的棋子是否有問題,如果有則回退
for row in range(cur-1):
# 由於是一行行遍歷肯定不存在同行,只需檢測是否同列和同對角線
# 若在該列或對角線上存在其他皇後
if A[row] - A[cur-1] == 0 or abs(A[row] - A[cur-1]) == cur - 1 - row:
# 該位置不能放
return
# 所有的皇後都正確放置完畢,輸出每個皇後所在的位置
if cur == len(A):
print(A)
return
# 行數=列數,遍歷每列
for col in range(len(A)):
# 當前行存儲皇後所在的列數
A[cur] = col
# 繼續放下一個皇後
queen(A, cur+1)
# n為8,就是著名的八皇後問題啦
n = int(input())
# 初始傳入8行的數組
queen([None] * n)
題目描述
給定一個n*n的棋盤,棋盤中有一些位置不能放皇後。現在要向棋盤中放入n個黑皇後和n個白皇後,使任意的兩個黑皇後都不在同一行、同一列或同一條對角線上,任意的兩個白皇後都不在同一行、同一列或同一條對角線上。問總共有多少種放法?n小於等於8。
輸入描述
輸入的第一行為一個整數n,表示棋盤的大小。
接下來n行,每行n個0或1的整數,如果一個整數為1,表示對應的位置可以放皇後,如果一個整數為0,表示對應的位置不可以放皇後。
輸出描述
輸出一個整數,表示總共有多少種放法。
輸入樣例
4
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
輸出樣例
2
輸入樣例
4
1 0 1 1
1 1 1 1
1 1 1 1
1 1 1 1
輸出樣例
0
# 先放置白皇後, cur代表當前行,從0開始一行行遍歷
def w_queen(cur=0):
# 判斷上行放置的棋子是否有問題,如果有則回退
for row in range(cur-1):
# 由於是一行行遍歷肯定不存在同行,只需檢測是否同列和同對角線
# 若在該列或對角線上存在其他皇後
if w_pos[row] - w_pos[cur-1] == 0 or abs(w_pos[row] - w_pos[cur-1]) == cur - 1 - row:
# 該位置不能放
return
# 當前顏色皇後都正確放置完畢
if cur == n:
# 放置另一種顏色的皇後
b_queen(0)
return
# 遍歷每列
for col in range(n):
# 如果該位置為1,則可以放置其子
if chessboard[cur][col] == 1:
# 記錄該棋子存放位置
w_pos[cur] = col
# 繼續放下一個皇後
w_queen(cur+1)
# 再放置黑皇後,與白皇後同理
def b_queen(cur=0):
global count
for row in range(cur-1):
if b_pos[row] - b_pos[cur-1] == 0 or abs(b_pos[row] - b_pos[cur-1]) == cur - 1 - row:
return
if cur == n:
# 兩種顏色皇後放置完畢,記錄次數
count += 1
return
for col in range(n):
# 如果該位置為1且沒有放白皇後,則可以放置其子
if chessboard[cur][col] == 1 and w_pos[cur] != col:
b_pos[cur] = col
b_queen(cur+1)
# 輸入
n = int(input())
# 初始化棋盤
chessboard = [[] for _ in range(n)]
for i in range(n):
arr = input().split()
for j in range(n):
chessboard[i].append(int(arr[j]))
# 用於記錄白皇後位置
w_pos = [0 for _ in range(n)]
# 用於記錄黑皇後位置
b_pos = [0 for _ in range(n)]
# 初始化多少種放法
count = 0
# 開始放置皇後
w_queen(0)
# 輸出多少種放法
print(count)
題目描述
最近FJ為他的奶牛們開設了數學分析課,FJ知道若要學好這門課,必須有一個好的三角函數基本功。所以他准備和奶牛們做一個“Sine之舞”的游戲,寓教於樂,提高奶牛們的計算能力。
不妨設
An=sin(1–sin(2+sin(3–sin(4+…sin(n))…)
Sn=(…(A1+n)A2+n-1)A3+…+2)An+1
FJ想讓奶牛們計算Sn的值,請你幫助FJ打印出Sn的完整表達式,以方便奶牛們做題。
輸入描述
僅有一個數:N<201。
輸出描述
請輸出相應的表達式Sn,以一個換行符結束。輸出中不得含有多余的空格或換行、回車符。
輸入樣例
3
輸出樣例
((sin(1)+3)sin(1–sin(2))+2)sin(1–sin(2+sin(3)))+1
def A(k, n):
if k == n:
return
print('sin(%d' % (k + 1), end='')
# 若後邊還有式子,判斷是輸出+號還是-號
if k + 1 != n:
if k % 2 == 1:
print('+', end='')
else:
print('-', end='')
# 若到底了,則輸出n個')'結束
else:
print(')'*n, end='')
k += 1
A(k, n) # 遞歸調用自身
n = int(input())
for i in range(n):
# 第一項n-1個括號開始
if i == 0:
print('('*(n-1), end='')
# 後續An+n-i)
A(0, i+1)
print('+%d' % (n-i), end='')
# 最後一項加完整數之和不必再輸出右括號
if i != n - 1:
print(')', end='')
題目描述
一個字符串的非空子串是指字符串中長度至少為1的連續的一段字符組成的串。例如,字符串aaab有非空子串a, b, aa, ab, aaa, aab, aaab,一共7個。 注意在計算時,只算本質不同的串的個數。請問,字符串0100110001010001有多少個不同的非空子串?
答案
100
str1 = '0100110001010001'
var = []
for i in range(1, len(str1)+1):
for j in range(len(str1) - i + 1):
if str1[j:j+i] not in var:
var.append(str1[j:j+i])
print(len(var))
題目描述
小明剛經過了一次數學考試,老師由於忙碌忘記排名了,於是老師把這個光榮的任務交給了小明,小明則找到了聰明的你,希望你能幫他解決這個問題。
輸入描述
第一行包含一個正整數N,表示有個人參加了考試。接下來N行,每行有一個字符串和一個正整數,分別表示人名和對應的成績,用一個空格分隔。
輸出描述
輸出一共有N行,每行一個字符串,第i行的字符串表示成績從高到低排在第i位的人的名字,若分數一樣則按人名的字典序順序從小到大。
輸入樣例
3
aaa 47
bbb 90
ccc 70
輸出樣例
bbb
ccc
aaa
人數<=100,分數<=100,人名僅包含小寫字母。
n = int(input())
inf = [list(input().split()) for _ in range(n)]
information.sort(key=lambda x: x[0]) # 先排姓名,按字母順序
information.sort(key=lambda x: int(x[1]), reverse=True) # 後排成績,從大到小
for i in range(n):
print(information[i][0])
題目描述
X星球的高科技實驗室中整齊地堆放著某批珍貴金屬原料。
每塊金屬原料的外形、尺寸完全一致,但重量不同。
金屬材料被嚴格地堆放成金字塔形。其中的數字代表金屬塊的重量(計量單位較大)。
最下一層的X代表30台極高精度的電子秤。假設每塊原料的重量都十分精確地平均落在下方的兩個金屬塊上,
最後,所有的金屬塊的重量都嚴格精確地平分落在最底層的電子秤上。
電子秤的計量單位很小,所以顯示的數字很大。工作人員發現,其中讀數最小的電子秤的示數為:2086458231
請你推算出:讀數最大的電子秤的示數為多少?
注意:需要提交的是一個整數,不要填寫任何多余的內容。
pyramid.txt:
7
5 8
7 8 8
9 2 7 2
8 1 4 9 1
8 1 8 8 4 1
7 9 6 1 4 5 4
5 6 5 5 6 9 5 6
5 5 4 7 9 3 5 5 1
7 5 7 9 7 4 7 3 3 1
4 6 4 5 5 8 8 3 2 4 3
1 1 3 3 1 6 6 5 5 4 4 2
9 9 9 2 1 9 1 9 2 9 5 7 9
4 3 3 7 7 9 3 6 1 3 8 8 3 7
3 6 8 1 5 3 9 5 8 3 8 1 8 3 3
8 3 2 3 3 5 5 8 5 4 2 8 6 7 6 9
8 1 8 1 8 4 6 2 2 1 7 9 4 2 3 3 4
2 8 4 2 2 9 9 2 8 3 4 9 6 3 9 4 6 9
7 9 7 4 9 7 6 6 2 8 9 4 1 8 1 7 2 1 6
9 2 8 6 4 2 7 9 5 4 1 2 5 1 7 3 9 8 3 3
5 2 1 6 7 9 3 2 8 9 5 5 6 6 6 2 1 8 7 9 9
6 7 1 8 8 7 5 3 6 5 4 7 3 4 6 7 8 1 3 2 7 4
2 2 6 3 5 3 4 9 2 4 5 7 6 6 3 2 7 2 4 8 5 5 4
7 4 4 5 8 3 3 8 1 8 6 3 2 1 6 2 6 4 6 3 8 2 9 6
1 2 4 1 3 3 5 3 4 9 6 3 8 6 5 9 1 5 3 2 6 8 8 5 3
2 2 7 9 3 3 2 8 6 9 8 4 4 9 5 8 2 6 3 4 8 4 9 3 8 8
7 7 7 9 7 5 2 7 9 2 5 1 9 2 6 5 3 9 3 5 7 3 5 4 2 8 9
7 7 6 6 8 7 5 5 8 2 4 7 7 4 7 2 6 9 2 1 8 2 9 8 5 7 3 6
5 9 4 5 5 7 5 5 6 3 5 3 9 5 8 9 5 4 1 2 6 1 4 3 5 3 2 4 1
X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X
arr = []
k = 0
file = open('pyramid.txt', 'r')
for line in file.readlines():
arr.append(list(map(int, line.split())))
arr.append([0]*30)
for i in range(1, 30):
for j in range(i):
arr[i][j] += arr[i - 1][j] / 2
arr[i][j + 1] += arr[i - 1][j] / 2
print(2086458231 / min(arr[-1]) * max(arr[-1]))
題目描述
如下的10行數據,每行有10個整數,請你求出它們的乘積的末尾有多少個零?注意:需要提交的是一個整數,表示末尾零的個數。不要填寫任何多余內容。
num.txt:
5650 4542 3554 473 946 4114 3871 9073 90 4329
2758 7949 6113 5659 5245 7432 3051 4434 6704 3594
9937 1173 6866 3397 4759 7557 3070 2287 1453 9899
1486 5722 3135 1170 4014 5510 5120 729 2880 9019
2049 698 4582 4346 4427 646 9742 7340 1230 7683
5693 7015 6887 7381 4172 4341 2909 2027 7355 5649
6701 6645 1671 5978 2704 9926 295 3125 3878 6785
2066 4247 4800 1578 6652 4616 1113 6205 3264 2915
3966 5291 2904 1285 2193 1428 2265 8730 9436 7074
689 5510 8243 6114 337 4096 8199 7313 3685 211
with open('num.txt') as file:
lines = file.readlines()
file.close
res = 0
for line in lines:
for num in line.split():
if res == 0:
res = int(num)
else:
res *= int(num)
count = 0
for i in str(res)[::-1]:
if i != '0':
break
count += 1
print(count)
題目描述
小藍正在學習一門神奇的語言,這門語言中的單詞都是由小寫字母組成,
有些單詞很長,遠遠超過正常英文單詞的長度。小藍學了很長時間也記不住一些單詞,
他准備不再完全記憶這些單詞,而是根據單詞中哪個字母出現的最多來分辨單詞。
請你幫助小藍,給了一些單詞後,幫助他找到出現最多的字母和這個字母出現的次數。
輸入描述
輸入一行包含一個單詞,單詞只有小寫英文字母組成。
輸出描述
輸出兩行,第一行包含一個英文字母,表示單詞中出現最多的字母是哪個。 如果有多個字母出現的次數相等,輸出字典序最小的那個。 第二行包含一個整數,表示出現的最多的那個字母在單詞中出現的次數。
輸入樣例
lanqiao
輸出樣例
a
2
輸入樣例
longlonglongistoolong
輸出樣例
o
6
word = input()
mapNum = {
}
# 次數最多的字母
maxV = None
# 最多次數
maxNum = 0
for v in word:
if v not in mapNum:
mapNum[v] = 1
else:
mapNum[v] += 1
keys = sorted(mapNum.keys())
for key in keys:
if mapNum[key] > maxNum:
maxV = key
maxNum = mapNum[key]
print(maxV)
print(maxNum)
題目描述
數學老師給小明出了一道等差數列求和的題目。但是粗心的小明忘記了一部分的數列,只記得其中N個整數。
現在給出這N個整數,小明想知道包含這N個整數的最短的等差數列有幾項?
輸入描述
輸入的第一行包含一個整數N。
第二行包含N個整數A1,A2,···,AN。(注意A1~AN並不一定是按等差數列中的順序給出)
輸出描述
輸出一個整數表示答案。
輸入樣例
5
2 6 4 10 20
輸出樣例
10
樣例說明
包含2、6、4、10、20的最短的等差數列是2、4、6、8、10、12、14、16、18、20。
n = int(input())
arr = list(map(int, input().split()))
min_gap = float("inf")
# 先排序
arr.sort()
# 找出等差數列的步長(各相鄰數差值最小的)
for i in range(1, n):
if arr[i] - arr[i-1] < min_gap:
min_gap = arr[i] - arr[i-1]
# 等差數列長度為(某項-首項)/步長+1
res = (arr[-1] - arr[0]) // min_gap + 1
print(res)
題目描述
2,3,5,7,11,13,…是素數序列。
類似:7,37,67,97,127,157 這樣完全由素數組成的等差數列,叫等差素數數列。
上邊的數列公差為30,長度為6。2004年,格林與華人陶哲軒合作證明了:存在任意長度的素數等差數列。
這是數論領域一項驚人的成果!有這一理論為基礎,請你借助手中的計算機,滿懷信心地搜索:
長度為10的等差素數列,其公差最小值是多少?
# 判斷是否為素數
def isprimy(n):
for i in range(2, int(float(n)**0.5) + 1):
if n % i == 0:
return False
return True
# 在一個范圍裡查找起點
for start in range(2, 4000):
# 不是素數則跳過
if not isprimy(start):
continue
# 查找公差
for diff in range(1, 400):
# 記錄數列長度
count = 1
# 下一個數值
next = start + diff
# 若仍為素數
while(isprimy(next)):
# 長度加1
count += 1
# 繼續判斷下一個數
next += diff
# 若長度大等10,則找到
if count >= 10:
print('起點:', start,'公差:', diff)
exit()
題目描述
完成一個遞歸程序,倒置字符數組,並打印實現過程。
遞歸邏輯為:
當字符長度等於1時,直接返回
否則,調換首尾兩個字符,再遞歸地倒置字符數組的剩下部分
輸入描述
字符數組長度及該數組
輸出描述
在求解過程中,打印字符數組的變化情況。
最後空一行,在程序結尾處打印倒置後該數組的各個元素。
輸入樣例
5 abcde
輸出樣例
ebcda
edcba
edcba
輸入樣例
1 a
輸出樣例
a
n, string = input().split()
if int(n) > 1:
l = 0
r = int(n) - 1
string = list(string)
while l <= r:
string[l], string[r] = string[r], string[l]
l += 1
r -= 1
print(''.join(string))
else:
print(string)
題目描述
在數列 a[1], a[2], …, a[n] 中,如果對於下標 i, j, k 滿足 0<i<j<k<n+1 且 a[i]<a[j]<a[k],則稱 a[i], a[j], a[k] 為一組遞增三元組,a[j]為遞增三元組的中心。
給定一個數列,請問數列中有多少個元素可能是遞增三元組的中心。
輸入描述
輸入的第一行包含一個整數 n。
第二行包含 n 個整數 a[1], a[2], …, a[n],相鄰的整數間用空格分隔,表示給定的數列。
輸出描述
輸出一行包含一個整數,表示答案。
輸入樣例
5
1 2 5 3 5
輸出樣例
2
樣例說明
a[2]和a[4]可能是三元組的中心。
n = int(input())
arr = list(map(int, input().split()))
count = 0
# 記錄該中心是否用過
data = []
for i in range(n):
for j in range(i + 1, n):
for k in range(j + 1, n):
if arr[i] < arr[j] < arr[k]:
if arr[j] not in data:
data.append(arr[j])
count += 1
print(count)
題目描述
到x星球旅行的游客都被發給一個整數,作為游客編號。
x星的國王有個怪癖,他只喜歡數字3,5和7。
國王規定,游客的編號如果只含有因子:3,5,7,就可以獲得一份獎品。
前10個幸運數字是:3 5 7 9 15 21 25 27 35 45,因而第11個幸運數字是:49
小明領到了一個幸運數字 59084709587505。
去領獎的時候,人家要求他准確說出這是第幾個幸運數字,否則領不到獎品。
請你幫小明計算一下,59084709587505是第幾個幸運數字。
輸出描述
輸出一個整數表示答案。
MAX = 59084709587505
# MAX = 49
a = [3, 5, 7]
s = set()
tou = 1
while True:
for i in a:
t = tou * i
if t <= MAX:
s.add(t)
lst = sorted(s)
for i in lst:
if i > tou:
tou = i
break
if tou >= MAX:
break
print(len(s)) # 1905
題目描述
小明買了塊高端大氣上檔次的電子手表,他正准備調時間呢。在 M78 星雲,時間的計量單位和地球上不同,M78 星雲的一個小時有 n 分鐘。大家都知道,手表只有一個按鈕可以把當前的數加一。在調分鐘的時候,如果當前顯示的數是 0 ,那麼按一下按鈕就會變成 1,再按一次變成 2 。如果當前的數是 n - 1,按一次後會變成 0 。作為強迫症患者,小明一定要把手表的時間調對。如果手表上的時間比當前時間多1,則要按 n - 1 次加一按鈕才能調回正確時間。
小明想,如果手表可以再添加一個按鈕,表示把當前的數加 k 該多好啊……
他想知道,如果有了這個 +k 按鈕,按照最優策略按鍵,從任意一個分鐘數調到另外任意一個分鐘數最多要按多少次。注意,按 +k 按鈕時,如果加k後數字超過n-1,則會對n取模。比如,n=10, k=6 的時候,假設當前時間是0,連按2次 +k 按鈕,則調為2。
輸入描述
一行兩個整數 n, k,意義如題。
輸出描述
一行一個整數。表示:按照最優策略按鍵,從一個時間調到另一個時間最多要按多少次。
輸入樣例
5 3
輸出樣例
2
樣例說明
如果時間正確則按0次。否則要按的次數和操作系列之間的關系如下:
1:+1
2:+1, +1
3:+3
4:+3, +1
對於 30% 的數據 0 < k < n <= 5
對於 60% 的數據 0 < k < n <= 100
對於 100% 的數據 0 < k < n <= 100000
資源約定:
峰值內存消耗(含虛擬機) < 256M
CPU消耗 < 1000ms
n, k = map(int, input().split())
res = 0
for i in range(1, n):
tmp = 0
while i >= k:
tmp += i // k
i %= k
tmp += i
if tmp > res:
res = tmp
print(res)
題目描述
隊列操作題。根據輸入的操作命令,操作隊列(1)入隊、(2)出隊並輸出、(3)計算隊中元素個數並輸出。
輸入描述
第一行一個數字N。
下面N行,每行第一個數字為操作命令:(1)入隊、(2)出隊並輸出、(3)計算隊中元素個數並輸出。
輸出描述
若干行每行顯示一個2或3命令的輸出結果。注意:2.出隊命令可能會出現空隊出隊(下溢),請輸出“no”,並退出。
輸入樣例
7
1 19
1 56
2
3
2
3
2
輸出樣例
19
1
56
0
no
n = int(input())
command = [list(map(int, input().split())) for _ in range(n)]
queue = []
print('輸出:')
for i in command:
if i[0] == 1:
queue.append(i[1])
if i[0] == 2:
if len(queue) < 1:
print('no')
else:
print(queue.pop(0))
if i[0] == 3:
if len(queue) < 1:
print(0)
else:
print(len(queue))
題目描述
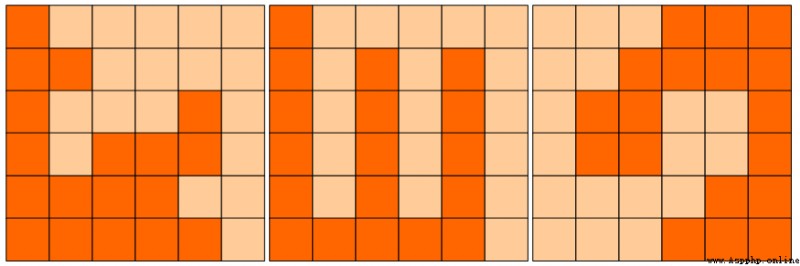
6x6的方格,沿著格子的邊線剪開成兩部分。要求這兩部分的形狀完全相同。如圖,就是可行的分割法。
試計算: 包括這3種分法在內,一共有多少種不同的分割方法。
注意:旋轉對稱的屬於同一種分割法。
請提交該整數,不要填寫任何多余的內容或說明文字。
''' 因為兩部分形狀相同,則必定經過中間點 從中間點(3,3)出發,向兩邊按格點走,行走的方式有向上、向下、向左、向右 當其中一邊達到邊界,根據對稱性,另一邊也到達邊界,則所有走過點的連線為一種分割方式 '''
def dfs(x, y):
global ans
# 到達邊界,分割完成
if x == 0 or x == 6 or y == 0 or y == 6:
ans += 1
return
# 4個出行可能性
for xy in dirs:
# 出發後的新索引
tx = x + xy[0]
ty = y + xy[1]
# 當前位置未走過
if arr_map[tx][ty] == 0:
# 標記為走過
arr_map[tx][ty] = 1
# 兩邊出發,根據對稱性,另一邊也標記為走過
arr_map[6-tx][6-ty] = 1
# 到達新位置後, 繼續搜尋下一步可能
dfs(tx, ty)
# 當進行到這步,則代表一種分割可能已經搜尋完,因此跳出了遞歸
# 則要將方格還原,進行下一種可能的搜尋
arr_map[tx][ty] = 0
arr_map[6-tx][6-ty] = 0
# 初始化方格代表(0,0)到(6,6)的位置
arr_map = [[0] * 7 for _ in range(7)]
# 4個方向
dirs = [(1,0), (-1,0), (0, 1), (0,-1)]
# 中間點置1 代表走過
arr_map[3][3] = 1
# 分割方法
ans = 0
# 從中間點索引往兩邊走
dfs(3,3)
# 由於旋轉對稱的屬於同一種分割方法,故最終結果要除以4
print(ans//4)
題目描述
求出區間[a,b]中所有整數的質因數分解。
輸入描述
輸入兩個整數a,b。
輸出描述
每行輸出一個數的分解,形如k=a1*a2*a3…(a1<=a2<=a3…,k也是從小到大的)
輸入樣例
3 10
輸出樣例
3=3
4=2*2
5=5
6=2*3
7=7
8=2*2*2
9=3*3
10=2*5
2<=a<=b<=10000
def factor(num):
# 遍歷該數的可能因子
# 最大因子只到該數的開方
for i in range(2, int(float(num)**0.5)+1):
# 若能找到因子
if num % i == 0:
# 輸出該因子
print(('%d*') % i, end='')
# 繼續分解
factor(num // i)
return
# 若找不到,返回本身
print(num, end='')
a, b = map(int, input().split())
# 遍歷該區間的數
for num in range(a, b+1):
print('%d='%num, end='')
factor(num)
print()
題目描述
1/1 + 1/2 + 1/4 + 1/8 + 1/16 + …
每項是前一項的一半,如果一共有20項,
求這個和是多少,結果用分數表示出來。
類似:
3/2
當然,這只是加了前2項而已。分子分母要求互質。注意:
需要提交的是已經約分過的分數,中間任何位置不能含有空格。
請不要填寫任何多余的文字或符號
# 最大公約數
def gcd(a, b):
while b != 0:
c = a % b
a = b
b = c
return a
# 分子
molecule = 0
# 因為1/1 + 1/2 + ... + 1/2^19通分後
# = 2^19/2^19 + 2^18/2^19 + ... + 1/2^19
# 則分子和為2^19 + 2^18 + ... + 1
for i in range(20):
molecule += 2 ** i
# 分母為2^19
gc = gcd(molecule, 2 ** 19)
# 輸出約分後的結果
print(molecule // gc , '/', 2 ** 19 // gc, sep='')
題目描述
從鍵盤讀入n個復數(實部和虛部都為整數)用鏈表存儲,遍歷鏈表求出n個復數的和並輸出。
輸入樣例
3
3 4
5 2
1 3
輸出樣例
9+9i
輸入樣例
7
1 2
3 4
2 5
1 8
6 4
7 9
3 7
輸出樣例
23+39i
n = int(input())
arr = [list(map(int, input().split())) for _ in range(n)]
real = 0
imaginary = 0
for i in range(n):
real += arr[i][0]
imaginary += arr[i][1]
print(real,'+',imaginary,'i', sep='')
題目描述
小明剛剛找到工作,老板人很好,只是老板夫人很愛購物。老板忙的時候經常讓小明幫忙到商場代為購物。小明很厭煩,但又不好推辭。
這不,XX大促銷又來了!老板夫人開出了長長的購物單,都是有打折優惠的。
小明也有個怪癖,不到萬不得已,從不刷卡,直接現金搞定。
現在小明很心煩,請你幫他計算一下,需要從取款機上取多少現金,才能搞定這次購物。取款機只能提供100元面額的紙幣。小明想盡可能少取些現金,夠用就行了。
你的任務是計算出,小明最少需要取多少現金。
以下是讓人頭疼的購物單,為了保護隱私,物品名稱被隱藏了。
**** 180.90 88折
**** 10.25 65折
**** 56.14 9折
**** 104.65 9折
**** 100.30 88折
**** 297.15 半價
**** 26.75 65折
**** 130.62 半價
**** 240.28 58折
**** 270.62 8折
**** 115.87 88折
**** 247.34 95折
**** 73.21 9折
**** 101.00 半價
**** 79.54 半價
**** 278.44 7折
**** 199.26 半價
**** 12.97 9折
**** 166.30 78折
**** 125.50 58折
**** 84.98 9折
**** 113.35 68折
**** 166.57 半價
**** 42.56 9折
**** 81.90 95折
**** 131.78 8折
**** 255.89 78折
**** 109.17 9折
**** 146.69 68折
**** 139.33 65折
**** 141.16 78折
**** 154.74 8折
**** 59.42 8折
**** 85.44 68折
**** 293.70 88折
**** 261.79 65折
**** 11.30 88折
**** 268.27 58折
**** 128.29 88折
**** 251.03 8折
**** 208.39 75折
**** 128.88 75折
**** 62.06 9折
**** 225.87 75折
**** 12.89 75折
**** 34.28 75折
**** 62.16 58折
**** 129.12 半價
**** 218.37 半價
**** 289.69 8折需要說明的是,88折指的是按標價的88%計算,而8折是按80%計算,余者類推。
特別地,半價是按50%計算。請提交小明要從取款機上提取的金額,單位是元。
答案是一個整數,類似4300的樣子,結尾必然是00,不要填寫任何多余的內容。
首先在把數據復制到記事本中,用Ctrl+H鍵替換,把****用空格替換,把7折、8折、9折替換為70、80、90,半價替換為50。item.txt:
180.90 88
10.25 65
56.14 90
104.65 90
100.30 88
297.15 50
26.75 65
130.62 50
240.28 58
270.62 80
115.87 88
247.34 95
73.21 90
101.00 50
79.54 50
278.44 70
199.26 50
12.97 90
166.30 78
125.50 58
84.98 90
113.35 68
166.57 50
42.56 90
81.90 95
131.78 80
255.89 78
109.17 90
146.69 68
139.33 65
141.16 78
154.74 80
59.42 80
85.44 68
293.70 88
261.79 65
11.30 88
268.27 58
128.29 88
251.03 80
208.39 75
128.88 75
62.06 90
225.87 75
12.89 75
34.28 75
62.16 58
129.12 50
218.37 50
289.69 80
file = open('item.txt', 'r')
ans = 0
for line in file.readlines():
price, rate = map(float, line.split())
ans += price * rate / 100
file.close()
print(ans)
題目描述
話說這個世界上有各種各樣的兔子和烏龜,但是研究發現,所有的兔子和烏龜都有一個共同的特點——喜歡賽跑。於是世界上各個角落都不斷在發生著烏龜和兔子的比賽,小華對此很感興趣,於是決定研究不同兔子和烏龜的賽跑。他發現,兔子雖然跑比烏龜快,但它們有眾所周知的毛病——驕傲且懶惰,於是在與烏龜的比賽中,一旦任一秒結束後兔子發現自己領先t米或以上,它們就會停下來休息s秒。對於不同的兔子,t,s的數值是不同的,但是所有的烏龜卻是一致——它們不到終點決不停止。
然而有些比賽相當漫長,全程觀看會耗費大量時間,而小華發現只要在每場比賽開始後記錄下兔子和烏龜的數據——兔子的速度v1(表示每秒兔子能跑v1米),烏龜的速度v2,以及兔子對應的t,s值,以及賽道的長度l——就能預測出比賽的結果。但是小華很懶,不想通過手工計算推測出比賽的結果,於是他找到了你——清華大學計算機系的高才生——請求幫助,請你寫一個程序,對於輸入的一場比賽的數據v1,v2,t,s,l,預測該場比賽的結果。
輸入描述
輸入只有一行,包含用空格隔開的五個正整數v1,v2,t,s,l,其中(v1, v2<=100; t<=300; s<=10; l<=10000且為v1, v2的公倍數)
輸出描述
輸出包含兩行,第一行輸出比賽結果——一個大寫字母“T”或“R”或“D”,分別表示烏龜獲勝,兔子獲勝,或者兩者同時到達終點。
第二行輸出一個正整數,表示獲勝者(或者雙方同時)到達終點所耗費的時間(秒數)。
輸入樣例
10 5 5 2 20
輸出樣例
D
4
輸入樣例
10 5 5 1 20
輸出樣例
R
3
輸入樣例
10 5 5 3 20
輸出樣例
T
4
v1, v2, t, s, l = map(int, input().split())
rabbit = 0
tortoise = 0
time = 0
flag = False
while True:
if rabbit == l or tortoise == l: # 如果兔子或烏龜到達終點,結束
break
if rabbit - tortoise >= t: # 兔子達到領先條件,休息
for i in range(s): # 休息時間按秒增加,烏龜路程按秒增加
tortoise += v2
time += 1
if tortoise == l:
# 兔子休息時,烏龜到達了終點,結束。
# 注意:有可能兔子在休息中,烏龜就到達了終點
# 所以休息時間未必循環完
# 如:兔子要休息10s,烏龜可能在兔子休息的第9s就到達了終點
# 這裡的flag就起到提前結束的功能
flag = True
break
if flag: # 如果提前結束,則全部結束
break
time += 1 # 每走一秒,兔子和烏龜按相應速度增加相應距離
rabbit += v1
tortoise += v2
if rabbit > tortoise: # 誰先到達終點,誰的距離大
print('R')
elif rabbit < tortoise:
print('T')
else: # 相等則平局
print('D')
print(time)
題目描述
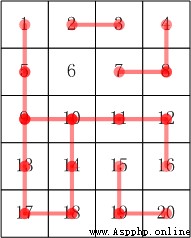
w星球的一個種植園,被分成 m * n 個小格子(東西方向m行,南北方向n列)。每個格子裡種了一株合根植物。
這種植物有個特點,它的根可能會沿著南北或東西方向伸展,從而與另一個格子的植物合成為一體。如果我們告訴你哪些小格子間出現了連根現象,你能說出這個園中一共有多少株合根植物嗎?
輸入描述
第一行,兩個整數m,n,用空格分開,表示格子的行數、列數(1<m,n<1000)。
接下來一行,一個整數k,表示下面還有k行數據(0<k<100000)
接下來k行,第行兩個整數a,b,表示編號為a的小格子和編號為b的小格子合根了。格子的編號一行一行,從上到下,從左到右編號。
比如:5 * 4 的小格子,編號:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
輸入樣例
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
輸出樣例
5
樣例說明
其合根情況參考下圖:
''' 並查集算法 '''
# 用於找到x的父節點
def rootFind(x):
p = x
#如果x的父節點不是他本身,就一直循壞到找到父節點為之
while x != pre[x]:
x = pre[x]
# 壓縮路徑,這個是優化的,所以可加可不加
while p != x: # 若當前節點不是父節點,找到父節點後,把沿途每個節點的根節點都設成父節點,使樹變得扁平,以減小深度
p, pre[p] = pre[p], x
return x
m, n = map(int, input().split())
cnt = m * n
# pre列表中存儲的是每個節點的父節點
pre = [i for i in range(cnt+1)]
k = int(input())
for i in range(k):
a,b = map(int, input().split())
roota = rootFind(a)
rootb = rootFind(b)
if roota != rootb:
# 如果父節點不一樣就合並, 選任意一方為父
pre[roota] = pre[rootb]
#同時合並的話,集合就會少一個
cnt -= 1
print(cnt)
題目描述
x星球的鈔票的面額只有:100元,5元,2元,1元,共4種。
小明去x星旅游,他手裡只有2張100元的x星幣,太不方便,恰好路過x星銀行就去換零錢。
小明有點強迫症,他堅持要求200元換出的零鈔中2元的張數剛好是1元的張數的10倍,
剩下的當然都是5元面額的。銀行的工作人員有點為難,你能幫助算出:在滿足小明要求的前提下,最少要換給他多少張鈔票嗎?
(5元,2元,1元面額的必須都有,不能是0)
# 總共200元
total = 200
# 由於2元是1元的10倍,即扣掉5元鈔票的錢數,應為21的倍數
# 要使換的錢數最少,則5元的鈔票要多
for i in range(1, 200 // 21):
total -= 21
if total % 5 == 0:
# 共換了多少張鈔票
count = 10 * i + i + total // 5
print(count)
break
題目描述
回形取數就是沿矩陣的邊取數,若當前方向上無數可取或已經取過,則左轉90度。一開始位於矩陣左上角,方向向下。
輸入描述
輸入第一行是兩個不超過200的正整數m, n,表示矩陣的行和列。接下來m行每行n個整數,表示這個矩陣。
輸出描述
輸出只有一行,共mn個數,為輸入矩陣回形取數得到的結果。數之間用一個空格分隔,行末不要有多余的空格。
輸入樣例
3 3
1 2 3
4 5 6
7 8 9
輸出樣例
1 4 7 8 9 6 3 2 5
輸入樣例
3 2
1 2
3 4
5 6
輸出樣例
1 3 5 6 4 2
m, n = map(int, input().split())
matrix = [[] for _ in range(m)]
for i in range(m):
arr = input().split()
for j in range(n):
matrix[i].append(int(arr[j]))
# 初始位置
x, y = 0, 0
# 外框到裡框的個數
for i in range(min(m, n)//2+1):
# 向下取數
while x < m and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 將去過的位置置為-1
x += 1
# 上個循環結束後x多加一次要減回來
x -= 1
# 列值加1,因為第零列在上個循環已經輸出,往右推一行
y += 1
# 向右取數
while y < n and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 將去過的位置置為-1
y += 1
# 上個循環多加一次減回來
y -= 1
# 往上推一行
x -= 1
# 向上取數
while x >= 0 and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 將去過的位置置為-1
x -= 1
# 上個循環使多減一次加回來
x += 1
# 往左推一行
y -= 1
# 向左取數
while y >= 0 and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 將去過的位置置為-1
y -= 1
# 上個循環多加一次減回來
y += 1
# 向下推一行
x += 1
題目描述
在電影《金陵十三钗》中有十二個秦淮河的女人要自我犧牲代替十二個女學生去赴日本人的死亡宴會。為了不讓日本人發現,自然需要一番喬裝打扮。但由於天生材質的原因,每個人和每個人之間的相似度是不同的。由於我們這是編程題,因此情況就變成了金陵n钗。給出n個女人和n個學生的相似度矩陣,求她們之間的匹配所能獲得的最大相似度。
所謂相似度矩陣是一個n*n的二維數組
like[i][j]。其中i, j分別為女人的編號和學生的編號,皆從0到n-1編號。like[i][j]是一個0到100的整數值,表示第i個女人和第j個學生的相似度,值越大相似度越大,比如0表示完全不相似,100表示百分之百一樣。每個女人都需要找一個自己代替的女學生。最終要使兩邊一一配對,形成一個匹配。請編程找到一種匹配方案,使各對女人和女學生之間的相似度之和最大。
輸入描述
第一行一個正整數n表示有n個秦淮河女人和n個女學生
接下來n行給出相似度,每行n個0到100的整數,依次對應二維矩陣的n行n列。
輸出描述
僅一行,一個整數,表示可獲得的最大相似度。
輸入樣例
4
97 91 68 14
8 33 27 92
36 32 98 53
73 7 17 82
輸出樣例
354
樣例說明
最大相似度為91+92+98+73=354
對於70%的數據,n<=10
對於100%的數據,n<=13
# 本題類似n皇後問題,先列舉出所有可能,在求其中和最大
def queen(cur=0):
global maxSum
# 判斷上行的棋子放置是否有問題
for row in range(cur-1):
# 若該女學生已被其他女人匹配
if res[row] == res[cur-1]:
# 向上回溯
return
# 若匹配完畢
if cur == n:
# 算出當前排列的和
cur_sum = 0
for i in range(n):
cur_sum += matrix[i][res[i]]
# 儲存最大和
if cur_sum > maxSum:
maxSum = cur_sum
return
# 遍歷每列
for col in range(n):
# 設置秦淮河女人匹配的女學生
res[cur] = col
# 對下一個秦淮河女人進行匹配
queen(cur+1)
n = int(input())
# 相似度矩陣
matrix = [list(map(int, input().split())) for _ in range(n)]
res = [0 for _ in range(n)]
maxSum = 0
queen()
print(maxSum)
題目描述
給定一個N階矩陣A,輸出A的M次冪(M是非負整數)
例如:
A =
1 2
3 4
A的2次冪
7 10
15 22
輸入描述
第一行是一個正整數N、M(1<=N<=30, 0<=M<=5),表示矩陣A的階數和要求的冪數
接下來N行,每行N個絕對值不超過10的非負整數,描述矩陣A的值
輸出描述
輸出共N行,每行N個整數,表示A的M次冪所對應的矩陣。相鄰的數之間用一個空格隔開
輸入樣例
2 2
1 2
3 4
輸出樣例
7 10
15 22
# 矩陣乘法
def mul_matrix(matrix1, matrix2, n):
# 存放乘法後的矩陣
res = [[] for _ in range(n)]
# 遍歷每個元素
for i in range(n):
for j in range(n):
pos = 0
# 乘法後所得結果該位置的值等於兩個數組該行和該列的加權
for c in range(n):
pos += matrix1[i][c] * matrix2[c][j]
res[i].append(pos)
return res
# 輸入
n, m = map(int, input().split())
matrix = [[] for _ in range(n)]
for i in range(n):
arr = input().split()
for j in range(n):
matrix[i].append(int(arr[j]))
# 初始化單位矩陣
res = [[1 if i == j else 0 for j in range(n)] for i in range(n)]
# m次冪
for i in range(1, m+1):
res = mul_matrix(res, matrix, n)
# 輸出結果
for i in range(n):
for j in range(n):
print(res[i][j], end=' ')
print()
題目描述
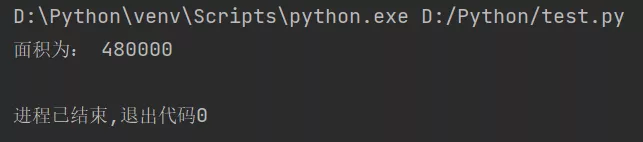
平面上有兩個矩形,它們的邊平行於直角坐標系的X軸或Y軸。對於每個矩形,我們給出它的一對相對頂點的坐標,請你編程算出兩個矩形的交的面積。
輸入描述
輸入僅包含兩行,每行描述一個矩形。
在每行中,給出矩形的一對相對頂點的坐標,每個點的坐標都用兩個絕對值不超過 1 0 7 10^7 107的實數表示。
輸出描述
輸出僅包含一個實數,為交的面積。
輸入樣例
1 1 3 3
2 2 4 4
輸出樣例
1
rect1 = list(map(float, input().split()))
rect2 = list(map(float, input().split()))
x1 = max(min(rect1[0], rect1[2]), min(rect2[0], rect2[2]))
y1 = max(min(rect1[1], rect1[3]), min(rect2[1], rect2[3]))
x2 = min(max(rect1[0], rect1[2]), max(rect2[0], rect2[2]))
y2 = min(max(rect1[1], rect1[3]), max(rect2[1], rect2[3]))
# 交集的面積
inter = max(x2-x1, 0) * max(y2-y1, 0)
print(inter)
題目描述
今天小明的任務是填滿這麼一張表: 表有n行n列,行和列的編號都從1算起。 其中第i行第j個元素的值是gcd(i, j)的平方,gcd表示最大公約數,以下是這個表的前四行的前四列:
1 1 1 1
1 4 1 4
1 1 9 1
1 4 1 16小明突然冒出一個奇怪的想法,他想知道這張表中所有元素的和。 由於表過於龐大,他希望借助計算機的力量。
輸入描述
一行一個正整數n意義見題。
輸出描述
一行一個數,表示所有元素的和。由於答案比較大,請輸出模 (10^9 + 7)後的結果。
輸入樣例
4
輸出樣例
48
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-KhPfAxjo-1654839635670)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/%E7%9F%A9%E9%98%B5%E6%B1%82%E5%92%8C.png)]
''' 方法一:暴力求解會超時 # 求最大公約數 def gcd(i, j): while j !=0: k = i % j i, j = j, k return i n = int(input()) sum_arr = 0 mod = 10 ** 9 + 7 for i in range(1, n+1): for j in range(1, n+1): t = gcd(i, j) ** 2 sum_arr += t % mod print(sum_arr) '''
'''方法二:歐拉函數(線性篩法)推薦'''
MOD = 10 ** 9 + 7
# 歐拉函數
phi = []
# 存放[1, n/d]中,所有互質對的個數
sum_ = []
# 結果
ans = 0
def euler_table(n):
# 初始化
for _ in range(n + 1):
phi.append(0)
sum_.append(0)
# n=1時的歐拉函數為1
phi[1] = 1
# 求到n為止的歐拉函數(線性篩法)
for i in range(2, n + 1):
# ph[i]為0時代表沒遍歷過,則此時i為素數
if phi[i] == 0:
j = i
while j <= n:
# 先令phi[j] = j,則ph[j] / i = j / i = i^(k-1)
if phi[j] == 0:
phi[j] = j
# 當i是素數時 phi(i) = i-1
# phi(i^k) = i^(k-1) * (i-1)
# 這裡j = i^k
phi[j] = phi[j] // i * (i - 1)
# 進行遞推,求得相應的phi[j],使phi[j]上的值不再為0,那麼下次遍歷i時,若為0,則代表i為素數
j += i
sum_[1] = 1
# 遞推,求互質對的個數
for i in range(2, n + 1):
sum_[i] = sum_[i - 1] + phi[i] * 2
n = int(input())
euler_table(n)
for i in range(1, n + 1):
# 將問題轉化成了count(d)*d*d
ans = (ans + sum_[n // i] * i % MOD * i) % MOD
print(ans)
題目描述
小藍要為一條街的住戶制作門牌號。
這條街一共有 2020 位住戶,門牌號從 1 到 2020 編號。
小藍制作門牌的方法是先制作 0 到 9 這幾個數字字符,最後根據需要將字符粘貼到門牌上,例如門牌 1017 需要依次粘貼字符 1、0、1、7,即需要 1 個字符 0,2 個字符 1,1 個字符 7。
請問要制作所有的 1 到 2020 號門牌,總共需要多少個字符 2?
這是一道結果填空的題,你只需要算出結果後提交即可。
本題的結果為一個整數,在提交答案時只填寫這個整數,填寫多余的內容將無法得分。
count = 0
for num in range(1, 2021):
count += str(num).count("2")
print(count)
題目描述
下圖給出了一個迷宮的平面圖,其中標記為 1 的為障礙,標記為 0 的為可 以通行的地方。
010000
000100
001001
110000迷宮的入口為左上角,出口為右下角,在迷宮中,只能從一個位置走到這 個它的上、下、左、右四個方向之一。 對於上面的迷宮,從入口開始,可以按DRRURRDDDR 的順序通過迷宮, 一共 10 步。其中 D、U、L、R 分別表示向下、向上、向左、向右走。
對於下面這個更復雜的迷宮(30 行 50 列),請找出一種通過迷宮的方式, 其使用的步數最少,在步數最少的前提下,請找出字典序最小的一個作為答案。 請注意在字典序中D<L<R<U。
data.txt:
01010101001011001001010110010110100100001000101010
00001000100000101010010000100000001001100110100101
01111011010010001000001101001011100011000000010000
01000000001010100011010000101000001010101011001011
00011111000000101000010010100010100000101100000000
11001000110101000010101100011010011010101011110111
00011011010101001001001010000001000101001110000000
10100000101000100110101010111110011000010000111010
00111000001010100001100010000001000101001100001001
11000110100001110010001001010101010101010001101000
00010000100100000101001010101110100010101010000101
11100100101001001000010000010101010100100100010100
00000010000000101011001111010001100000101010100011
10101010011100001000011000010110011110110100001000
10101010100001101010100101000010100000111011101001
10000000101100010000101100101101001011100000000100
10101001000000010100100001000100000100011110101001
00101001010101101001010100011010101101110000110101
11001010000100001100000010100101000001000111000010
00001000110000110101101000000100101001001000011101
10100101000101000000001110110010110101101010100001
00101000010000110101010000100010001001000100010101
10100001000110010001000010101001010101011111010010
00000100101000000110010100101001000001000000000010
11010000001001110111001001000011101001011011101000
00000110100010001000100000001000011101000000110011
10101000101000100010001111100010101001010000001000
10000010100101001010110000000100101010001011101000
00111100001000010000000110111000000001000000001011
10000001100111010111010001000110111010101101111000
''' path = [[0,1,0,0,0,0], [0,0,0,1,0,0], [0,0,1,0,0,1], [1,1,0,0,0,0]] '''
path =[]
with open("data.txt") as file:
contents = file.readlines()
for i in contents:
path.append(list(map(int, list(i.strip()))))
# 迷宮的實質就是一個矩陣,即用(x,y)即可表示迷宮內的任意一點,再用一個字符串w來表示路徑。
class Node:
def __init__(self, x, y, w):
self.x = x # 記錄橫坐標
self.y = y # 記錄縱坐標
self.w = w # 記錄路徑
def __str__(self):
return self.w # 輸出路徑
def up(node):
return Node(node.x - 1, node.y, node.w+"U") # 上的情況
def down(node):
return Node(node.x + 1, node.y, node.w+"D") # 下的情況
def left(node):
return Node(node.x, node.y - 1, node.w+"L") # 左的情況
def right(node):
return Node(node.x, node.y + 1, node.w+"R") # 右的情況
if __name__ == '__main__':
row, col = len(path), len(path[0]) # 矩陣的長和寬
visited = set() # 記錄訪問過的點
queue = []
node = Node(0, 0, "") # 設置起點
# 存放進隊列
queue.append(node)
# 由於每次開始移動前先彈出,若後續沒步走,則隊列為0,結束
while len(queue) != 0:
moveNode = queue[0] # 設置當前移動點為moveNode
# 開始移動前先彈出
queue.pop(0)
moveStr = str(moveNode.x) + " "+ str(moveNode.y) # 用於記錄當前坐標是否走過
# 若沒走過則進行記錄
if moveStr not in visited:
visited.add(moveStr)
if moveNode.x == row - 1 and moveNode.y == col - 1: # 若到達終點則輸出且退出循環
print(len(moveNode.__str__())) # 輸出步數
print(moveNode) # 打印路徑
break
if moveNode.x < row - 1 : # 首先順序為下,不能超出邊界
# 若沒有障礙物,則可以通行
if path[moveNode.x + 1][moveNode.y] == 0:
# 添加進隊列
queue.append(down(moveNode))
if moveNode.y > 0: # 第二順序是左
if path[moveNode.x][moveNode.y - 1] == 0:
queue.append(left(moveNode))
if moveNode.y < col - 1: # 第三順序是右
if path[moveNode.x][moveNode.y + 1] == 0:
queue.append(right(moveNode))
if moveNode.x > 0: # 最後順序是上
if path[moveNode.x - 1][moveNode.y] == 0:
queue.append(up(moveNode))
題目描述
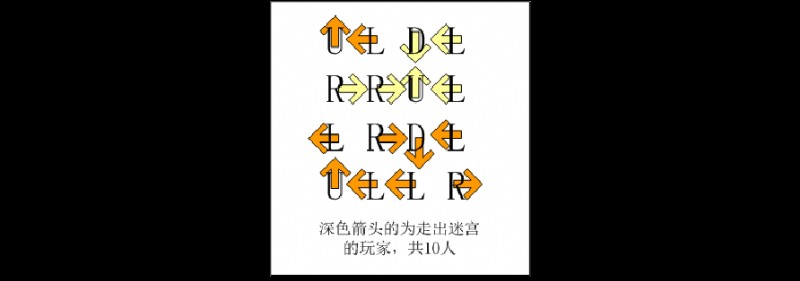
X星球的一處迷宮游樂場建在某個小山坡上。它是由10x10相互連通的小房間組成的。房間的地板上寫著一個很大的字母。
我們假設玩家是面朝上坡的方向站立,則:L表示走到左邊的房間,R表示走到右邊的房間,U表示走到上坡方向的房間,D表示走到下坡方向的房間。
X星球的居民有點懶,不願意費力思考。他們更喜歡玩運氣類的游戲。這個游戲也是如此!
開始的時候,直升機把100名玩家放入一個個小房間內。玩家一定要按照地上的字母移動。
請你計算一下,最後,有多少玩家會走出迷宮?而不是在裡邊兜圈子。
如果你還沒明白游戲規則,可以參看一個簡化的4x4迷宮的解說圖:
迷宮地圖迷宮2.txt如下:
UDDLUULRUL
UURLLLRRRU
RRUURLDLRD
RUDDDDUUUU
URUDLLRRUU
DURLRLDLRL
ULLURLLRDU
RDLULLRDDD
UUDDUDUDLL
ULRDLUURRR
def dfs(x, y):
global count
global rows
global cols
# 走出迷宮,計數+1
if x < 0 or x > rows-1 or y < 0 or y > cols-1:
count += 1
return
# 若當前位置未走過,則標記為走過
if paths[x][y] == 0:
paths[x][y] = 1
# 若已走過,則代表回到原路,走不出迷宮,退出
else:
return
# 獲取方向
direction = dataMap[x][y]
# 上
if direction == 'U':
dfs(x-1, y)
# 下
if direction == 'D':
dfs(x+1, y)
# 左
if direction == 'L':
dfs(x, y-1)
# 右
if direction == 'R':
dfs(x, y+1)
# 存儲地圖
dataMap = []
with open('迷宮2.txt', mode='r', encoding='utf-8') as f:
for line in f.readlines():
dataMap.append(list(line.strip()))
rows = len(dataMap)
cols = len(dataMap[0])
# 記錄走出人數
count = 0
for x in range(rows):
for y in range(cols):
# 用於記錄走過的軌跡,未走過為0,走過為1
paths = [[0]*cols for _ in range(rows)]
dfs(x, y)
print(count)
題目描述
小明用字母A 對應數字1,B 對應2,以此類推,用Z 對應26。對於27以上的數字,小明用兩位或更長位的字符串來對應,例如AA 對應27,AB 對應28,AZ 對應52,LQ 對應329。請問2019 對應的字符串是什麼?
ans = ''
n = 2019
while n != 0:
t = n % 26
n = n // 26
ans += chr(64+t)
print(ans[::-1])
題目描述
小藍每天都鍛煉身體。
正常情況下,小藍每天跑1千米。如果某天是周一或者月初(1日),為了激勵自己,小藍要跑2千米。如果同時是周一或月初,小藍也是跑2千米。
小藍跑步已經堅持了很長時間,從2000年1月1日周六(含)到2020年10月1日周四(含)。請問這段時間小藍總共跑步多少千米
# 遍歷日期可以用到datetime這個內置庫
import datetime
# 一個是初始日期,一個是結束日期,因為range函數是半開半閉,所以結束日期要比要求的大一天
start = datetime.datetime(2000, 1, 1, 0, 0, 0)
end = datetime.datetime(2020, 10, 2, 0, 0, 0)
sum = 0
# 用結束日期-初始日期就能得到之間相差的天數。也就是遍歷次數
for day in range(int((end - start).days)):
# 再用初始天數,加上每次遍歷的天數,就可以得到當前日期
# 使用timedelta可以很方便的在日期上做天days,小時hour,分鐘,秒,毫秒,微妙的時間計算
cur_date = start + datetime.timedelta(days=day)
# 用.strftime()方法可以訪問這一天的各種參數
# 獲取天數和星期,為1日或星期1跑2km
if (cur_date.strftime('%d')) == '01' or (cur_date.strftime('%w')) == '1':
sum += 2
# 否則為1km
else:
sum += 1
print(sum)
題目描述
平面上有 N條直線,其中第i條直線是 y = Ai*x + B。
請計算這些直線將平面分成了幾個部分。
輸入描述
第一行包含一個整數N。
以下N行,每行包含兩個整數Ai, Bi。
輸出描述
一個整數代表答案。
輸入樣例
3
1 1
2 2
3 3
輸出樣例
6
# 在同一個平面內,如果添加的每一條直線互不相交,則每添加一條直線,就會增加一個平面;
# 當添加一條直線時,這條直線與當前平面內已有直線每產生一個不同位置的交點時
# 這條直線對平面總數量的貢獻會額外增多一個
n = int(input())
lines = [tuple(map(int, input().split())) for _ in range(n)]
#這裡是去掉重復直線
lines = list(set(lines))
n = len(lines)
#得到兩條直線交點,若平行,返回None
def getnode(lines1, lines2):
A1 = lines1[0]
B1 = lines1[1]
A2 = lines2[0]
B2 = lines2[1]
if A1 - A2 == 0:
return
x = (B2 - B1) / (A1 - A2)
y = A1 * x + B1
return (x, y)
# 每條線對分割平面的貢獻 默認為1,即兩兩平行
ci = [1] * n
# 交點去重
node = set()
for i in range(1, n):
node.clear()
# 判斷新增加的線與之前線是否有交點
for j in range(i):
tmp = getnode(lines[i], lines[j])
if tmp == None: continue
node.add(tmp)
# 每有個交點貢獻多1
ci[i] += len(node)
print(sum(ci) + 1)
題目描述
你有一張某海域NxN像素的照片,".“表示海洋、”#"表示陸地,如下所示:
....... .##.... .##.... ....##. ..####. ...###. .......其中"上下左右"四個方向上連在一起的一片陸地組成一座島嶼。例如上圖就有2座島嶼。
由於全球變暖導致了海面上升,科學家預測未來幾十年,島嶼邊緣一個像素的范圍會被海水淹沒。具體來說如果一塊陸地像素與海洋相鄰(上下左右四個相鄰像素中有海洋),它就會被淹沒。
例如上圖中的海域未來會變成如下樣子:
....... ....... ....... ....... ....#.. ....... .......請你計算:依照科學家的預測,照片中有多少島嶼會被完全淹沒。
輸入描述
第一行包含一個整數N。 (1 <= N <= 1000)
以下N行N列代表一張海域照片。
照片保證第1行、第1列、第N行、第N列的像素都是海洋。
輸出描述
一個整數表示答案。
輸入樣例
7
…
.##…
.##…
…##.
…####.
…###.
…
輸出樣例
1
''' 思路: 在接收初始圖之後,首先搜索查找初始島嶼數,在找到一個島嶼後,對整個島嶼進行標記,防止重復計數。 隨後再次進行搜索,如果有四周均為陸地的坐標,則標記此坐標未被淹沒。 最後查找所有未被淹沒的坐標,並將坐標所處的整個島標記,防止重復計數。 初始島嶼數量減去未被淹沒島的數量,即為被淹沒的島的數量。 '''
'''例子1: 輸入: 7 ....... .##.... .##.... ....##. ..####. ...###. ....... 輸出: 1 '''
'''例子2: 輸入: 5 ..... .#.#. ..#.. .#.#. ..... 輸出: 5 '''
# 用於搜尋島嶼的數量
def dfs(x, y):
# 如果該點是海洋或者已被訪問過則跳過
if maps[x][y] == '.' or maps[x][y] == '1':
return
# 否則將該點標記為1,代表已訪問過
maps[x][y] = '1'
# 搜索該點四周的點
dfs(x+1, y)
dfs(x-1, y)
dfs(x, y+1)
dfs(x, y-1)
n = int(input())
# 初始海洋照片
maps = [list(input()) for _ in range(n)]
# 初始島嶼個數
first_num = 0
# 剩余島嶼個數
res_num = 0
# 初始島嶼個數
for x in range(n):
for y in range(n):
if maps[x][y] == '#':
dfs(x, y)
first_num += 1
# 海域未來模樣
for x in range(n):
for y in range(n):
# 照片保證第1行、第1列、第N行、第N列的像素都是海洋。
if x == 0 or x == n-1 or y == 0 or y == n-1 or maps[x][y] == '.':
continue
# 四周都是陸地則標記為2,代表該島嶼不會被淹沒
if maps[x+1][y] != '.' and maps[x-1][y] != '.' and maps[x][y+1] != '.' and maps[x][y-1] != '.':
maps[x][y] = '2'
# 否則標記為3代表將被淹沒
else:
maps[x][y] = '3'
# 最後查找剩余多少個島嶼
for x in range(n):
for y in range(n):
if maps[x][y] == '2':
dfs(x, y)
res_num += 1
# 輸出淹沒了多少座島
print(first_num - res_num)
題目描述
如下圖所示,小明用從1開始的正整數“蛇形”填充無限大的矩陣。
1 2 6 7 15 …
3 5 8 14 …
4 9 13 …
10 12 …
11 …
…
容易看出矩陣第二行第二列中的數是5。請你計算矩陣中第20行第20列的數是多少?
lis = [[0 for i in range(40)] for j in range(40)]
num = 1 # 記錄當前的數
for i in range(1, 41): # 層數
for j, k in zip(list(range(i)), list(range(num, num + i))):
if i % 2 == 0: # 偶數層
lis[j][i-j-1] = k
else:
lis[i-j-1][j] = k
num += i
print(lis[19][19])
題目描述
石子游戲的規則如下:
地上有n堆石子,每次操作可選取兩堆石子(石子個數分別為x和y)並將它們合並,操作的得分記為(x+1)×(y+1),對地上的石子堆進行操作直到只剩下一堆石子時停止游戲。
請問在整個游戲過程中操作的總得分的最大值是多少?
輸入描述
輸入數據的第一行為整數n,表示地上的石子堆數;第二行至第n+1行是每堆石子的個數。
輸出描述
程序輸出一行,為游戲總得分的最大值。
輸入樣例
10
5105
19400
27309
19892
27814
25129
19272
12517
25419
4053
輸出樣例
15212676150
1≤n≤1000,1≤一堆中石子數≤50000
# 堆數
n = int(input())
# 每堆石子的個數
data = [int(input()) for i in range(n)]
# 先排序
data.sort()
# 分數
result = 0
# 貪心算法,每次取最大兩堆合並
while len(data) != 1:
result += (data[-1] + 1) * (data[-2] + 1)
data[-2] += data[-1]
data.pop(-1)
print(result)
題目描述
給定一個以秒為單位的時間t,要求用H:M:S的格式來表示這個時間。H表示時間,M表示分鐘,而S表示秒,它們都是整數且沒有前導的“0”。例如,若t=0,則應輸出是“0:0:0”;若t=3661,則輸出“1:1:1”。
輸入描述
輸入只有一行,是一個整數t(0<=t<=86399)。
輸出描述
輸出只有一行,是以“H:M:S”的格式所表示的時間,不包括引號。
輸入樣例
0
輸出樣例
0:0:0
輸入樣例
5436
輸出樣例
1:30:36
t = int(input())
print('%d:%d:%d'%(t//3600, t%3600//60, t%3600%60))
題目描述
Tom教授正在給研究生講授一門關於基因的課程,有一件事情讓他頗為頭疼:一條染色體上有成千上萬個鹼基對,它們從0開始編號,到幾百萬,幾千萬,甚至上億。比如說,在對學生講解第1234567009號位置上的鹼基時,光看著數字是很難准確的念出來的。
所以,他迫切地需要一個系統,然後當他輸入1234567009時,會給出相應的念法:十二億三千四百五十六萬七千零九,用漢語拼音表示為shi er yi san qian si bai wu shi liu wan qi qian ling jiu,這樣他只需要照著念就可以了。
你的任務是幫他設計這樣一個系統:給定一個阿拉伯數字串,你幫他按照中文讀寫的規范轉為漢語拼音字串,相鄰的兩個音節用一個空格符格開。
注意必須嚴格按照規范,比如說“10010”讀作“yi wan ling yi shi”而不是“yi wan ling shi”,“100000”讀作“shi wan”而不是“yi shi wan”,“2000”讀作“er qian”而不是“liang qian”。
輸入描述
有一個數字串,數值大小不超過2,000,000,000。
輸出描述
是一個由小寫英文字母,逗號和空格組成的字符串,表示該數的英文讀法。
輸入樣例
1234567009
輸出樣例
shi er yi san qian si bai wu shi liu wan qi qian ling jiu
n = input()
# 數值讀法
pin_yin = {
'0': 'ling', '1': 'yi', '2': 'er', '3': 'san', '4': 'si', '5': 'wu',
'6': 'liu', '7': 'qi', '8': 'ba', '9': 'jiu'}
# 特殊位置讀法
pin_yin_2 = {
0: '', 1: 'shi', 2: 'bai', 3: 'qian', 4: 'wan', 5: 'shi',
6: 'bai', 7: 'qian', 8: 'yi', 9: 'shi'}
# 個位的索引
l = len(n) - 1
# 從最高位開始遍歷
for i in range(len(n)):
# 當前位的值
cur = int(n[i])
# 當前位的值不為0時的讀法
if cur != 0:
# 個位與當前位索引相差1,、5、9,即在十位,十萬位,十億位置且開頭為1時
# 不讀出1
# 如10, shi ; 100000, shi wan; 1000000000, shi yi
if cur == 1 and i == 0 and (l - i == 1 or l - i == 5 or l - i == 9):
print(pin_yin_2[l - i], end=' ')
continue
# 輸出當前數的讀法
print(pin_yin[n[i]], end=' ')
# 輸出指定位置的讀法
print(pin_yin_2[l - i], end=' ')
# 處理當前位的值為0的讀法問題
else:
# 如果此0是在萬位或億位,則讀出萬或億
# 如shi wan, shi yi
if l - i == 4 or l - i == 8:
print(pin_yin_2[l - i], end=' ')
# 如果後一位仍然為0,或者,當前是最後一位,則不讀此0
elif (i < l and n[i + 1] == '0') or i == l:
continue
else:
# 否則才讀出這個零
print(pin_yin['0'], end=' ')
題目描述
把 2019 分解成 3 個各不相同的正整數之和,並且要求每個正整數都不包含數字 2 和 4,一共有多少種不同的分解方法?注意交換 3 個整數的順序被視為同一種方法,例如 1000+1001+18 和 1001+1000+18 被視為同一種。
count = 0
# 因為三個數要各不相同 i從小到大 j從小到大並比i大,則為了保證不重,k也因比j大
for i in range(1, 2019):
if '2' not in str(i) and '4' not in str(i):
for j in range(i + 1, 2019):
if '2' not in str(j) and '4' not in str(j):
k = 2019 - i - j
if k > j and '2' not in str(k) and '4' not in str(k):
count += 1
print(count)
題目描述
本題為填空題,只需要算出結果後,在代碼中使用輸出語句將所填結果輸出即可。
給定數列 1, 1, 1, 3, 5, 9, 17,⋯,從第 4 項開始,每項都是前 3 項的和。求第 20190324 項的最後 4 位數字。
f0=1
f1=1
f2=1
for i in range(3, 20190324):
result = (f0 + f1 + f2) % 10000
f0 = f1
f1 = f2
f2 = result
print(result)
題目描述
一個正整數如果任何一個數位不大於右邊相鄰的數位,則稱為一個數位遞增的數,例如1135是一個數位遞增的數,而1024不是一個數位遞增的數。
給定正整數 n,請問在整數 1 至 n 中有多少個數位遞增的數?
輸入描述
輸入的第一行包含一個整數n。
輸出描述
輸出一行包含一個整數,表示答案。
輸入樣例
30
輸出樣例
26
對於 40% 的評測用例,1 <= n <= 1000。
對於 80% 的評測用例,1 <= n <= 100000。
對於所有評測用例,1 <= n <= 1000000。
n = int(input())
count = 0
for i in range(1, n+1):
num = str(i)
if len(num) == 1:
count += 1
else:
flag = True
for j in range(len(num) - 1):
if num[j] > num[j+1]:
flag = False
break
if flag:
count += 1
print(count)
題目描述
在1至2019中,有多少個數的數位中包含數字9?
注意,有的數中的數位中包含多個9,這個數只算一次。例如,1999這個數包含數字9,在計算只是算一個數。
count = 0
for num in range(1, 2020):
if '9' in str(num):
count += 1
print(count)
題目描述
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-gEFTOQq2-1654839635671)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/tri.png)]
圖為一個數字三角形。 請編一個程序計算從頂至底的某處的一條路徑,使該路徑所經過的數字的總和最大。
● 每一步可沿左斜線向下或右斜線向下走;
● 1<三角形行數≤100;
● 三角形中的數字為整數0,1,…99;
輸入描述
首先讀到的是三角形的行數。
接下來描述整個三角形
輸出描述
最大總和(整數)
輸入樣例
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
輸出樣例
30
def pathMax(path, x, y, leftNum, rightNum):
global n
# 添加當前路徑
path.append(pyramid[x][y])
# 如果走到底返回
if x == n-1:
# 左下和右下次數相差不超過1,記錄路徑
if abs(leftNum - rightNum) <= 1:
paths.append(path)
return
pleft = []
pright = []
pleft += path
pright += path
# 左下走
pathMax(pleft, x+1, y, leftNum+1, rightNum)
# 右下走
pathMax(pright, x+1, y+1, leftNum, rightNum+1)
n = int(input())
pyramid = [list(map(int, input().split())) for _ in range(n)]
# 用於所有可能路徑
paths = []
pathMax([], 0, 0, 0, 0)
res = 0
# 返回最大路徑
for path in paths:
tmp = sum(path)
if tmp > res:
res = tmp
print(res)
題目描述
小明對數位中含有2 、 0 、 1 、 9 的數字很感興趣(不包括前導 0 ),在 1 到 40 中這樣的數包括 1 、 2 、 9 、 10 至 32 、 39 和 40 ,共 28 個,他們的和是 574 。請問,在1 到 n 中,所有這樣的數的和是多少?
輸入描述
輸入一行包含一個整數n。
輸出描述
輸出一行,包含一個整數,表示滿足條件的數的和。
輸入樣例
40
輸出樣例
574
res = 0
for i in range(1, int(input())+1):
if '2' in str(i) or '0' in str(i) or '1' in str(i) or '9' in str(i):
res += i
print(res)
題目描述
123321是一個非常特殊的數,它從左邊讀和從右邊讀是一樣的。
輸入一個正整數n, 編程求所有這樣的五位和六位十進制數,滿足各位數字之和等於n 。
輸入描述
輸入一行,包含一個正整數n。
輸出描述
按從小到大的順序輸出滿足條件的整數,每個整數占一行。
輸入樣例
52
輸出樣例
899998
989989
998899
1<=n<=54
import time
n = int(input())
start = time.perf_counter()
#6位數,n一定為偶數
if (n % 2 == 0):
s = n // 2
if s <= 27:
for i in range(1, 10):
for j in range(10):
if (s - i - j) < 10 and (s - i - j) >= 0:
print(int(str(i)+str(j)+str(s-i-j)*2+str(j)+str(i)))
#5位數,n減去中間那個數一定為偶數
for i in range(9, -1, -1):
if (n - i) % 2 == 0:
s = (n - i) // 2
if s <= 18:
for j in range(1, 10):
if (s - j) >= 0 and (s - j) < 10:
print(int(str(j)+str(s-j)+str(i)+str(s-j)+str(j)))
end = time.perf_counter()
print(end - start)
題目描述
回文串,是一種特殊的字符串,它從左往右讀和從右往左讀是一樣的。小龍龍認為回文串才是完美的。現在給你一個串,它不一定是回文的,請你計算最少的交換次數使得該串變成一個完美的回文串。
交換的定義是:交換兩個相鄰的字符,例如mamad
第一次交換 ad : mamda
第二次交換 md : madma
第三次交換 ma : madam (回文!完美!)
輸入描述
第一行是一個整數N,表示接下來的字符串的長度(N <= 8000)
第二行是一個字符串,長度為N.只包含小寫字母
輸出描述
如果可能,輸出最少的交換次數。
否則輸出Impossible
輸入樣例
5
mamad
輸出樣例
3
n = int(input())
arr = list(input())
# 統計出現奇數次的字符的個數
flag = 0
# 交換次數
count = 0
# 由於最後形成回文,只需遍歷一半即可
for i in range(n//2):
# 從另一半尋找是否有字符與之相等
for j in range(n-1, i - 1, -1):
# 沒找到
if j == i:
# 記錄奇數個數的字符
flag += 1
# 如果有一個字符出現的次數是奇數次數,而且n是偶數,那麼不可能構成回文
if n % 2 == 0 and flag == 1:
print('Impossible')
exit()
# 如果奇數次數的字符出現兩個以上,那麼不可能構成回文
if flag > 1:
print('Impossible')
exit()
# 若找到
elif arr[j] == arr[i]:
# 一直將其交換到對應位置
for j in range(j, n-1-i):
arr[j], arr[j+1] = arr[j+1], arr[j]
# 記錄交換次數
count += 1
break
print(count)
題目描述
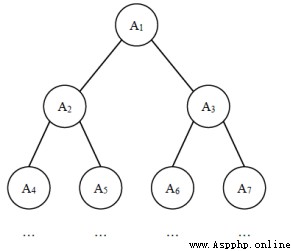
給定一棵包含 N 個節點的完全二叉樹,樹上每個節點都有一個權值,按從上到下、從左到右的順序依次是 A1, A2, · · · AN,如下圖所示:
現在小明要把相同深度的節點的權值加在一起,他想知道哪個深度的節點權值之和最大?如果有多個深度的權值和同為最大,請你輸出其中最小的深度。
注:根的深度是 1。
輸入描述
第一行包含一個整數 N。
第二行包含 N 個整數 A1, A2, · · · AN 。
輸出描述
輸出一個整數代表答案。
輸入樣例
7
1 6 5 4 3 2 1
輸出樣例
2
對於所有評測用例, 1 ≤ N ≤ 100000, −100000 ≤ Ai ≤ 100000。
n = int(input())
data = list(map(int, input().split()))
# 二叉樹深度
deep = 1
# 用於記錄權值最大的深度
max_deep = deep
# 記錄最大權重
max_sum = 0
# 深度為deep的完全二叉樹節點個數為(2^n)-1
while 2 ** deep - 1 <= n:
# 當前深度的節點個數 = 當前深度完全二叉樹的總個數-上層深度完全二叉樹的總個數
data_sum = sum(data[2 ** (deep - 1) - 1: 2 ** deep - 1])
# 記錄最大權重所在深度
if max_sum < data_sum:
max_sum = data_sum
max_deep = deep
deep += 1
# 輸出最大權重所在深度
print(max_deep)
題目描述
小明要組織一台晚會,總共准備了 n 個節目。然後晚會的時間有限,他只能最終選擇其中的 m 個節目。
這 n個節目是按照小明設想的順序給定的,順序不能改變。
小明發現,觀眾對於晚會的喜歡程度與前幾個節目的好看程度有非常大的關系,他希望選出的第一個節目盡可能好看,在此前提下希望第二個節目盡可能好看,依次類推。
小明給每個節目定義了一個好看值,請你幫助小明選擇出 m 個節目,滿足他的要求。
輸入描述
輸入的第一行包含兩個整數 n, m ,表示節目的數量和要選擇的數量。
第二行包含 n 個整數,依次為每個節目的好看值。
輸出描述
輸出一行包含 m 個整數,為選出的節目的好看值。
輸入樣例
5 3
3 1 2 5 4
輸出樣例
3 5 4
樣例說明
選擇了第1, 4, 5個節目。
對於 30% 的評測用例,1 <= n <= 20;
對於 60% 的評測用例,1 <= n <= 100;
對於所有評測用例,1 <= n<= 100000,0 <= 節目的好看值 <= 100000。
n, m = map(int, input().split())
tvlist = list(map(int, input().split()))
# 選最大
res = []
# 開始索引
index = 0
# 當前個數為0
count = 0
# 直到選滿m個
while count < m:
# 從選出的值對應的索引序號後開始到n - m + count中選
res.append(max(tvlist[index: n - m + count + 1]))
index = tvlist[index: n - m + count + 1].index(res[count]) + index + 1
# 計數
count += 1
# 輸出
print(*res)
# n,m =map(int,input().split())
# tvlist = list(map(int, input().split()))
# maxTv= tvlist.copy()
# maxTv.sort(reverse=True)
# maxTv = maxTv[:m]
# count = 0
# for tv in tvlist:
# if tv in maxTv:
# print(tv, end=' ')
# count += 1
# if count == m:
# break
題目描述
有n(2≤n≤20)塊芯片,有好有壞,已知好芯片比壞芯片多。
每個芯片都能用來測試其他芯片。用好芯片測試其他芯片時,能正確給出被測試芯片是好還是壞。而用壞芯片測試其他芯片時,會隨機給出好或是壞的測試結果(即此結果與被測試芯片實際的好壞無關)。
給出所有芯片的測試結果,問哪些芯片是好芯片。
輸入描述
輸入數據第一行為一個整數n,表示芯片個數。
第二行到第n+1行為n*n的一張表,每行n個數據。表中的每個數據為0或1,在這n行中的第i行第j列(1≤i, j≤n)的數據表示用第i塊芯片測試第j塊芯片時得到的測試結果,1表示好,0表示壞,i=j時一律為1(並不表示該芯片對本身的測試結果。芯片不能對本身進行測試)。
輸出描述
按從小到大的順序輸出所有好芯片的編號
輸入樣例
3
1 0 1
0 1 0
1 0 1
輸出樣例
1 3
n = int(input())
arr = [[] for _ in range(n)]
for i in range(n):
arr_ = input().split()
for j in range(n):
arr[i].append(int(arr_[j]))
# 既然好芯片比壞芯片多,那麼我們只需記錄每一列0的個數就行了,若個數超過n/2,則此芯片為壞芯片
for j in range(n):
count = 0
for i in range(n):
if arr[i][j] == 0:
count += 1
if count > n / 2:
continue
print(j+1, end=' ')
題目描述
為了吸引更多的顧客,某商場決定推行有獎抽彩活動。“本商場每日將產生一名幸運顧客,凡購買30元以上商品者均有機會獲得本商場提供的一份精美禮品。”該商場的幸運顧客產生方式十分奇特:每位顧客可至抽獎台抽取一個幸運號碼,該商場在抽獎活動推出的第i天將從所有顧客中(包括不在本日購物滿30元者)挑出幸運號第i小的顧客作為當日的幸運顧客。該商場的商品本就價廉物美,自從有獎活動推出後,顧客更是絡繹不絕,因此急需你編寫一個程序,為他解決幸運顧客的產生問題。
輸入描述
第1行一個整數N,表示命令數。
第2~N+1行,每行一個數,表示命令。如果x>=0,表示有一顧客抽取了號碼x;如果x=-1,表示傍晚抽取該日的幸運號碼。
輸出描述
對應各命令-1輸出幸運號碼;每行一個號碼。(兩個相同的幸運號看作兩個號碼)
輸入樣例
6
3
4
-1
-1
3
-1
輸出樣例
3
4
4
共10組數據。
對100%的數據,N= 1 0 6 10^6 106所有命令為-1或int范圍內的非負數,前i的命令中-1的數量不超過[i/2](向下取整)。
n = int(input())
# 存放號碼
consumer = []
# 統計-1的個數
ans = 0
# 存放結果
res = []
for i in range(n):
data = int(input())
if data != -1:
consumer.append(data)
# 排序
consumer.sort()
else:
res.append(consumer[ans])
ans += 1
print(res)
題目描述
小明想知道,滿足以下條件的正整數序列的數量:
第一項為n;
第二項不超過n;
從第三項開始,每一項小於前兩項的差的絕對值。
請計算,對於給定的n,有多少種滿足條件的序列。
輸入描述
輸入一行包含一個整數n。
輸出描述
輸出一個整數,表示答案。答案可能很大,請輸出答案除以10000的余數。
輸入樣例
4
輸出樣例
7
樣例說明
以下是滿足條件的序列:
4 1
4 1 1
4 1 2
4 2
4 2 1
4 3
4 4
對於 20% 的評測用例,1 <= n <= 5;
對於 50% 的評測用例,1 <= n <= 10;
對於 80% 的評測用例,1 <= n <= 100;
對於所有評測用例,1 <= n <= 1000。
# 用於派生下一項
def next_item(res):
new_res = []
# 當前序列最後兩項的絕對差
ab = abs(res[-2] - res[-1])
# 若能派生出下一項
for i in range(1, ab):
# 則新序列為當前序列加下一項
new_res.append(res + [i])
return new_res
# 第一項
n = int(input())
# 用於記錄序列
res_list = []
# 用於記錄可派生項
accept_list = []
# 用於循環
temp_list = []
# 計數
count = 0
# 第二項
for i in range(1, n+1):
# 記錄此時的第一項和第二項
res_list.append([n, i])
# 記錄此時的序列用於循環
temp_list += res_list
while len(temp_list) > 0:
for res in temp_list: # 判斷temp_list的每一項
next_ = next_item(res) # 判斷這項可以再派生下一項
# 添加記錄到accept_list
accept_list += next_
temp_list.clear() # 清空
res_list = accept_list + res_list # 把新派生出的項加到res_list,res_list此時已包含兩項加新派生的項
temp_list += accept_list # 新派生的項加到temp_list進行下次循環用
accept_list.clear() # 清空
# 輸出結果
for i in res_list:
print(i, end=' ')
print()
print(len(res_list) % 10000)
題目描述
小藍有一個數字矩陣,裡面只包含數字 0 和 2。小藍很喜歡 2020,他想找到這個數字矩陣中有多少個 2020 。
小藍只關注三種構成 2020 的方式:
• 同一行裡面連續四個字符從左到右構成 2020。
• 同一列裡面連續四個字符從上到下構成 2020。
• 在一條從左上到右下的斜線上連續四個字符,從左上到右下構成 2020。例如,對於下面的矩陣:
220000
000000
002202
000000
000022
002020
一共有 5 個 2020。其中 1 個是在同一行裡的,1 個是在同一列裡的,3 個是斜線上的。小藍的矩陣比上面的矩陣要大,由於太大了,他只好將這個矩陣放在了一個文件裡面,在試題目錄下有一個文件
2020.txt,裡面給出了小藍的矩陣。請幫助小藍確定在他的矩陣中有多少個 2020。
2020.txt:
220000
000000
002202
000000
000022
002020
nums, result=[], 0
with open("2020.txt") as f:
for line in f.readlines():
nums.append(list(line.strip()))
move=[[0, 1],[1, 0],[1, 1]]
for x in range(len(nums)):
for y in range(len(nums[0])):
for xx, yy in move:
num = str(nums[x][y])
for m in range(1, 4):
x_, y_= x + xx * m, y + yy * m
if 0 <= x_ < len(nums) and 0 <= y_ <len(nums[0]):
num += str(nums[x_][y_])
else:
break
if num == '2020':
result += 1
print(result)
題目描述
楊輝三角形又稱Pascal三角形,它的一個重要性質是:三角形中的每個數字等於它兩肩上的數字相加。
下面給出了楊輝三角形的前4行:
1
1 1
1 2 1
1 3 3 1
給出n,輸出它的前n行。
輸入描述
輸入包含一個數n。
輸出描述
輸出楊輝三角形的前n行。每一行從這一行的第一個數開始依次輸出,中間使用一個空格分隔。請不要在前面輸出多余的空格。
輸入樣例
4
輸出樣例
1
1 1
1 2 1
1 3 3 1
1 <= n <= 34。
n = int(input())
triangle_yang = [[0 for j in range(i+1)] for i in range(n)]
triangle_yang[0][0] = 1
for i in range(1, n):
# 每一行的第一列和最後一列為1
triangle_yang[i][0], triangle_yang[i][-1] = 1, 1
# 其余為兩肩數值之和
for j in range(1, i):
triangle_yang[i][j] = triangle_yang[i-1][j-1] + triangle_yang[i-1][j]
for i in range(n): # 輸出楊輝三角
for j in range(i+1):
print(triangle_yang[i][j], end=' ')
print()
題目描述
一棵包含有2019個結點的二叉樹,最多包含多少個葉結點?
# n為深度
n = 1
while 2 ** n - 1 < 2019:
n += 1
# 2019節點多於深度為n-1的二叉樹,小於深度為n的二叉樹,通過普通的數學計算,可得最後層的葉子節點數
print(2 ** n - 1 - (2 ** (n - 1) - 1) - (2 ** n - 1 - 2019) // 2)
題目描述
小明對類似於 hello 這種單詞非常感興趣,這種單詞可以正好分為四段,第一段由一個或多個輔音字母組成,第二段由一個或多個元音字母組成,第三段由一個或多個輔音字母組成,第四段由一個或多個元音字母組成。
給定一個單詞,請判斷這個單詞是否也是這種單詞,如果是請輸出yes,否則請輸出no。
元音字母包括 a, e, i, o, u,共五個,其他均為輔音字母。
輸入描述
輸入一行,包含一個單詞,單詞中只包含小寫英文字母。
輸出描述
輸出答案,或者為yes,或者為no。
輸入樣例
lanqiao
輸出樣例
yes
輸入樣例
world
輸出樣例
no
str1 = input()
alpha = ['a', 'e', 'i', 'o', 'u']
count = 0
flag = True
for i in range(len(str1)):
if str1[i] in alpha and str1[i-1] not in alpha:
count += 1
if count == 2 and str1[i] not in alpha:
flag = False
if(flag and count == 2):
print('yes')
else:
print('no')
題目描述
生理衛生老師在課堂上娓娓道來:
你能看見你未來的樣子嗎?顯然不能。但你能預測自己成年後的身高,有公式:
男孩成人後身高=(父親身高+母親身高)/ 2 * 1.08
女孩成人後身高=(父親身高*0.923+母親身高)/ 2
數學老師聽見了,回頭說:這是大樣本統計擬合公式,准確性不錯。
生物老師聽見了,回頭說:結果不是絕對的,影響身高的因素很多,比如營養、疾病、體育鍛煉、睡眠、情緒、環境因素等。
老師們齊回頭,看見同學們都正在預測自己的身高。
毛老師見此情形,推推眼鏡說:何必手算,編程又快又簡單…
約定:
身高的單位用米表示,所以自然是會有小數的。
男性用整數1表示,女性用整數0表示。
預測的身高保留三位小數
輸入描述
用空格分開的三個數,整數 小數 小數
分別表示:性別 父親身高 母親身高
輸出描述
一個小數,表示根據上述表示預測的身高(保留三位小數)
輸入樣例
1 1.91 1.70
輸出樣例
1.949
輸入樣例
0 1.00 2.077
輸出樣例
1.500
父母身高范圍(0,3]
時間限制1.0秒
sex, dad, mom = map(float, input().split())
if int(sex) == 0:
height = (dad * 0.923 + mom) / 2
else:
height = (dad + mom) / 2*1.08
print('%.3f' % height)
題目描述
1200000有多少個約數(只計算正約數)。
count = 0
# 根據對稱,只要到根號即可
for i in range(1, int(float(1200000)**0.5) + 1):
if 1200000 % i == 0:
count += 2
print(count)
題目描述
小明有一塊空地,他將這塊空地劃分為 n 行 m 列的小塊,每行和每列的長度都為 1。
小明選了其中的一些小塊空地,種上了草,其他小塊仍然保持是空地。
這些草長得很快,每個月,草都會向外長出一些,如果一個小塊種了草,則它將向自己的上、下、左、右四小塊空地擴展,這四小塊空地都將變為有草的小塊。
請告訴小明,k 個月後空地上哪些地方有草。
輸入描述
輸入的第一行包含兩個整數 n, m。
接下來 n 行,每行包含 m 個字母,表示初始的空地狀態,字母之間沒有空格。如果為小數點,表示為空地,如果字母為 g,表示種了草。
接下來包含一個整數 k。
輸出描述
輸出 n 行,每行包含 m 個字母,表示 k 個月後空地的狀態。如果為小數點,表示為空地,如果字母為 g,表示長了草。
輸入樣例
4 5
.g…
…
…g…
…
2
輸出樣例
gggg.
gggg.
ggggg
.ggg.
def grow(x, y):
for offset in R:
x1 = x + offset[0]
y1 = y + offset[1]
if y1 >= 0 and y1 < m and x1 >= 0 and x1 < n and area[x1][y1] == '.':
area[x1][y1] = 'g'
flag[x1][y1] = 1
n, m = map(int, input().split())
area = [list(input()) for _ in range(n)]
k = int(input())
# 上下左右
R = [(-1, 0), (0, -1), (1, 0), (0, 1)]
# 長草月數
for month in range(k):
# 記錄已經生長過的草位置
flag = [[0 for _ in range(m)] for _ in range(n)]
for i in range(n):
for j in range(m):
if area[i][j] == 'g' and flag[i][j] == 0:
flag[i][j] = 1
grow(i, j)
#輸出第k月長草情況
for row in area:
print(''.join(row))
題目描述
輸入兩個整數a和b,輸出這兩個整數的和。a和b都不超過100位。
輸入描述
輸入包括兩行,第一行為一個非負整數a,第二行為一個非負整數b。兩個整數都不超過100位,兩數的最高位都不是0。
輸出描述
輸出一行,表示a + b的值。
輸入樣例
20100122201001221234567890
2010012220100122
輸出樣例
20100122203011233454668012
arr1 = input()
arr2 = input()
# 比較兩者長度,進行補0
length = len(arr1) - len(arr2)
if length > 0:
arr2 = '0' * length + arr2
else:
arr1 = '0' * (-length) + arr1
# 存放結果
result = [0 for i in range(len(arr1)+1)]
# 進位
k = 0
for i in range(len(arr1)):
# 從個位開始加,同時加上進位
sum = k + int(arr1[len(arr1)-i-1]) + int(arr2[len(arr1)-i-1])
# 從個位開始存放結果
result[len(arr1) - i] = sum % 10
# 設置進位
k = sum // 10
# 最高位進位
if k != 0:
result[0] = k
# 輸出結果
for i in range(len(arr1)+1):
# 排除最高位為0的情況
if result[0] == 0 and i == 0:
continue
print(result[i], end='')
題目描述
在怪物獵人這一款游戲中,玩家可以通過給裝備鑲嵌不同的裝飾珠來獲取 相應的技能,以提升自己的戰斗能力。
已知獵人身上一共有 6 件裝備,每件裝備可能有若干個裝飾孔,每個裝飾孔有各自的等級,可以鑲嵌一顆小於等於自身等級的裝飾珠 (也可以選擇不鑲嵌)。
裝飾珠有 M 種,編號 1 至 M,分別對應 M 種技能,第 i 種裝飾珠的等級為 L i L_i Li,只能鑲嵌在等級大於等於 L i L_i Li 的裝飾孔中。
對第 i 種技能來說,當裝備相應技能的裝飾珠數量達到 K i K_i Ki個時,會產生 W i ( K i ) W_i(K_i) Wi(Ki)的價值,鑲嵌同類技能的數量越多,產生的價值越大,即 W i ( K i − 1 ) < W i ( K i ) W_i(K_{i-1})<W_i(K_i) Wi(Ki−1)<Wi(Ki)。但每個技能都有上限 P i P_i Pi(1≤ P i P_i Pi≤7),當裝備的珠子數量超過 P i P_i Pi時,只會產生 W i ( P i ) W_i(P_i) Wi(Pi)的價值。對於給定的裝備和裝飾珠數據,求解如何鑲嵌裝飾珠,使得 6 件裝備能得到的總價值達到最大。
輸入描述
輸入的第 1 至 6 行,包含 6 件裝備的描述。其中第i行的第一個整數 N i N_i Ni表示第i件裝備的裝飾孔數量。後面緊接著 N i N_i Ni個整數,分別表示該裝備上每個裝飾孔的等級L(1≤ L ≤4)。
第 7 行包含一個正整數 M,表示裝飾珠 (技能) 種類數量。
第 8 至 M + 7 行,每行描述一種裝飾珠 (技能) 的情況。每行的前兩個整數 L j L_j Lj(1≤ L j L_j Lj ≤4)和 P j P_j Pj(1≤ P j P_j Pj ≤7)分別表示第 j 種裝飾珠的等級和上限。接下來 P j P_j Pj個整數,其中第 k 個數表示裝備該中裝飾珠數量為 k 時的價值 W j ( k ) W_j(k) Wj(k)。
其中1 ≤ N i N_i Ni ≤ 50,1 ≤ M ≤ 1 0 4 10^4 104,1 ≤ W j ( k ) W_j(k) Wj(k) ≤ 1 0 4 10^4 104。
輸出描述
輸出一行包含一個整數,表示能夠得到的最大價值。
輸入樣例
1 1
2 1 2
1 1
2 2 2
1 1
1 3
3
1 5 1 2 3 5 8
2 4 2 4 8 15
3 2 5 10
輸出樣例
20
樣例說明
按照如下方式鑲嵌珠子得到最大價值 20,括號內表示鑲嵌的裝飾珠的種類編號:
1: (1)
2: (1) (2)
3: (1)
4: (2) (2)
5: (1)
6: (2)4 顆技能 1 裝飾珠,4 顆技能 2 裝飾珠 W 1 ( 4 ) + W 2 ( 4 ) = 5 + 15 = 20 W_1(4) + W_2(4) = 5 + 15 = 20 W1(4)+W2(4)=5+15=20。
# curItem表示當前裝備索引
# curHole表示當前孔洞索引
# holeNum表示當前裝備孔洞總數量
# skillNums記錄孔洞裝備情況
def holeValue(skillNums, curItem, curHole, holeNum, phole):
# 遍歷完所有孔,記錄數據退出
if curHole == holeNum:
phole.append(skillNums)
return
# 當前孔位的裝備容量
maxLimit = items[curItem][curHole+1]
for j in range(n):
# 如果技能等級小等容量,則可以裝備
if skills[j][0] <= maxLimit:
tmp = []
tmp += skillNums
tmp[j] += 1
# 記錄當前孔裝備技能
holeValue(tmp, curItem, curHole+1, holeNum, phole)
# 搜索所有的可能價值
# skillNums用於封裝各個技能的數量
# cur代表當前是第幾號裝備
def allValue(skillNums, cur):
# 遍歷完所有裝備,記錄數據退出
if cur == 6:
values.append(skillNums)
return
# 用於記錄每個孔位的可能裝備情況
phole = []
# 所需該裝備的所有可能裝備情況
holeValue(skillNums, cur, 0, items[cur][0], phole)
# 進行下一個裝備的搜索
for arr in phole:
allValue(arr, cur+1)
# 裝備
items = [list(map(int, input().split())) for _ in range(6)]
n = int(input())
# 技能
skills = [list(map(int, input().split())) for _ in range(n)]
# 用於記錄所有的可能價值
values = []
# 搜尋所有可能
allValue([0]*n, 0)
# 存放最大價值
maxValue = 0
# 遍歷每種可能
for value in values:
tmp = 0
# 遍歷每個技能的可能存放數量
for i in range(len(value)):
# 求取價值
index = min(value[i], skills[i][1])
if index > 0:
tmp += skills[i][index+1]
if tmp > maxValue:
maxValue = tmp
print(maxValue)
題目描述
給出一個字符串和多行文字,在這些文字中找到字符串出現的那些行。你的程序還需支持大小寫敏感選項:當選項打開時,表示同一個字母的大寫和小寫看作不同的字符;當選項關閉時,表示同一個字母的大寫和小寫看作相同的字符。
輸入描述
輸入的第一行包含一個字符串S,由大小寫英文字母組成。
第二行包含一個數字,表示大小寫敏感的選項,當數字為0時表示大小寫不敏感,當數字為1時表示大小寫敏感。
第三行包含一個整數n,表示給出的文字的行數。
接下來n行,每行包含一個字符串,字符串由大小寫英文字母組成,不含空格和其他字符。
輸出描述
輸出多行,每行包含一個字符串,按出現的順序依次給出那些包含了字符串S的行。
輸入樣例
Hello
1
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello
輸出樣例
HelloWorld
HiHiHelloHiHi
HELLOisNOTHello
樣例說明
在上面的樣例中,第四個字符串雖然也是Hello,但是大小寫不正確。如果將輸入的第二行改為0,則第四個字符串應該輸出。
s = input()
buttom = int(input())
rows = int(input())
arr = [input() for _ in range(rows)]
res = []
if buttom == 1:
for i in arr:
if s in i:
res.append(i)
else:
s = s.lower()
for i in arr:
if s in i.lower():
res.append(i)
for i in range(len(res)):
print(res[i])
題目描述
給定兩個僅由大寫字母或小寫字母組成的字符串(長度介於1到10之間),它們之間的關系是以下4中情況之一:
1:兩個字符串長度不等。比如 Beijing 和 Hebei
2:兩個字符串不僅長度相等,而且相應位置上的字符完全一致(區分大小寫),比如 Beijing 和 Beijing
3:兩個字符串長度相等,相應位置上的字符僅在不區分大小寫的前提下才能達到完全一致(也就是說,它並不滿足情況2)。比如 beijing 和 BEIjing
4:兩個字符串長度相等,但是即使是不區分大小寫也不能使這兩個字符串一致。比如 Beijing 和 Nanjing
編程判斷輸入的兩個字符串之間的關系屬於這四類中的哪一類,給出所屬的類的編號。
輸入描述
包括兩行,每行都是一個字符串
輸出描述
僅有一個數字,表明這兩個字符串的關系編號
輸入樣例
BEIjing
beiJing
輸出樣例
3
str1 = input()
str2 = input()
if len(str1) != len(str2):
print(1)
else:
if str1 == str2:
print(2)
elif str1.lower() == str2.lower():
print(3)
else:
print(4)
題目描述
給定一個字符串,你需要從第start位開始每隔step位輸出字符串對應位置上的字符。
輸入描述
第一行:一個只包含小寫字母的字符串。
第二行:兩個非負整數start和step,意義見上。
輸出描述
一行,表示對應輸出。
輸入樣例
abcdefg
2 2
輸出樣例
ceg
start從0開始計數。
字符串長度不超過100000。
s = input()
start, step = map(int, input().split())
print(s[start::step])
題目描述
給定兩個字符串,尋找這兩個字串之間的最長公共子序列。
輸入描述
輸入兩行,分別包含一個字符串,僅含有小寫字母。
輸出描述
最長公共子序列的長度。
輸入樣例
abcdgh
aedfhb
輸出樣例
3
樣例說明
最長公共子序列為a,d,h。
字串長度1~1000。
str1 = input()
str2 = input()
# res[i][j]代表長度str1長度為i,str2長度為j時的最長公共子序列的長度
res = [[0 for _ in range(len(str2)+1)] for _ in range(len(str1)+1)]
# 從零開始遞歸
for i in range(len(str1)+1):
for j in range(len(str2)+1):
# 其中一個字符串長度為0時,最長公共子序列的長度為0
if i == 0 or j == 0:
res[i][j] = 0
# 否則若當前長度位置i和j的字符相等,則最長公共子序列的長度更新為i-1和j-1長度時最長公共子序列的長度+1
elif str1[i-1] == str2[j-1]:
res[i][j] = res[i - 1][j - 1] + 1
# 若當前長度位置i和j的字符不相等,則最長公共子序列的長度為最長的(i-1和j長度時的最長公共子序列長度,i和j-1長度時的最長公共子序列長度)
else:
res[i][j] = max(res[i - 1][j], res[i][j - 1])
# 返回最終長度時的最長公共子序列的長度
print(res[-1][-1])
題目描述
小袁非常喜歡滑雪, 因為滑雪很刺激。為了獲得速度,滑的區域必須向下傾斜,而且當你滑到坡底,你不得不再次走上坡或者等待升降機來載你。 小袁想知道在某個區域中最長的一個滑坡。區域由一個二維數組給出。數組的每個數字代表點的高度。如下:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-8FEEdpCY-1654839635672)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/image-20220302190226582.png)]
一個人可以從某個點滑向上下左右相鄰四個點之一,當且僅當高度減小。在上面的例子中,一條可滑行的滑坡為24-17-16-1。當然25-24-23-…-3-2-1更長。事實上,這是最長的一條。
你的任務就是找到最長的一條滑坡,並且將滑坡的長度輸出。 滑坡的長度定義為經過點的個數,例如滑坡24-17-16-1的長度是4。
輸入描述
輸入的第一行表示區域的行數R和列數C(1<=R, C<=10)。下面是R行,每行有C個整數,依次是每個點的高度h(0<= h <=10000)。
輸出描述
只有一行,為一個整數,即最長區域的長度。
輸入樣例
5 5
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
輸出樣例
25
#遞歸搜索, 求該位置出發的最長路徑
def dfs(x, y):
# 初始化為1
maxHeight = 1
# 該位置周邊的四個點
offset = [[-1, 0], [1, 0], [0, -1], [0, 1]]
for i in offset:
# 下一個搜索點的橫坐標
tx = x + i[0]
# 下一個搜索點的縱坐標
ty = y + i[1]
# 若超出邊界,跳過
if tx < 0 or tx > R - 1 or ty < 0 or ty > C - 1:
continue
# 若不滿足高度差,跳過
if arr[tx][ty] >= arr[x][y]:
continue
# 當前位置出發的最長路徑只有兩種情況
# 1.找不到滿足條件的搜索點為它自身 2.下一個搜索點的最長路徑+1
maxHeight = max(maxHeight, dfs(tx, ty) + 1)
return maxHeight
#輸入
R, C = map(int, input().split())
arr = [list(map(int, input().split())) for _ in range(R)]
# 存放最長路徑的結果
res = 0
for x in range(R):
for y in range(C):
res = max(res, dfs(x, y))
print(res)
題目描述
設x(i), y(i), z(i)表示單個字符,則X={x(1)x(2)……x(m)},Y={y(1)y(2)……y(n)},Z={z(1)z(2)……z(k)},我們稱其為字符序列,其中m,n和k分別是字符序列X,Y,Z的長度,括號()中的數字被稱作字符序列的下標。
如果存在一個嚴格遞增而且長度大於0的下標序列{i1,i2……ik},使得對所有的j=1,2,……k,有x(ij)=z(j),那麼我們稱Z是X的字符子序列。而且,如果Z既是X的字符子序列又是Y的字符子序列,那麼我們稱Z為X和Y的公共字符序列。
在我們今天的問題中,我們希望計算兩個給定字符序列X和Y的最大長度的公共字符序列,這裡我們只要求輸出這個最大長度公共子序列對應的長度值。
舉例來說,字符序列X=abcd,Y=acde,那麼它們的最大長度為3,相應的公共字符序列為acd。
輸入描述
輸入一行,用空格隔開的兩個字符串
輸出描述
輸出這兩個字符序列對應的最大長度公共字符序列的長度值
輸入樣例
aAbB aabb
輸出樣例
2
a, b = input().split()
arr = [[0 for _ in range(len(b)+1)] for _ in range(len(a)+1)]
for i in range(len(a)+1):
for j in range(len(b)+1):
if i == 0 or j == 0:
arr[i][j] = 0
elif a[i-1] == b[j-1]:
arr[i][j] = arr[i-1][j-1] + 1
else:
arr[i][j] = max(arr[i][j-1], arr[i-1][j])
print(arr[-1][-1])
 Python office automation practice 15 | Python docx Library: the perfect combination of Python and word_ Realize one click batch search and replacement of multiple word documents
Python office automation practice 15 | Python docx Library: the perfect combination of Python and word_ Realize one click batch search and replacement of multiple word documents
One 、 Introduction to the topi
 Python introductory tutorial (very detailed), from zero basic entry to proficient, reading this article is enough
Python introductory tutorial (very detailed), from zero basic entry to proficient, reading this article is enough
前言本文羅列了了python零基礎入門到精通的詳細教程,內容