當我們編寫好 Python 代碼後,便把它交給了 Python 解釋器去執行,解釋器就如同代碼背後的管道一般,對代碼進行搬運和處理,直至輸出預期內的結果。那麼代碼在解釋器內部的運行原理是怎樣的?這一節我們便從 Python 解釋器、字節碼、Python 虛擬機、Python的不同實現等幾個方面出發, 對 Python 的內部運行機制進行一定的剖析。
對於計算機而言,它只能理解機器語言,但對於我們通常所使用的編程語言而言,一般都屬於高級語言,比如 Python、Java、C++,這些高級語言都要轉換成機器語言才能被計算機執行。籠統的說,高級語言被轉換為機器語言的方式可分為編譯和解釋,所以對於高級語言來說,從執行的角度可被分為編譯型和解釋型。
對於 Python 而言,它雖然沒有顯式的編譯過程,但它和傳統的解釋型語言仍具有一些差別。在 Python 內部仍存在編譯過程,在運行 Python 程序時,源代碼首先會被自動編譯為字節碼而並非直接被解釋執行,但這種字節碼並不是機器對應的二進制碼,在運行時,字節碼會在 Python 虛擬機內被進一步解釋執行。
作為一種解釋型語言來講,Python 的執行效率是相對較高的,但相對於編譯型語言,它的執行效率卻是比較低的。如果語言的執行效率對你所要完成的任務很關鍵,那麼在 Python 中的第一個解決方案是選擇通過以 C 或 C++ 編寫第三方庫來對你的 Python 代碼進行擴展,因為 Python 的一個優勢便是可以很好的和 C/C++ 進行結合,將核心的計算任務放在這些語言中完成,以提高程序的執行效率。另一個解決方案是使用支持即時編譯 ( JIT,just-in-time ) 的解釋器來替換 CPython,例如 PyPy,它優化了代碼生成和 Python 程序的執行速度,這一點我們在下面 Python 實現中也會提到。
最後,在這一點中不得不說的是,一些沒有深入了解和使用 Python 的用戶僅僅將 Python 作為一種簡單的腳本語言,並帶有一些 ”偏見“ 的認為 Python 不適用於構建大型項目,但事實(尤其是 Python 在國內外眾多頂尖的軟件團隊中的大量應用)已經充分的證明 Python 的能力其實遠超過我們的想象。隨著Typing hint 的到來,Python 也漸漸地開始能夠構建一些大型的應用,性能也還可以。
我們提到了 Python 代碼會被編譯為字節碼再進行其他處理,這些編譯和處理的過程都是在 Python 解釋器中進行的。Python 解釋器是運行 Python 代碼的程序,無論在 Linux 或 Windows 平台,我們想要運行 Python 代碼,就必須先安裝 Python 解釋器。如下圖所示,Python 解釋器是在 Python 代碼和計算機硬件之間的處理層。

在一些 Python 腳本中,我們經常在首行看到 #!/usr/bin/env python,這便是用來指示執行該文件時所使用的解釋器。在 Unix 中,一個被解釋執行的文件可以使用 #! 在第一行指示要使用的解釋器。/usr/bin/env 將會在 $PATH 環境變量中查找要使用的解釋器,這種寫法相對靈活,與之對應的是使用 #!/usr/bin/python 這樣的硬編碼寫法,其靈活性便相對較差一些。
注意,以上的兩種寫法都是針對 $./***.py 這種普通程序或者 bash 腳本的執行方式,如果使用 $python ***.py 執行,系統將根據我們的輸入調用對應解釋器,不需要在腳本中指定解釋器。
這裡我們對代碼在 Python 解釋器中的處理過程進一步細化。
for 循環和一些用於匹配大量操作碼的 switch 語句。
實際上,在這個過程中 Python 解釋器遠遠要比上述的流程復雜,其中可能會包含著特定於某些平台的優化、虛擬機優化(比如操作碼的預測)、字節碼執行前的初始化等等。需要注意的是,我們這裡的描述有可能會隨著 Python 版本更迭產生變化。另外,這裡我們對於這些處理過程的介紹均基於 Python 的官方實現 CPython 解釋器(官方 Python 解釋器是使用 C 進行編寫的,稱為 CPython 解釋器,關於 Python 的實現,我們在下面有對應的講解)。
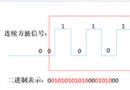
Python 源代碼在編譯後生成的字節碼是一種不依賴於平台的中間格式(“中間語言”),是 Python 代碼在 CPython 解釋器內部的表示形式。執行編譯後的字節碼不僅省去了將源碼編譯為字節碼的過程,而且相比於直接使用 Python 源代碼執行來說,字節碼在執行效率上有較大的提升。我們在上面已經提到,在虛擬機中會執行字節碼對應的機器碼,但需要注意的是,字節碼不能完全保證在不同的 Python 虛擬機上使用,並且也不能完全保證在不同的 Python 版本之間兼容。
字節碼被存儲在 .pyc 為後綴的文件中。執行字節碼相比於執行源代碼而言,提升了執行速度,而存儲字節碼則可以提升啟動速度,避免了在每次啟動運行時都要進行將源代碼編譯為字節碼的過程。如果使用相同的 Python 版本,並且源代碼並沒有發生改變的情況下,Python 將會使用已保存的字節碼文件,從而在啟動時省去編譯的過程。
作為擴展,我們在這裡簡單的了解 Python 生態中的一些文件後綴所表示的含義:.py 表示源代碼文件;.pyc 表示編譯後的字節碼文件;pyo 是 Python 3.5 之前使用的一種文件格式,通過 -O 或 -OO 標志調用解釋器,對生成字節碼進行優化(目前主要是刪除 assert 語句等)並存儲在 pyo 文件中,在 Python 3.5 之後,去除了 pyo 文件格式,使用 pyc 文件來同時表示未優化和優化的字節碼(更多細節可以參考 PEP 488 );pyi 表示 “存根” 文件(Stub file),包含對模塊公共接口的描述, 不包含具體的實現(更多細節可以參考 PEP 484 );pyd 表示作為 Windows DLL 生成的 Python 文件(更多細節可參考 *.pyd 文件和DLL文件相同嗎?);pyx 表示由 Cython(一種為 Python 編寫 C 擴展的語言)編寫的源代碼文件(更多細節可參考 Cython programming language )。
在 Python 的標准庫中,有兩個模塊可以幫助我們生成字節碼文件,分別為 py_compile 和 compileall ,前者主要提供了從單個源文件中編譯生成字節碼文件的相關函數,後者主要提供了從目錄中編譯源文件的相關函數,這兩個模塊可以用於包或模塊安裝時創建字節碼文件,特別是在某些用戶可能無權在包含源代碼的目錄中寫入字節碼文件的情況下。
下面的代碼 PyCharm 的 Python console 中執行,我們重新將 PyCharm 的 Python 版本切換到 Python 3.7,並將之前生成的包括 __pycache__ 目錄在內的所有字節碼文件刪除。
>>> py_compile.compile('./003_concatenator.py')
'./__pycache__/003_concatenator.cpython-37.pyc'
dis 模塊分析字節碼我們可以通過如下的方式去查看所示函數對象對應的字節碼,函數的 __code__ 屬性表示編譯後的函數體的代碼對象 ,co_code 表示原始編譯字節碼 (更多細節可參考數據模型中代碼對象部分)。
>>> def function_one():
... print("hello world")
...
>>> function_one.__code__.co_code
b't\x00d\x01\x83\x01\x01\x00d\x00S\x00'
對於這些字節碼來說,我們無法理解它們,這時可以借助 Python 標准庫中的 dis 模塊( Disassembler for Python bytecode )來進行字節碼反匯編,它的主要作用是將 CPython 字節碼轉換為一種人類可讀的形式來進行字節碼分析。需要注意的是,字節碼作為 CPython 解釋器的實現細節可能會在不同的 Python 版本之間發生變動。我們可以使用 dis.dis(x) 來反匯編 x 對象(也可以使用 dis.disco(x.__code__)),其中 x 可以表示模塊、類、方法、函數、生成器、異步生成器、協程等。
具體的看下面的示例的輸出結果中,第一列中的 2 表示源代碼中的行號,第二列的數字表示指令的地址( Python 3.6 之後每條指令使用 2 個字節,在這之前的字節數會根據指令的不同會發生變化),第三列則表示人類可讀的操作碼名稱 opname (與之對應的 opcode 則表示操作的數字代碼),比如 LOAD_GLOBAL 表示將 名稱為 co_names[namei] 的全局對象推入棧頂,其中 co_names 表示包含字節碼所使用的局部變量名稱的元組,namei 則是 name 在代碼對象的 co_names 屬性中的索引。對於這部分感興趣的同學可以結合 dis 、數據模型中代碼對象部分、inspect 等模塊一起來更詳細的理解相關邏輯的具體含義。剩下的第四列和第五列則分別表示操作參數和參數解釋 。
dis模塊 的每段的含義如下
源碼行號 | 指令在函數中的偏移 | 指令符號 | 指令參數 | 實際參數值
>>> import dis
>>> dis.dis(function_one)
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello world')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
>>> dis.opname
['<0>', 'POP_TOP', 'ROT_TWO', ..., '<254>', '<255>']
>>> dis.opmap
{
'POP_TOP': 1, 'ROT_TWO': 2, 'ROT_THREE': 3, ..., 'CALL_FINALLY': 162, 'POP_FINALLY': 163}
>>> dis.opmap['LOAD_GLOBAL']
116
也可以以命令行方式使用 dis 模塊。除此之外,還可以使用 dis 模塊中的其他的分析函數,在這裡便不再贅述。
func.py
# -*- coding: utf-8 -*-
""" @Time : 2022/7/30 16:23 @Author : Frank @File : func.py """
def function_one():
print("hello world")
使用 dis 模塊 來查看 字節碼
$ python -m dis func.py
(venv) * python -m dis func.py
6 0 LOAD_CONST 0 ('\[email protected] : 2022/7/30 16:23\[email protected] : Frank\[email protected] : func.py\n')
2 STORE_NAME 0 (__doc__)
9 4 LOAD_CONST 1 (<code object function_one at 0x7f94e73146f0, file "func.py", line 9>)
6 LOAD_CONST 2 ('function_one')
8 MAKE_FUNCTION 0
10 STORE_NAME 1 (function_one)
12 LOAD_CONST 3 (None)
14 RETURN_VALUE
Disassembly of <code object function_one at 0x7f94e73146f0, file "func.py", line 9>:
10 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('hello world')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
Python 的實現是指使用何種方式、何種語言來實現 Python,在不同的實現下,同樣的代碼所實現的功能通常是相同的,我們在此前的講解都是基於 Python 的官方標准實現 CPython 來完成的。目前 Python 的實現方式除了 CPython 外,還有 PyPy、Jython、IronPython、Stackless Python 等。
CPython 使用 C 語言編寫而成,是 Python 語言的參考實現。在語言特性的完整性與及時性、運行穩定性多個方面,它是最優的選擇。同時,在庫支持、C 和 C ++ 擴展等方面,CPython 目前也具有非常明顯的優勢。但 CPython 目前仍存在兩個較為顯著的問題,一方面是全局解釋器鎖 GIL 對多線程執行的限制;另一方面,CPython 未支持即時編譯 JIT(一種運行時將部分字節碼整體編譯為機器碼的機制),使得在代碼的執行效率上相對較低。
PyPy 作為 Python 的另一個最重要的實現,采用 Python 本身實現。PyPy 吸納了 Psyco 即時編譯器的基礎,它最重要的特點便是支持即時編譯 JIT ,在運行時將部分字節碼轉換為機器碼,使得在大部分情況下 Python 程序的運行速度得到了顯著提升。PyPy 在內存占用上相比於 CPython 也具有一些優勢,同時吸收了 Stackless Python 的設計思想,並且未使用引用計數進行垃圾回收。
但與此同時,在利用 C 語言編寫而成的 Python 擴展以及相關新特性的支持上,PyPy 還有很多欠缺的地方,但它作為 Python 的一個重要方向,仍值得 Python 開發者持續關注。另外,截止目前 PyPy 並未去除 GIL 。
Jython 是 Python 的 Java 實現,可以在 Python 代碼中使用 Java 類,其將代碼編譯為 Java 字節碼。Jython 的主要目的是在 Python 代碼中無縫的使用 Java 類,從而可以在 Java 系統中使用 Python 來腳本化 Java 代碼。
IronPython 最初由微軟開發,和 Jython 的設計思想類似,其將 Python 與 Windows 上的 .Net 框架相繼承。值得一提的是,在 Jython、IronPython 中均沒有全局解釋器鎖 GIL,因此多線程可以有效的利用多核,它們的主要缺點是目前無法利用眾多 C 語言編寫而成的 Python 擴展,並且和 CPython 相比,目前在效率和穩定性上並無優勢。
Stackless Python 是在 CPython 基礎上針對並發而進行增強的 Python 實現。見名思義,Stackless Python 不依賴 C 語言調用棧進行狀態保存。其最顯著的特點是使用輕量級的微線程代替依賴內核進行上下文切換與調度的原生線程。由 Stackless Python 衍生的 greenlet 在眾多框架中得到了廣泛的應用。同時,Stackless Python 的思想也促進了協程生態的產生和發展。
Python 這門語言是一種解釋性語言,但是也需要一些中間結果(字節碼),python的解釋器才能翻譯。 字節碼 會被送到 PVM (Python Virtual Machine)中進行處理的。 當然也不是每次都需要編譯生成 字節碼文件 ,只有在Python代碼改變的時候才會重新進行編譯,生成一個 __pycache__ 的目錄, 裡面存放的就是 字節碼文件啦. 現在最主流的Python 實現 是Cpython 實現的,也就是使用C語言實現的Python,其他的實現並沒有形成一個非常強大的生態,可以作為了解即可。
解釋器與字節碼
Understanding Python Bytecode
Python 字節碼介紹
死磕python字節碼手工還原python源碼,牛皮!