ShowMeAI日報系列全新升級!覆蓋AI人工智能 工具&框架 | 項目&代碼 | 博文&分享 | 數據&資源 | 研究&論文 等方向。點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送。點擊 專題合輯&電子月刊 快速浏覽各專題全集。點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包。
https://github.com/charmbracelet/gum
Gum 提供了高度可配置、即用型的實用程序,可以生成酷炫的 shell 腳本但無需編寫任何 Go 代碼。

https://github.com/HFAiLab/FourCastNet
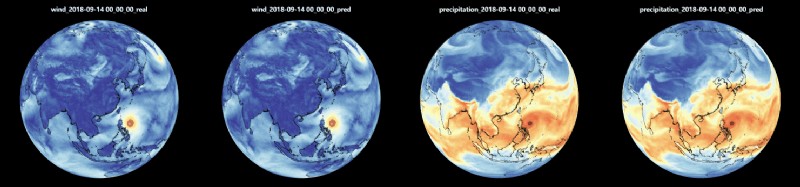
FourCastNet 是數據驅動的高分辨率全球天氣模型,也是第一個人工智能天氣模型,由 High-Flyer AI 部署和改進,能夠與 ECMWF (歐洲中期天氣預報中心)的綜合預報系統 IFS 進行直接比較。下圖為『台風預測路徑與真實路徑比較』『水汽濃度預測與真實數據比較』。
https://github.com/yhygao/CBIM-Medical-Image-Segmentation
CBIM Medical Image Segmentation 是基於 PyTorch 的醫學圖像分割框架,提供了CNN 和 Transformer 在多個醫學圖像數據集的評估與比較,為學術研究人員提供了一個易用的深度學習模型開發與評估的框架。
https://github.com/diffgram/diffgram
Diffgram 是第一個真正的開源訓練數據平台,為所有數據類型(Image、Video、Text、3D、Geo、Audio等)提供『從注釋到數據存儲』的工具,可以減少數據標注的費用,提高訓練數據的質量。

https://github.com/axelparmentier/InferOpt.jl
InferOpt.jl 是一個在機器學習管道中使用組合優化算法的工具箱,典型的例子包括混合整數線性程序或圖算法。
https://github.com/lichuang/storage-paper-reading-cn
作者當前工作方向集中在分布式、存儲引擎等領域,repo 記錄了作者在這個方向已經閱讀的論文解析、博客、文章索引,以及待閱讀的論文。
https://github.com/qx0731/Sharing_ISL_python
項目作者非常喜歡《An Introduction to Statistical Learning with Applications in R》(統計學習導論及R語言應用)這本書,因此用 Python 代碼實現了書中的代碼。

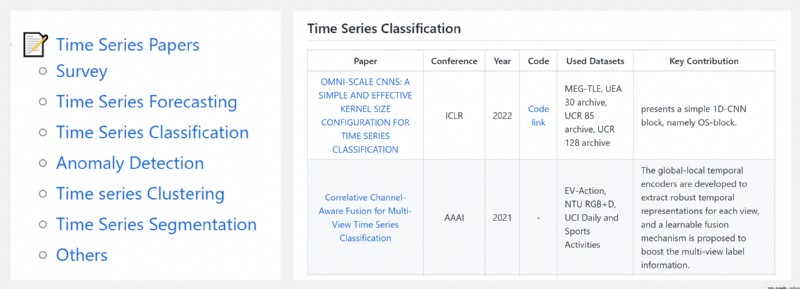
https://github.com/cure-lab/Awesome-time-series
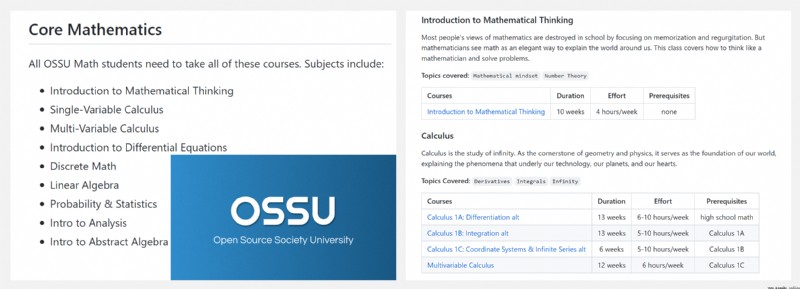
https://github.com/ossu/math
OSSU 課程是使用最TOP的在線資料進行的完整的數學教育,課程通常來自哈佛、麻省理工、斯坦福等頂級大學,能夠滿足一般本科數學專業的學位要求。本次數學路線圖包含以下內容:

可以點擊 這裡 回復關鍵字日報,免費獲取整理好的論文合輯。
科研論文
- 2022.07.21 『計算機視覺』 Sobolev Training for Implicit Neural Representations with Approximated Image Derivatives
- 2022.07.19 『計算機視覺』 Rethinking IoU-based Optimization for Single-stage 3D Object Detection
- 2022.07.19 『計算機視覺』 ParticleSfM: Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild
- 2022.07.20 『計算機視覺』 AiATrack: Attention in Attention for Transformer Visual Tracking
論文時間:21 Jul 2022
所屬領域:計算機視覺
論文地址:https://arxiv.org/abs/2207.10395
代碼實現:https://github.com/megvii-research/Sobolev_INRs
論文作者:Wentao Yuan, Qingtian Zhu, Xiangyue Liu, Yikang Ding, Haotian Zhang, Chi Zhang
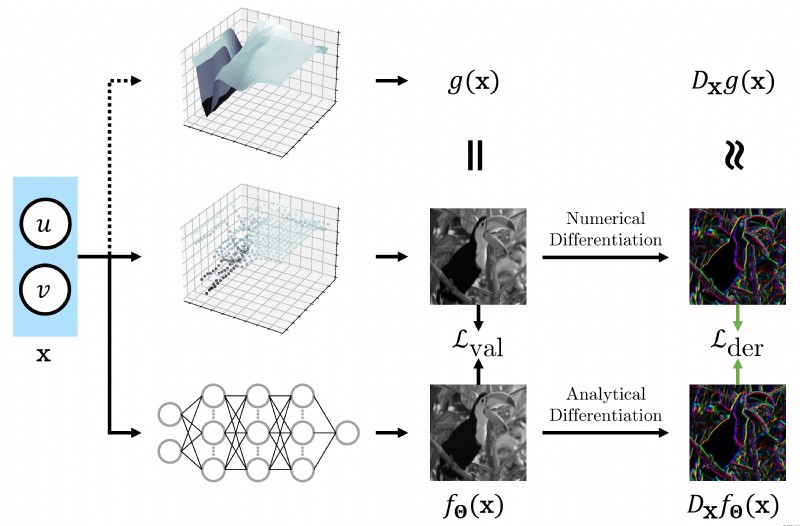
論文簡介:Recently, Implicit Neural Representations (INRs) parameterized by neural networks have emerged as a powerful and promising tool to represent different kinds of signals due to its continuous, differentiable properties, showing superiorities to classical discretized representations./最近,以神經網絡為參數的隱性神經表征(INRs)已經成為一種強大而有前途的工具,由於其連續、可區分的特性,顯示出比經典離散表征更多的優勢,可以表征不同種類的信號。
論文摘要:最近,以神經網絡為參數的隱性神經表征(INRs)由於其連續、可微分的特性而成為表征不同種類信號的強大和有前途的工具,顯示出比經典離散表征的優越性。然而,神經網絡的訓練只利用了輸入-輸出對,而目標輸出相對於輸入的導數,在某些情況下可以訪問,通常被忽略了。在本文中,我們為目標輸出為圖像像素的INRs提出了一種訓練范式,在神經網絡中除了圖像值之外,還對圖像導數進行編碼。具體來說,我們使用有限差分來逼近圖像導數。我們展示了如何利用該訓練范式來解決典型的INRs問題,即圖像回歸和反渲染,並證明該訓練范式可以提高INRs的數據效率和泛化能力。我們方法的代碼可在https://github.com/megvii-research/Sobolev_INRs獲取。
論文時間:19 Jul 2022
所屬領域:計算機視覺
對應任務:3D Object Detection,object-detection,Object Detection,3D目標檢測,目標檢測
論文地址:https://arxiv.org/abs/2207.09332
代碼實現:https://github.com/hlsheng1/rdiou
論文作者:Hualian Sheng, Sijia Cai, Na Zhao, Bing Deng, Jianqiang Huang, Xian-Sheng Hua, Min-Jian Zhao, Gim Hee Lee
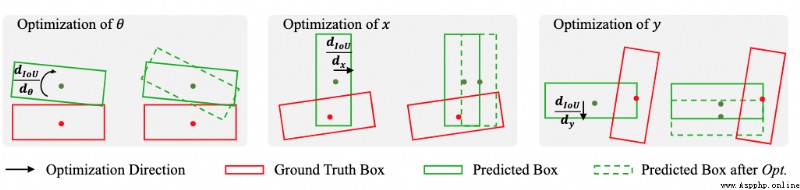
論文簡介:Since Intersection-over-Union (IoU) based optimization maintains the consistency of the final IoU prediction metric and losses, it has been widely used in both regression and classification branches of single-stage 2D object detectors./由於基於交叉聯合(IoU)的優化保持了最終IoU預測指標和損失的一致性,它已被廣泛用於一階段2D物體檢測器的回歸和分類分支。
論文摘要:由於基於交並比(IoU)的優化保持了最終IoU預測指標和損失的一致性,它已被廣泛用於一階段2D物體檢測器的回歸和分類分支。最近,一些三維物體檢測方法采用了基於IoU的優化,並直接用三維IoU代替二維IoU。然而,由於復雜的實現和低效的後向操作,這種直接的三維計算成本非常高。此外,基於3D IoU的優化是次優的,因為它對旋轉很敏感,因此會導致訓練不穩定和檢測性能下降。在本文中,我們提出了一種新穎的旋轉耦合物聯網(RDIoU)方法,它可以緩解旋轉敏感問題,並在訓練階段產生比三維物聯網更有效的優化目標。具體來說,我們的RDIoU通過將旋轉變量解耦為一個獨立項,簡化了回歸參數的復雜互動,但又保留了3D IoU的幾何結構。通過將RDIoU納入回歸和分類分支,鼓勵網絡學習更精確的邊界盒,同時克服分類和回歸之間的錯位問題。在基准KITTI和Waymo開放數據集上的廣泛實驗驗證了我們的RDIoU方法可以為單階段的3D物體檢測帶來實質性的改善。

論文時間:19 Jul 2022
所屬領域:計算機視覺
對應任務:Motion Segmentation,Optical Flow Estimation,Pose Estimation,運動分割,光流估計,位置估計
論文地址:https://arxiv.org/abs/2207.09137
代碼實現:https://github.com/bytedance/particle-sfm
論文作者:Wang Zhao, Shaohui Liu, Hengkai Guo, Wenping Wang, Yong-Jin Liu
論文簡介:In addition, our method is able to retain reasonable accuracy of camera poses on fully static scenes, which consistently outperforms strong state-of-the-art dense correspondence based methods with end-to-end deep learning, demonstrating the potential of dense indirect methods based on optical flow and point trajectories./此外,我們的方法能夠在完全靜態的場景上保持合理的攝像機姿勢精度,這一直優於基於端到端深度學習的強大的最先進的密集對應方法,證明了基於光流和點軌跡的密集間接方法的潛力。
論文摘要:從單目視頻中估計移動攝像機的姿勢是一個具有挑戰性的問題,特別是由於動態環境中存在移動物體,現有的攝像機姿勢估計方法的性能容易受到幾何上不一致的像素的影響。為了應對這一挑戰,我們提出了一種穩健的視頻密集間接結構方法,該方法基於從成對光流初始化的密集對應關系。我們的關鍵思想是將長距離視頻對應關系優化為密集點軌跡,並利用它來學習運動分割的穩健估計。我們提出了一個新的神經網絡結構來處理不規則的點軌跡數據。然後,在被歸類為靜態的長距離點軌跡的部分上,用全局捆綁調整來估計和優化攝像機姿勢。在MPI Sintel數據集上的實驗表明,與現有的最先進的方法相比,我們的系統產生的攝像機軌跡明顯更准確。此外,我們的方法能夠在完全靜態的場景中保留合理的相機姿態精度,這一直優於基於端到端深度學習的強大的最先進的密集對應方法,證明了基於光流和點軌跡的密集間接方法的潛力。由於點軌跡表示是通用的,我們進一步介紹了在動態物體復雜運動的野外單目視頻中的結果和比較。代碼可在https://github.com/bytedance/particle-sfm獲取。


論文時間:20 Jul 2022
所屬領域:計算機視覺
對應任務:Object Tracking,Visual Object Tracking,Visual Tracking,目標追蹤,視覺目標追蹤,視覺追蹤
論文地址:https://arxiv.org/abs/2207.09603
代碼實現:https://github.com/Little-Podi/AiATrack
論文作者:Shenyuan Gao, Chunluan Zhou, Chao Ma, Xinggang Wang, Junsong Yuan
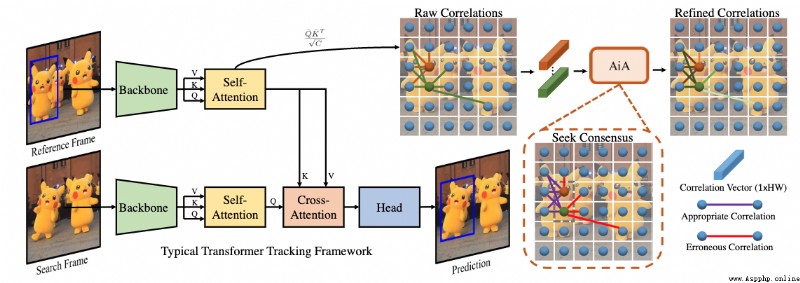
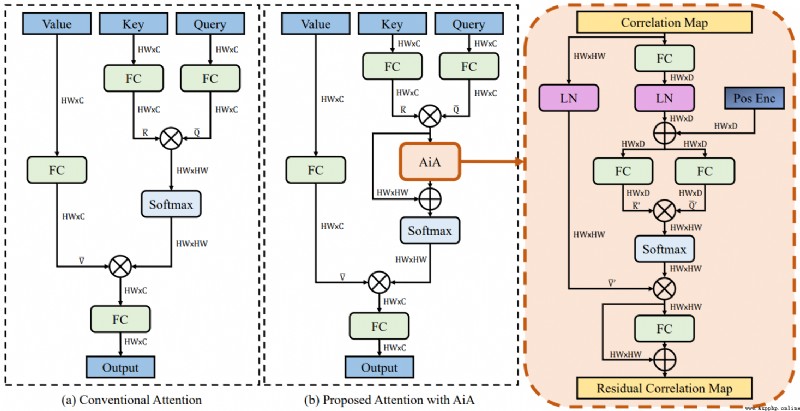
論文簡介:However, the independent correlation computation in the attention mechanism could result in noisy and ambiguous attention weights, which inhibits further performance improvement./然而,注意力機制中的獨立相關計算可能導致噪聲和模糊的注意力權重,這抑制了性能的進一步提高。
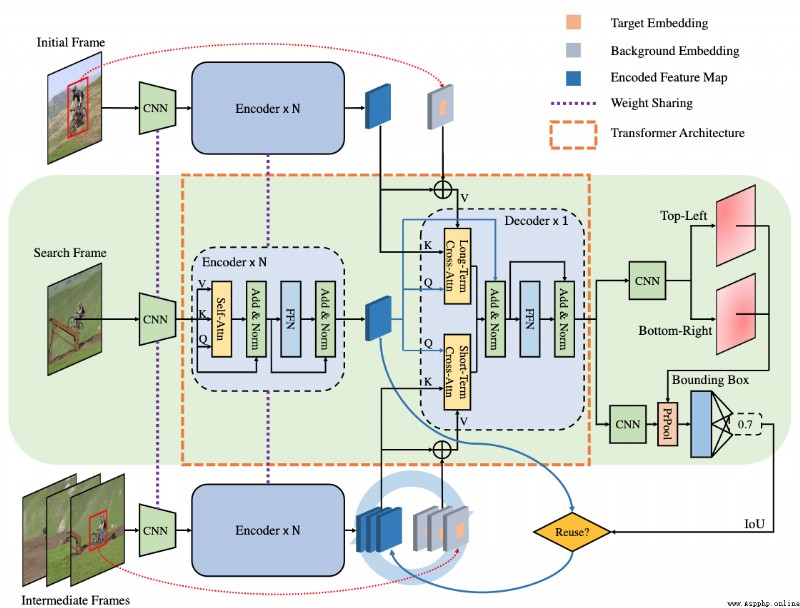
論文摘要:Transformer追蹤器最近取得了令人印象深刻的進展,其中注意力機制發揮了重要作用。然而,注意力機制中的獨立相關計算可能會導致噪聲和模糊的注意力權重,這抑制了性能的進一步提高。為了解決這個問題,我們提出了一個注意力中的注意力(AiA)模塊,它通過在所有的相關向量中尋求共識來增強適當的相關並抑制錯誤的相關。我們的AiA模塊可以很容易地應用於自注意塊和交叉注意塊,以促進視覺跟蹤的特征聚集和信息傳播。此外,我們提出了一個簡化的Transformer跟蹤框架,稱為AiATrack,通過引入有效的特征重用和目標-背景嵌入來充分利用時間參考。實驗表明,我們的跟蹤器在六個跟蹤基准上實現了最先進的性能,同時以實時速度運行。
我們是 ShowMeAI,致力於傳播AI優質內容,分享行業解決方案,用知識加速每一次技術成長!點擊查看 歷史文章列表,在公眾號內訂閱話題 #ShowMeAI資訊日報,可接收每日最新推送。點擊 專題合輯&電子月刊 快速浏覽各專題全集。點擊 這裡 回復關鍵字 日報 免費獲取AI電子月刊與資料包。