哈喽!大家好,我是「奇點」,江湖人稱 singularity。剛工作幾年,想和大家一同進步
一位上進心十足的【Java ToB端大廠領域博主】!
喜歡java和python,平時比較懶,能用程序解決的堅決不手動解決
如果有對【java】感興趣的【小可愛】,歡迎關注我️️️感謝各位大可愛小可愛!️️️
————————————————如果覺得本文對你有幫助,歡迎點贊,歡迎關注我,如果有補充歡迎評論交流,我將努力創作更多更好的文章。 今天繼續給大家分享python的學習筆記,之前吧python的基礎知識,譬如特點、發展史、基本數據類型,邏輯語句和循環語句和集合,時間、文件操作、異常處理和函數等基礎知識,有了這些入門知識,我們就能寫一下簡單的邏輯代碼了。今天我們繼續深入學習python到基礎知識。
對python 0基礎的同學可以看一下我的上篇文章,再來學習這篇文章,大佬可以直接跳過。
0基礎跟我學python(1) https://blog.csdn.net/qq_29235677/article/details/125967844
https://blog.csdn.net/qq_29235677/article/details/125967844
0基礎跟我學python(2)https://blog.csdn.net/qq_29235677/article/details/126033880

今天我們來繼續深入學習python的基礎篇,今天到主要內容是面向對象、模塊、命名空間和作用域、迭代器和生成器和任何使用測試。相信學習完今天到內容,你對python的基礎知識已經基本拿捏了。能夠編寫相對簡單的代碼了。
加油,甲人們️(為了油費加油)
目錄
️ 1.面向對象
(1)簡介
(2)類定義
(3)類對象
構造方法
self代表類的實例,而非類
(4)類的方法
(5)繼承
(6)多繼承
(7)方法重寫
子類繼承父類的構造函數
(8)類屬性與方法
類的私有屬性
類的方法
類的私有方法
運算符重載
總結:
️ 2.模塊
(1)定義
(2)引入語句import
(3) from … import 語句
(4)from … import * 語句
(5)深入了解模塊
(6)__name__屬性
(7)標准模塊
從一個包中導入*
️ 4.命名空間和作用域
(1)命名空間
(2)作用域
全局變量和局部變量
global 和 nonlocal關鍵字
️ 5.迭代器和生成器
(1)迭代器
創建迭代器
StopIteration
(2)生成器
Python從設計之初就已經是一門面向對象的語言,正因為如此,在Python中創建一個類和對象是很容易的。本章節我們將詳細介紹Python的面向對象編程。
如果你以前沒有接觸過面向對象的編程語言,那你可能需要先了解一些面向對象語言的一些基本特征,在頭腦裡頭形成一個基本的面向對象的概念,這樣有助於你更容易的學習Python的面向對象編程。如果你之前有使用過面向對象的語言,這裡進行學習的話就相對簡單多了。
我們直接把面向對象的設計方法進行類比,你就會發現基本上如出一轍。
接下來我們先來簡單的了解下面向對象的一些基本特征。
和其它編程語言相比,Python 在盡可能不增加新的語法和語義的情況下加入了類機制。
Python中的類提供了面向對象編程的所有基本功能:類的繼承機制允許多個基類,派生類可以覆蓋基類中的任何方法,方法中可以調用基類中的同名方法。
對象可以包含任意數量和類型的數據。
語法格式如下:
class ClassName:
<statement-1>
.
.
.
<statement-N>類實例化後,可以使用其屬性,實際上,創建一個類之後,可以通過類名訪問其屬性。
類對象支持兩種操作:屬性引用和實例化。
屬性引用使用和 Python 中所有的屬性引用一樣的標准語法:obj.name。
類對象創建後,類命名空間中所有的命名都是有效屬性名。所以如果類定義是這樣:
class MyClass:
"""一個簡單的類實例"""
i = 12345
def f(self):
return 'hello world'
# 實例化類
x = MyClass()
# 訪問類的屬性和方法
print("MyClass 類的屬性 i 為:", x.i)
print("MyClass 類的方法 f 輸出為:", x.f())以上創建了一個新的類實例並將該對象賦給局部變量 x,x 為空的對象。
結果
MyClass 類的屬性 i 為: 12345
MyClass 類的方法 f 輸出為: hello world
類有一個名為 __init__() 的特殊方法(構造方法),該方法在類實例化時會自動調用,像下面這樣:
def __init__(self):
self.data = []類定義了 __init__() 方法,類的實例化操作會自動調用 __init__() 方法。如下實例化類 MyClass,對應的 __init__() 方法就會被調用:
x = MyClass()當然, __init__() 方法可以有參數,參數通過 __init__() 傳遞到類的實例化操作上。例如:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 輸出結果:3.0 -4.5類的方法與普通的函數只有一個特別的區別——它們必須有一個額外的第一個參數名稱, 按照慣例它的名稱是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()輸出結果: <__main__.Test object at 0x10b4d2380> <class '__main__.Test'>
從執行結果可以很明顯的看出,self 代表的是類的實例,代表當前對象的地址,而 self.class 則指向類。
self 不是 python 關鍵字,我們把他換成 xx 也是可以正常執行的:
在類的內部,使用 def 關鍵字來定義一個方法,與一般函數定義不同,類方法必須包含參數 self, 且為第一個參數,self 代表的是類的實例。
#類定義
class people:
#定義基本屬性
name = ''
age = 0
#定義私有屬性,私有屬性在類外部無法直接進行訪問
__weight = 0
#定義構造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 說: 我 %d 歲。" %(self.name,self.age))
# 實例化類
p = people('小明',10,30)
p.speak()結果
小明 說: 我 10 歲。
Python 同樣支持類的繼承,如果一種語言不支持繼承,類就沒有什麼意義。派生類的定義如下所示:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>子類(派生類 DerivedClassName)會繼承父類(基類 BaseClassName)的屬性和方法。
BaseClassName(實例中的基類名)必須與派生類定義在一個作用域內。除了類,還可以用表達式,基類定義在另一個模塊中時這一點非常有用:
class DerivedClassName(modname.BaseClassName):#類定義
class people:
#定義基本屬性
name = ''
age = 0
#定義私有屬性,私有屬性在類外部無法直接進行訪問
__weight = 0
#定義構造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 說: 我 %d 歲。" %(self.name,self.age))
#單繼承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#調用父類的構函
people.__init__(self,n,a,w)
self.grade = g
#覆寫父類的方法
def speak(self):
print("%s 說: 我 %d 歲了,我在讀 %d 年級"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()結果
ken 說: 我 10 歲了,我在讀 3 年級
Python同樣有限的支持多繼承形式。多繼承的類定義形如下例:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>需要注意圓括號中父類的順序,若是父類中有相同的方法名,而在子類使用時未指定,python從左至右搜索 即方法在子類中未找到時,從左到右查找父類中是否包含方法。
#類定義
class people:
#定義基本屬性
name = ''
age = 0
#定義私有屬性,私有屬性在類外部無法直接進行訪問
__weight = 0
#定義構造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 說: 我 %d 歲。" %(self.name,self.age))
#單繼承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#調用父類的構函
people.__init__(self,n,a,w)
self.grade = g
#覆寫父類的方法
def speak(self):
print("%s 說: 我 %d 歲了,我在讀 %d 年級"%(self.name,self.age,self.grade))
#另一個類,多重繼承之前的准備
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一個演說家,我演講的主題是 %s"%(self.name,self.topic))
#多重繼承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默認調用的是在括號中參數位置排前父類的方法結果
我叫 Tim,我是一個演說家,我演講的主題是 Python
如果將speaker和student互換
class sample(student,speaker):
返回的結果是
Tim 說: 我 25 歲了,我在讀 4 年級
如果你的父類方法的功能不能滿足你的需求,你可以在子類重寫你父類的方法,實例如下:
class Parent: # 定義父類
def myMethod(self):
print ('調用父類方法')
class Child(Parent): # 定義子類
def myMethod(self):
print ('調用子類方法')
c = Child() # 子類實例
c.myMethod() # 子類調用重寫方法
super(Child,c).myMethod() #用子類對象調用父類已被覆蓋的方法super() 函數是用於調用父類(超類)的一個方法。
或者用下面方法調父類的方法,也會調用父類中的方法
Parent.myMethod(c)執行以上程序輸出結果為:
調用子類方法 調用父類方法
如果在子類中需要父類的構造方法就需要顯式地調用父類的構造方法,或者不重寫父類的構造方法。
子類不重寫 __init__,實例化子類時,會自動調用父類定義的 __init__。
class Father(object):
def __init__(self, name):
self.name=name
print ( "name: %s" %( self.name) )
def getName(self):
return 'Father ' + self.name
class Son(Father):
def getName(self):
return 'Son '+self.name
if __name__=='__main__':
son=Son('root')
print ( son.getName() )結果:
name: root Son root
如果重寫了__init__ 時,實例化子類,就不會調用父類已經定義的 __init__,語法格式如下:
class Father(object):
def __init__(self, name):
self.name=name
print ( "name: %s" %( self.name) )
def getName(self):
return 'Father ' + self.name
class Son(Father):
def __init__(self, name):
print ( "hi" )
self.name = name
def getName(self):
return 'Son '+self.name
if __name__=='__main__':
son=Son('xiaoming')
print ( son.getName() )結果
hi Son xiaoming
如果重寫了__init__ 時,要繼承父類的構造方法,可以使用 super 關鍵字:
super(子類,self).__init__(參數1,參數2,....)還有一種經典寫法:
父類名稱.__init__(self,參數1,參數2,...)class Father(object):
def __init__(self, name):
self.name=name
print ( "name: %s" %( self.name))
def getName(self):
return 'Father ' + self.name
class Son(Father):
def __init__(self, name):
super(Son, self).__init__(name)
print ("hi")
self.name = name
def getName(self):
return 'Son '+self.name
if __name__=='__main__':
son=Son('root')
print ( son.getName() )name: root hi Son root
相當於java中的private
__private_attrs:兩個下劃線開頭,聲明該屬性為私有,不能在類的外部被使用或直接訪問。在類內部的方法中使用時 self.__private_attrs。
在類的內部,使用 def 關鍵字來定義一個方法,與一般函數定義不同,類方法必須包含參數 self,且為第一個參數,self 代表的是類的實例。
self 的名字並不是規定死的,也可以使用 this,但是最好還是按照約定使用 self。
__private_method:兩個下劃線開頭,聲明該方法為私有方法,只能在類的內部調用 ,不能在類的外部調用。self.__private_methods。
class JustCounter:
__secretCount = 0 # 私有變量
publicCount = 0 # 公開變量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print (self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print (counter.publicCount)
print (counter.__secretCount) # 報錯,實例不能訪問私有變量結果
1
2
2
Traceback (most recent call last):
File "/usr/local/software/work/pycharmProjects/python-project/chapter15/faceObject.py", line 268, in <module>
print(counter.__secretCount) # 報錯,實例不能訪問私有變量
AttributeError: 'JustCounter' object has no attribute '__secretCount'
class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url # private
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self): # 私有方法
print('這是私有方法')
def foo(self): # 公共方法
print('這是公共方法')
self.__foo()
x = Site('菜鳥一枚', 'www.baidu.com')
x.who() # 正常輸出
x.foo() # 正常輸出
x.__foo() # 報錯name : 菜鳥一枚
url : www.baidu.com
這是公共方法
這是私有方法Traceback (most recent call last):
File "/usr/local/software/work/pycharmProjects/python-project/chapter15/faceObject.py", line 306, in <module>
x.__foo() # 報錯
AttributeError: 'Site' object has no attribute '__foo'
類的專有方法:
Python同樣支持運算符重載,我們可以對類的專有方法進行重載,實例如下:
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2)以上代碼執行結果如下所示:
Vector(7,8)
現在對python的面相對象進行一下總結,通過學習不難發現python和java實現面向對象基本上是相同的,下面就對比java對python的面相對象進行比較
方面python java相同點私有方法__雙下劃線實現,都是lpricate關鍵字都是不能被外部使用重寫直接重寫父類方法@Override構造方法__init__(self)類()類方法必須包含selfstatic修飾類對象引用和實例化代表實例指向selfthis繼承A(B)A extends Bjava只允許單繼承 python可以多繼承類屬性與方法類.屬性/方法類.屬性/方法在前面的幾個章節中我們基本上是用 python 解釋器來編程,如果你從 Python 解釋器退出再進入,那麼你定義的所有的方法和變量就都消失了。
為此 Python 提供了一個辦法,把這些定義存放在文件中,為一些腳本或者交互式的解釋器實例使用,這個文件被稱為模塊。
模塊是一個包含所有你定義的函數和變量的文件,其後綴名是.py。模塊可以被別的程序引入,以使用該模塊中的函數等功能。這也是使用 python 標准庫的方法。
使用標准庫的例子:
import sys
print('命令行參數如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路徑為:', sys.path, '\n')命令行參數如下:
/usr/local/software/work/pycharmProjects/python-project/chapter15/mode.py
Python 路徑為: ['/usr/local/software/work/pycharmProjects/python-project/chapter15', '/usr/local/software/work/pycharmProjects/python-project', '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display', '/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip', '/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10', '/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload', '/usr/local/software/work/pycharmProjects/python-project/venv/lib/python3.10/site-packages', '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend']
想使用 Python 源文件,只需在另一個源文件裡執行 import 語句,語法如下:
import module1[, module2[,... moduleN]當解釋器遇到 import 語句,如果模塊在當前的搜索路徑就會被導入。
搜索路徑是一個解釋器會先進行搜索的所有目錄的列表。如想要導入模塊 support,需要把命令放在腳本的頂端:
mysupport.py 模塊
def print_func(par):
print("Hello : ", par)
return用import導入mysupport.py 模塊
# 導入模塊
import mysupport as sp
# 現在可以調用模塊裡包含的函數了
sp.print_func("xx")Hello : xx
一個模塊只會被導入一次,不管你執行了多少次 import。這樣可以防止導入模塊被一遍又一遍地執行。
當我們使用 import 語句的時候,Python 解釋器是怎樣找到對應的文件的呢?
這就涉及到 Python 的搜索路徑,搜索路徑是由一系列目錄名組成的,Python 解釋器就依次從這些目錄中去尋找所引入的模塊。
這看起來很像環境變量,事實上,也可以通過定義環境變量的方式來確定搜索路徑。
搜索路徑是在 Python 編譯或安裝的時候確定的,安裝新的庫應該也會修改。搜索路徑被存儲在 sys 模塊中的 path 變量,做一個簡單的實驗,在交互式解釋器中,輸入以下代碼:
>>> import sys
>>> sys.pathsys.path 輸出是一個列表,其中第一項是空串 '',代表當前目錄(若是從一個腳本中打印出來的話,可以更清楚地看出是哪個目錄),亦即我們執行python解釋器的目錄(對於腳本的話就是運行的腳本所在的目錄)。
因此若像我一樣在當前目錄下存在與要引入模塊同名的文件,就會把要引入的模塊屏蔽掉。
了解了搜索路徑的概念,就可以在腳本中修改sys.path來引入一些不在搜索路徑中的模塊。
現在,在解釋器的當前目錄或者 sys.path 中的一個目錄裡面來創建一個fibo.py的文件,代碼如下:
# 斐波那契(fibonacci)數列模塊
def fib(n): # 定義到 n 的斐波那契數列
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a+b
print()
def fib2(n): # 返回到 n 的斐波那契數列
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a+b
return result然後進入Python解釋器,使用下面的命令導入這個模塊:
>>> import fibo
這樣做並沒有把直接定義在fibo中的函數名稱寫入到當前符號表裡,只是把模塊fibo的名字寫到了那裡。
可以使用模塊名稱來訪問函數:
>>>fibo.fib(1000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'如果你打算經常使用一個函數,你可以把它賦給一個本地的名稱:
>>> fib = fibo.fib
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377Python 的 from 語句讓你從模塊中導入一個指定的部分到當前命名空間中,語法如下:
from modname import name1[, name2[, ... nameN]]例如,要導入模塊 fibo 的 fib 函數,使用如下語句:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377這個聲明不會把整個fibo模塊導入到當前的命名空間中,它只會將fibo裡的fib函數引入進來。
把一個模塊的所有內容全都導入到當前的命名空間也是可行的,只需使用如下聲明:
from modname import *這提供了一個簡單的方法來導入一個模塊中的所有項目。然而這種聲明不該被過多地使用。
模塊除了方法定義,還可以包括可執行的代碼。這些代碼一般用來初始化這個模塊。這些代碼只有在第一次被導入時才會被執行。
每個模塊有各自獨立的符號表,在模塊內部為所有的函數當作全局符號表來使用。
所以,模塊的作者可以放心大膽的在模塊內部使用這些全局變量,而不用擔心把其他用戶的全局變量搞混。
從另一個方面,當你確實知道你在做什麼的話,你也可以通過 modname.itemname 這樣的表示法來訪問模塊內的函數。
模塊是可以導入其他模塊的。在一個模塊(或者腳本,或者其他地方)的最前面使用 import 來導入一個模塊,當然這只是一個慣例,而不是強制的。被導入的模塊的名稱將被放入當前操作的模塊的符號表中。
還有一種導入的方法,可以使用 import 直接把模塊內(函數,變量的)名稱導入到當前操作模塊。比如:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377這種導入的方法不會把被導入的模塊的名稱放在當前的字符表中(所以在這個例子裡面,fibo 這個名稱是沒有定義的)。
這還有一種方法,可以一次性的把模塊中的所有(函數,變量)名稱都導入到當前模塊的字符表:
>>> from fibo import *
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377這將把所有的名字都導入進來,但是那些由單一下劃線(_)開頭的名字不在此例。大多數情況, Python程序員不使用這種方法,因為引入的其它來源的命名,很可能覆蓋了已有的定義。
一個模塊被另一個程序第一次引入時,其主程序將運行。如果我們想在模塊被引入時,模塊中的某一程序塊不執行,我們可以用__name__屬性來使該程序塊僅在該模塊自身運行時執行。
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在運行')
else:
print('我來自另一模塊')$ python using_name.py 程序自身在運行
$ python
>>> import using_name
我來自另一模塊
>>>說明: 每個模塊都有一個__name__屬性,當其值是'__main__'時,表明該模塊自身在運行,否則是被引入。
說明:__name__ 與 __main__ 底下是雙下劃線, _ _ 是這樣去掉中間的那個空格。
Python 本身帶著一些標准的模塊庫,有些模塊直接被構建在解析器裡,這些雖然不是一些語言內置的功能,但是他卻能很高效的使用,甚至是系統級調用也沒問題。
這些組件會根據不同的操作系統進行不同形式的配置,比如 winreg 這個模塊就只會提供給 Windows 系統。
應該注意到這有一個特別的模塊 sys ,它內置在每一個 Python 解析器中。變量 sys.ps1 和 sys.ps2 定義了主提示符和副提示符所對應的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Runoob!')
Runoob!
C> ️ 3.包結構
包是一種管理 Python 模塊命名空間的形式,采用"點模塊名稱"。
比如一個模塊的名稱是 A.B, 那麼他表示一個包 A中的子模塊 B 。
就好像使用模塊的時候,你不用擔心不同模塊之間的全局變量相互影響一樣,采用點模塊名稱這種形式也不用擔心不同庫之間的模塊重名的情況。
這樣不同的作者都可以提供 NumPy 模塊,或者是 Python 圖形庫。
不妨假設你想設計一套統一處理聲音文件和數據的模塊(或者稱之為一個"包")。
現存很多種不同的音頻文件格式(基本上都是通過後綴名區分的,例如: .wav,:file:.aiff,:file:.au,),所以你需要有一組不斷增加的模塊,用來在不同的格式之間轉換。
並且針對這些音頻數據,還有很多不同的操作(比如混音,添加回聲,增加均衡器功能,創建人造立體聲效果),所以你還需要一組怎麼也寫不完的模塊來處理這些操作。
這裡給出了一種可能的包結構(在分層的文件系統中):
sound/ 頂層包
__init__.py 初始化 sound 包
formats/ 文件格式轉換子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 聲音效果子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ filters 子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...在導入一個包的時候,Python 會根據 sys.path 中的目錄來尋找這個包中包含的子目錄。
目錄只有包含一個叫做 __init__.py 的文件才會被認作是一個包,主要是為了避免一些濫俗的名字(比如叫做 string)不小心的影響搜索路徑中的有效模塊。
最簡單的情況,放一個空的 :file:__init__.py就可以了。當然這個文件中也可以包含一些初始化代碼或者為(將在後面介紹的) __all__變量賦值。
用戶可以每次只導入一個包裡面的特定模塊,比如:
import sound.effects.echo這將會導入子模塊:sound.effects.echo。 他必須使用全名去訪問:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
還有一種導入子模塊的方法是:
from sound.effects import echo這同樣會導入子模塊: echo,並且他不需要那些冗長的前綴,所以他可以這樣使用:
echo.echofilter(input, output, delay=0.7, atten=4)還有一種變化就是直接導入一個函數或者變量:
from sound.effects.echo import echofilter同樣的,這種方法會導入子模塊: echo,並且可以直接使用他的 echofilter() 函數:
echofilter(input, output, delay=0.7, atten=4)注意當使用 from package import item 這種形式的時候,對應的 item 既可以是包裡面的子模塊(子包),或者包裡面定義的其他名稱,比如函數,類或者變量。
import 語法會首先把 item 當作一個包定義的名稱,如果沒找到,再試圖按照一個模塊去導入。如果還沒找到,拋出一個 :exc:ImportError 異常。
反之,如果使用形如 import item.subitem.subsubitem 這種導入形式,除了最後一項,都必須是包,而最後一項則可以是模塊或者是包,但是不可以是類,函數或者變量的名字。
如果我們使用 from sound.effects import * 會發生什麼呢?
Python 會進入文件系統,找到這個包裡面所有的子模塊,然後一個一個的把它們都導入進來。
但這個方法在 Windows 平台上工作的就不是非常好,因為 Windows 是一個不區分大小寫的系統。
在 Windows 平台上,我們無法確定一個叫做 ECHO.py 的文件導入為模塊是 echo 還是 Echo,或者是 ECHO。
為了解決這個問題,我們只需要提供一個精確包的索引。
導入語句遵循如下規則:如果包定義文件 __init__.py 存在一個叫做 __all__ 的列表變量,那麼在使用 from package import * 的時候就把這個列表中的所有名字作為包內容導入。
作為包的作者,可別忘了在更新包之後保證 __all__ 也更新了啊。
以下實例在 file:sounds/effects/__init__.py 中包含如下代碼:
__all__ = ["echo", "surround", "reverse"]這表示當你使用from sound.effects import *這種用法時,你只會導入包裡面這三個子模塊。
如果 __all__ 真的沒有定義,那麼使用from sound.effects import *這種語法的時候,就不會導入包 sound.effects 裡的任何子模塊。他只是把包sound.effects和它裡面定義的所有內容導入進來(可能運行__init__.py裡定義的初始化代碼)。
這會把 __init__.py 裡面定義的所有名字導入進來。並且他不會破壞掉我們在這句話之前導入的所有明確指定的模塊。看下這部分代碼:
import sound.effects.echo
import sound.effects.surround
from sound.effects import *這個例子中,在執行 from...import 前,包 sound.effects 中的 echo 和 surround 模塊都被導入到當前的命名空間中了。(當然如果定義了 __all__ 就更沒問題了)
通常我們並不主張使用 * 這種方法來導入模塊,因為這種方法經常會導致代碼的可讀性降低。不過這樣倒的確是可以省去不少敲鍵的功夫,而且一些模塊都設計成了只能通過特定的方法導入。
記住,使用 from Package import specific_submodule 這種方法永遠不會有錯。事實上,這也是推薦的方法。除非是你要導入的子模塊有可能和其他包的子模塊重名。
如果在結構中包是一個子包(比如這個例子中對於包sound來說),而你又想導入兄弟包(同級別的包)你就得使用導入絕對的路徑來導入。比如,如果模塊sound.filters.vocoder 要使用包 sound.effects 中的模塊 echo,你就要寫成 from sound.effects import echo。
from . import echo
from .. import formats
from ..filters import equalizer無論是隱式的還是顯式的相對導入都是從當前模塊開始的。主模塊的名字永遠是"__main__",一個Python應用程序的主模塊,應當總是使用絕對路徑引用。
包還提供一個額外的屬性__path__。這是一個目錄列表,裡面每一個包含的目錄都有為這個包服務的__init__.py,你得在其他__init__.py被執行前定義哦。可以修改這個變量,用來影響包含在包裡面的模塊和子包。
這個功能並不常用,一般用來擴展包裡面的模塊。
命名空間(Namespace)是從名稱到對象的映射,大部分的命名空間都是通過 Python 字典來實現的。
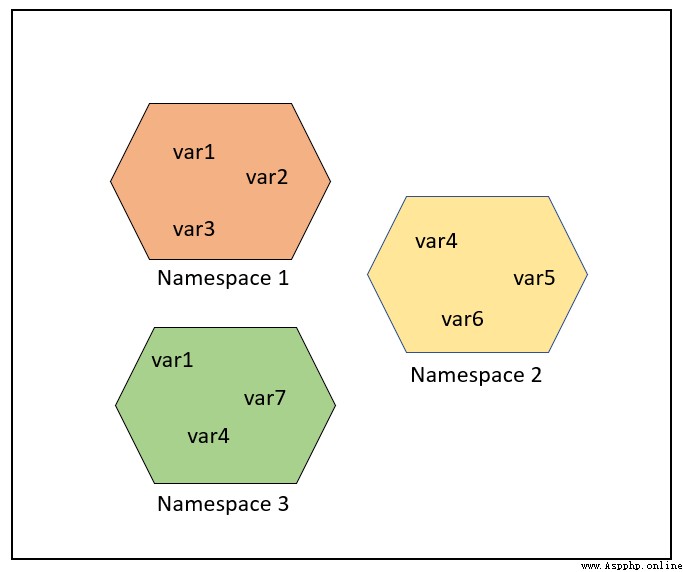
命名空間提供了在項目中避免名字沖突的一種方法。各個命名空間是獨立的,沒有任何關系的,所以一個命名空間中不能有重名,但不同的命名空間是可以重名而沒有任何影響。
我們舉一個計算機系統中的例子,一個文件夾(目錄)中可以包含多個文件夾,每個文件夾中不能有相同的文件名,但不同文件夾中的文件可以重名。
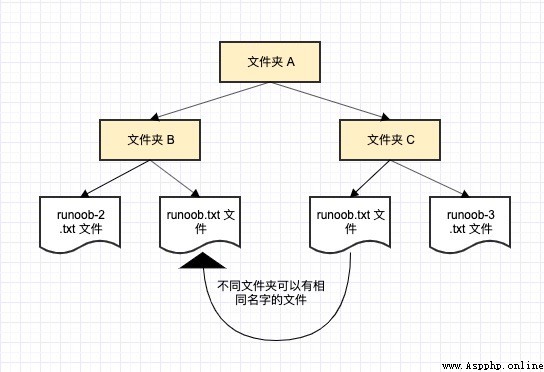
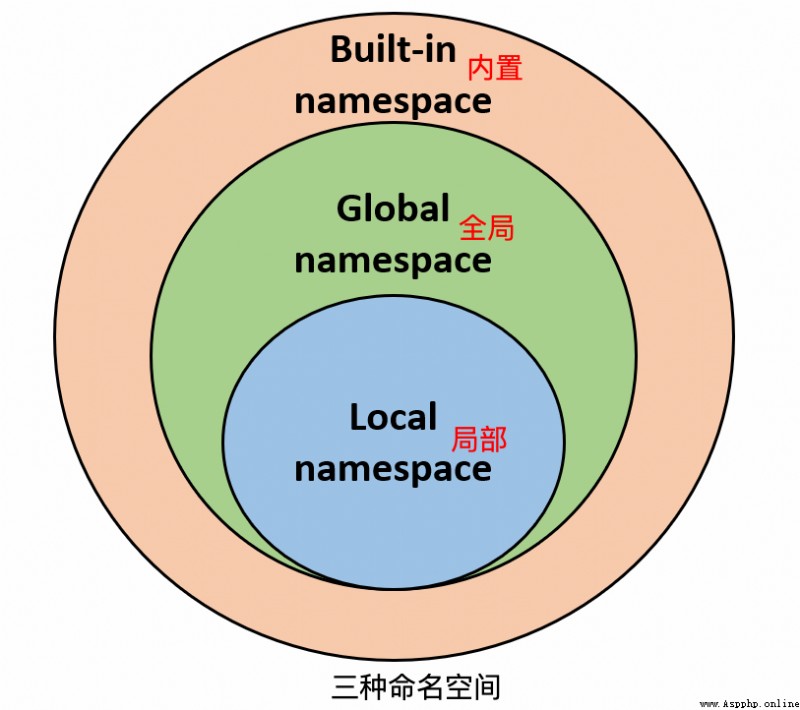
一般有三種命名空間:
命名空間查找順序:
假設我們要使用變量 root,則 Python 的查找順序為:局部的命名空間去 -> 全局命名空間 -> 內置命名空間。
如果找不到變量 root,它將放棄查找並引發一個 NameError 異常:
NameError: name 'root' is not defined。命名空間的生命周期:
命名空間的生命周期取決於對象的作用域,如果對象執行完成,則該命名空間的生命周期就結束。
因此,我們無法從外部命名空間訪問內部命名空間的對象。
# var1 是全局名稱
var1 = 5
def some_func():
# var2 是局部名稱
var2 = 6
def some_inner_func():
# var3 是內嵌的局部名稱
var3 = 7如下圖所示,相同的對象名稱可以存在於多個命名空間中。
作用域就是一個 Python 程序可以直接訪問命名空間的正文區域。
在一個 python 程序中,直接訪問一個變量,會從內到外依次訪問所有的作用域直到找到,否則會報未定義的錯誤。Python 中,程序的變量並不是在哪個位置都可以訪問的,訪問權限決定於這個變量是在哪裡賦值的。
變量的作用域決定了在哪一部分程序可以訪問哪個特定的變量名稱。Python 的作用域一共有4種,分別是:
有四種作用域:
規則順序: L –> E –> G –> B。
在局部找不到,便會去局部外的局部找(例如閉包),再找不到就會去全局找,再者去內置中找。

g_count = 0 # 全局作用域
def outer():
o_count = 1 # 閉包函數外的函數中
def inner():
i_count = 2 # 局部作用域內置作用域是通過一個名為 builtin 的標准模塊來實現的,但是這個變量名自身並沒有放入內置作用域內,所以必須導入這個文件才能夠使用它。在Python3.0中,可以使用以下的代碼來查看到底預定義了哪些變量:
>>> import builtins
>>> dir(builtins)Python 中只有模塊(module),類(class)以及函數(def、lambda)才會引入新的作用域,其它的代碼塊(如 if/elif/else/、try/except、for/while等)是不會引入新的作用域的,也就是說這些語句內定義的變量,外部也可以訪問,如下代碼:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>> 實例中 msg 變量定義在 if 語句塊中,但外部還是可以訪問的。
如果將 msg 定義在函數中,則它就是局部變量,外部不能訪問:
>>> def test():
... msg_inner = 'I am from Runoob'
...
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
>>> 從報錯的信息上看,說明了 msg_inner 未定義,無法使用,因為它是局部變量,只有在函數內可以使用。
全局作用域,
整個程序范圍內訪問
局部作用域,被聲明的函數內部訪問定義定義在函數外定義在函數內部定義在函數內部的變量擁有一個局部作用域,定義在函數外的擁有全局作用域。
局部變量只能在其被聲明的函數內部訪問,而全局變量可以在整個程序范圍內訪問。調用函數時,所有在函數內聲明的變量名稱都將被加入到作用域中。如下實例:
total = 0 # 這是一個全局變量
# 可寫函數說明
def sum( arg1, arg2 ):
#返回2個參數的和."
total = arg1 + arg2 # total在這裡是局部變量.
print ("函數內是局部變量 : ", total)
return total
#調用sum函數
sum( 10, 20 )
print ("函數外是全局變量 : ", total)結果
函數內是局部變量 : 30
函數外是全局變量 : 0
當內部作用域想修改外部作用域的變量時,就要用到 global 和 nonlocal 關鍵字了。
以下實例修改全局變量 num:
num = 1
def fun1():
global num # 需要使用 global 關鍵字聲明
print(num)
num = 123
print(num)
fun1()
print(num)1 123 123
如果要修改嵌套作用域(enclosing 作用域,外層非全局作用域)中的變量則需要 nonlocal 關鍵字了,如下實例:
num = 1
def outer():
num = 10
def inner():
nonlocal num # nonlocal關鍵字聲明
num = 100
print(num)
inner()
print(num)
outer()
print(num)100
100
1
另外有一種特殊情況,假設下面這段代碼被運行:
a = 10
def test():
a = a + 1
print(a)
test()Traceback (most recent call last):
File "/usr/local/software/work/pycharmProjects/python-project/chapter15/namespace.py", line 55, in <module>
test()
File "/usr/local/software/work/pycharmProjects/python-project/chapter15/namespace.py", line 51, in test
a = a + 1
UnboundLocalError: local variable 'a' referenced before assignment
錯誤信息為局部作用域引用錯誤,因為 test 函數中的 a 使用的是局部,未定義,無法修改。
修改 a 為全局變量:
a = 10
def test():
global a
a = a + 1
print(a)
test()11
也可以通過傳參數實現
a = 10
def test(a):
a = a + 1
print(a)
test(a)11
迭代是Python最強大的功能之一,是訪問集合元素的一種方式。
迭代器是一個可以記住遍歷的位置的對象。
迭代器對象從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。迭代器只能往前不會後退。
迭代器有兩個基本的方法:iter() 和 next()。
字符串,列表或元組對象都可用於創建迭代器:
>>> list=[1,2,3,4]
>>> it = iter(list) # 創建迭代器對象
>>> print (next(it)) # 輸出迭代器的下一個元素
1
>>> print (next(it))
2
>>>迭代器對象可以使用常規for語句進行遍歷:
list=[1,2,3,4]
it = iter(list) # 創建迭代器對象
for x in it:
print (x, end=" ")1 2 3 4
也可以使用 next() 函數:
import sys # 引入 sys 模塊
list=[1,2,3,4]
it = iter(list) # 創建迭代器對象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()1 2 3 4
把一個類作為一個迭代器使用需要在類中實現兩個方法 __iter__() 與 __next__() 。
如果你已經了解的面向對象編程,就知道類都有一個構造函數,Python 的構造函數為 __init__(), 它會在對象初始化的時候執行。
__iter__() 方法返回一個特殊的迭代器對象, 這個迭代器對象實現了 __next__() 方法並通過 StopIteration 異常標識迭代的完成。
__next__() 方法(Python 2 裡是 next())會返回下一個迭代器對象。
創建一個返回數字的迭代器,初始值為 1,逐步遞增 1:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))1 2 3 4 5
StopIteration 異常用於標識迭代的完成,防止出現無限循環的情況,在 __next__() 方法中我們可以設置在完成指定循環次數後觸發 StopIteration 異常來結束迭代。
在 20 次迭代後停止執行:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
在 Python 中,使用了 yield 的函數被稱為生成器(generator)。
跟普通函數不同的是,生成器是一個返回迭代器的函數,只能用於迭代操作,更簡單點理解生成器就是一個迭代器。
在調用生成器運行的過程中,每次遇到 yield 時函數會暫停並保存當前所有的運行信息,返回 yield 的值, 並在下一次執行 next() 方法時從當前位置繼續運行。
調用一個生成器函數,返回的是一個迭代器對象。
以下實例使用 yield 實現斐波那契數列:
import sys
def fibonacci(n): # 生成器函數 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一個迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()0 1 1 2 3 5 8 13 21 34 55

如果覺得本文對你有幫助,歡迎點贊,歡迎關注我,如果有補充歡迎評論交流,我將努力創作更多更好的文章。