目錄
生成一維數組
生成DataFrame
2D data viewing
View the index of 2D data、Column names and data
查看數據的統計信息
2D data transpose
排序
數據選擇
All rows that sum to a specific value
數據修改
對行求和,增加一列;對列求和,增加一行
缺失值處理
重復值處理
異常值處理
拆分與合並/連接
分組計算
pandas主要提供了3種數據結構:1)Series,帶標簽的一維數組;2)DataFrame,帶標簽且大小可變的二維表格結構;3)Panel,帶標簽且大小可變的三維數組.
pythonabout data structuresSeries的講解_C.DLording的博客-CSDN博客_series在python
>>> import numpy as np
>>> import pandas as pd
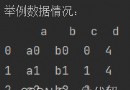
>>> x = pd.Series([1, 3, 5, np.nan]) # np.nan表示空值、缺失值
>>> x
0 1.0
1 3.0
2 5.0
3 NaN
dtype: float64
>>> dates = pd.date_range(start='20200101', end='20201231', freq='M') # interval in months,每月最後一天

import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import pandas as pd
dates = pd.date_range(start='20200101', end='20201231', freq='M')
dataframe=pd.DataFrame(np.random.randn(12,4), index=dates, columns=list('ABCD'))
print(dataframe)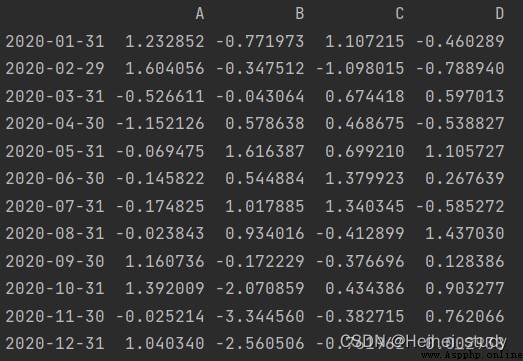
>>> pd.DataFrame([np.random.randint(1, 100, 4) for i in range(12)],
index=dates, columns=list('ABCD')) # 4列隨機數
>>> df.head() # 默認顯示前5行
A B C D E F
zhang 20 2020-01-01 1.0 3 test foo
li 26 2020-01-02 2.0 3 train foo
zhou 63 2020-01-03 3.0 3 test foo
wang 69 2020-01-04 4.0 3 train foo
>>> df.head(3) # 查看前3行
A B C D E F
zhang 20 2020-01-01 1.0 3 test foo
li 26 2020-01-02 2.0 3 train foo
zhou 63 2020-01-03 3.0 3 test foo
>>> df.tail(2) # 查看最後2行
A B C D E F
zhou 63 2020-01-03 3.0 3 test foo
wang 69 2020-01-04 4.0 3 train foo
print(df.index)
print(df.columns)
print(df.values)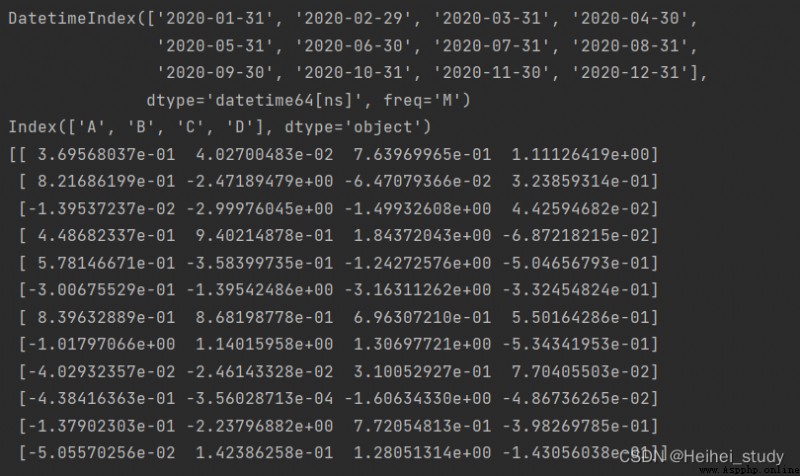
>>> df.describe() # 平均值、標准差、最小值、最大值等信息
>>> df.T
pandas(五)排序_Brilliant blog-CSDN博客
注:This place selects a field name Not the specific values in the table
>>> df['A'] # 選擇列
zhang 20
li 26
zhou 63
wang 69
Name: A, dtype: int32
>>> 69 in df['A'] # df['A']是一個Series對象
False
>>> 69 in df['A'].values
True
>>> df[0:2] # Use slices to select multiple rows
A B C D E F
zhang 20 2020-01-01 1.0 3 test foo
li 26 2020-01-02 2.0 3 train foo
>>> df.loc[:, ['A', 'C']] # 選擇多列,等價於df[['A', 'C']]
A C
zhang 20 1.0
li 26 2.0
zhou 63 3.0
wang 69 4.0
>>> df.loc[['zhang', 'zhou'], ['A', 'D', 'E']]
# Specify multiple rows and columns to select at the same time
A D E
zhang 20 3 test
zhou 63 3 test
>>> df.loc['zhang', ['A', 'D', 'E']]
A 20
D 3
E test
Name: zhang, dtype: object
>>> df.at['zhang', 'A'] # 查詢指定行、The data value for the column position
20
>>> df.at['zhang', 'D']
3
>>> df.iloc[3] # 查詢第3行數據
A 69
B 2020-01-04 00:00:00
C 4
D 3
E train
F foo
Name: wang, dtype: object
>>> df.iloc[0:3, 0:4] # 查詢前3行、前4列數據
A B C D
zhang 20 2020-01-01 1.0 3
li 26 2020-01-02 2.0 3
zhou 63 2020-01-03 3.0 3
>>> df.iloc[[0, 2, 3], [0, 4]] # Query the specified multiple rows、多列數據
A E
zhang 20 test
zhou 63 test
wang 69 train
>>> df.iloc[0,1] # 查詢第0行第1The data value for the column position
Timestamp('2020-01-01 00:00:00')
>>> df.iloc[2,2] # 查詢第2行第2The data value for the column position
3.0
>>> df[df.A>50] # Query by given criteria
A B C D E F
zhou 63 2020-01-03 3.0 3 test foo
wang 69 2020-01-04 4.0 3 train foo
>>> df[df['E']=='test'] # Query by given criteria
A B C D E F
zhang 20 2020-01-01 1.0 3 test foo
zhou 63 2020-01-03 3.0 3 test foo
>>> df[df['A'].isin([20,69])]
A B C D E F
zhang 20 2020-01-01 1.0 3 test foo
wang 69 2020-01-04 4.0 3 train foo
>>> df.nlargest(3, ['C']) # Returns the largest front of the specified column3行
A B C D E F
wang 69 2020-01-04 4.0 3 train foo
zhou 63 2020-01-03 3.0 3 test foo
li 26 2020-01-02 2.0 3 train foo
>>> df.nlargest(3, ['A'])
A B C D E F
wang 69 2020-01-04 4.0 3 train foo
zhou 63 2020-01-03 3.0 3 test foo
li 26 2020-01-02 2.0 3 train foo
>>> dff = pd.DataFrame({'A':[1,2,3,4], 'B':[10,20,8,40]})
>>> dff
A B
0 1 10
1 2 20
2 3 8
3 4 40
>>> dff[dff.sum(axis=1)==11]
A B
0 1 10
2 3 8
>>> df.iat[0, 2] = 3 # 修改指定行、The data value for the column position
>>> df.loc[:, 'D'] = np.random.randint(50, 60, 4)
# 修改某列的值
>>> df['C'] = -df['C'] # Invert the specified column data
>>> df # 查看修改結果
A B C D E F
zhang 20 2020-01-01 -3.0 53 test foo
li 26 2020-01-02 -2.0 59 train foo
zhou 63 2020-01-03 -3.0 59 test foo
wang 69 2020-01-04 -4.0 50 train foo
>>> from copy import deepcopy
>>> dff = deepcopy(df)
>>> dff
A B C D E F
zhang 20 2020-01-01 -3.0 53 test foo
li 26 2020-01-02 -2.0 59 train foo
zhou 63 2020-01-03 -3.0 59 test foo
wang 69 2020-01-04 -4.0 50 train foo
>>> dff['C'] = dff['C'] ** 2 # 替換列數據
>>> dff
A B C D E F
zhang 20 2020-01-01 9.0 53 test foo
li 26 2020-01-02 4.0 59 train foo
zhou 63 2020-01-03 9.0 59 test foo
wang 69 2020-01-04 16.0 50 train foo
>>> data = pd.DataFrame({'k1':['one'] * 3 + ['two'] * 4,
'k2':[1, 1, 2, 3, 3, 4, 4]})
>>> data.replace(1, 5) # 把所有1替換為5
k1 k2
0 one 5
1 one 5
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
>>> data.replace([1,2],[5,6]) # 1->5,2->6
k1 k2
0 one 5
1 one 5
2 one 6
3 two 3
4 two 3
5 two 4
6 two 4
>>> data.replace({1:5, 'one':'ONE'}) # Use a dictionary to specify replacement relationships
k1 k2
0 ONE 5
1 ONE 5
2 ONE 2
3 two 3
4 two 3
5 two 4
6 two 4
>>> data = pd.DataFrame({'k1':['one'] * 3 + ['two'] * 4,
'k2':[1, 1, 2, 3, 3, 4, 4]})
>>> data
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
>>> data.drop(5, axis=0) # 刪除指定行
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
6 two 4
>>> data.drop(3, inplace=True) # 原地刪除
>>> data
k1 k2
0 one 1
1 one 1
2 one 2
4 two 3
5 two 4
6 two 4
>>> data.drop('k1', axis=1) # 刪除指定列
k2
0 1
1 1
2 2
4 3
5 4
6 4
>>> data = pd.DataFrame({'age':np.random.randint(20,50,5)})
>>> data
age
0 31
1 27
2 26
3 33
4 37
>>> data['rank'] = data['age'].rank() # Adds a column of bit sequence numbers
>>> data
age rank
0 31 3.0
1 27 2.0
2 26 1.0
3 33 4.0
4 37 5.0>>> data = pd.DataFrame({'姓名':['張三','李四','王五','趙六','劉七','孫八'],
'成績':[86,92,86,60,78,78]})
>>> data
姓名 成績
0 張三 86
1 李四 92
2 王五 86
3 趙六 60
4 劉七 78
5 孫八 78
>>> data['排名'] = data['成績'].rank(method='min') # Countdown,Tie the minimum value
>>> data
姓名 成績 排名
0 張三 86 4.0
1 李四 92 6.0
2 王五 86 4.0
3 趙六 60 1.0
4 劉七 78 2.0
5 孫八 78 2.0
>>> data['排名'] = data['成績'].rank(method='min', ascending=False)
>>> data # Positive ranking,The tie ranks take the minimum value
姓名 成績 排名
0 張三 86 2.0
1 李四 92 1.0
2 王五 86 2.0
3 趙六 60 6.0
4 劉七 78 4.0
5 孫八 78 4.0
>>> data['排名'] = data['成績'].rank(method='max', ascending=False)
>>> data # Positive ranking,The tie ranks take the maximum value
姓名 成績 排名
0 張三 86 3.0
1 李四 92 1.0
2 王五 86 3.0
3 趙六 60 6.0
4 劉七 78 5.0
5 孫八 78 5.0
>>> data['排名'] = data['成績'].rank(method='max')
>>> data # Countdown,The tie ranks take the maximum value
姓名 成績 排名
0 張三 86 5.0
1 李四 92 6.0
2 王五 86 5.0
3 趙六 60 1.0
4 劉七 78 3.0
5 孫八 78 3.0
>>> data['排名'] = data['成績'].rank(method='average')
>>> data # Countdown,The tied rankings are averaged
姓名 成績 排名
0 張三 86 4.5
1 李四 92 6.0
2 王五 86 4.5
3 趙六 60 1.0
4 劉七 78 2.5
5 孫八 78 2.5
>>> dff = pd.DataFrame({'A':[1,2,3,4], 'B':[10,20,8,40]})
>>> dff
A B
0 1 10
1 2 20
2 3 8
3 4 40
>>> dff['ColSum'] = dff.apply(sum, axis=1) # 對行求和,增加1列
>>> dff.loc['RowSum'] = dff.apply(sum, axis=0) # 對列求和,增加1行
>>> dff
A B ColSum
0 1 10 11
1 2 20 22
2 3 8 11
3 4 40 44
RowSum 10 78 88
>>> df
A B C D E F
zhang 20 2020-01-01 9.0 53 test foo
li 26 2020-01-02 4.0 59 train foo
zhou 63 2020-01-03 9.0 59 test foo
wang 69 2020-01-04 16.0 50 train foo
>>> df1 = df.reindex(columns=list(df.columns) + ['G'])
>>> df1
A B C D E F G
zhang 20 2020-01-01 9.0 53 test foo NaN
li 26 2020-01-02 4.0 59 train foo NaN
zhou 63 2020-01-03 9.0 59 test foo NaN
wang 69 2020-01-04 16.0 50 train foo NaN
>>> df1.iat[0, 6] = 3 # 修改指定位置元素值,The other elements in this column are missing valuesNaN
>>> df1
A B C D E F G
zhang 20 2020-01-01 9.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo NaN
zhou 63 2020-01-03 9.0 59 test foo NaN
wang 69 2020-01-04 16.0 50 train foo NaN
>>> pd.isnull(df1) # 測試缺失值,返回值為True/False陣列
A B C D E F G
zhang False False False False False False False
li False False False False False False True
zhou False False False False False False True
wang False False False False False False True
>>> df1.dropna() # Returns rows that do not contain missing values
A B C D E F G
zhang 20 2020-01-01 9.0 53 test foo 3.0
>>> from copy import deepcopy
>>> df2 = deepcopy(df1)
>>> df1['G'].fillna(5, inplace=True) # 使用指定值填充缺失值
>>> df1
A B C D E F G
zhang 20 2020-01-01 9.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo 5.0
zhou 63 2020-01-03 9.0 59 test foo 5.0
wang 69 2020-01-04 16.0 50 train foo 5.0
>>> df2.iat[2, 5] = np.NaN
>>> df2
A B C D E F G
zhang 20 2020-01-01 1.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo NaN
zhou 63 2020-01-03 9.0 59 test NaN NaN
wang 69 2020-01-04 16.0 50 train foo NaN
>>> df2.dropna(thresh=6) # 返回包含6data with more than one valid value
A B C D E F G
zhang 20 2020-01-01 1.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo NaN
wang 69 2020-01-04 16.0 50 train foo NaN
>>> df2.iat[3, 6] = 8
>>> df2
A B C D E F G
zhang 20 2020-01-01 1.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo NaN
zhou 63 2020-01-03 9.0 59 test NaN NaN
wang 69 2020-01-04 16.0 50 train foo 8.0
>>> df2.fillna({'F':'foo', 'G':df2['G'].mean()}) # 填充缺失值
A B C D E F G
zhang 20 2020-01-01 1.0 53 test foo 3.0
li 26 2020-01-02 4.0 59 train foo 5.5
zhou 63 2020-01-03 9.0 59 test foo 5.5
wang 69 2020-01-04 16.0 50 train foo 8.0
>>> import numpy as np
>>> import pandas as pd
>>> dft = pd.DataFrame({'a':[1,np.NaN, np.NaN,3]})
>>> dft.fillna(method='pad') # Fill with the last valid value before the missing value
a
0 1.0
1 1.0
2 1.0
3 3.0
>>> dft.fillna(method='bfill') # Fill back with the first valid value after using missing values
a
0 1.0
1 3.0
2 3.0
3 3.0
>>> dft.fillna(method='bfill', limit=1) # Fill only one missing value
a
0 1.0
1 NaN
2 3.0
3 3.0
>>> data = pd.DataFrame({'k1':['one'] * 3 + ['two'] * 4,
'k2':[1, 1, 2, 3, 3, 4, 4]})
>>> data
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
>>> data.duplicated() # Check for duplicate lines
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
>>> data.drop_duplicates() # 返回新數組,刪除重復行
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
>>> data.drop_duplicates(['k1']) # 刪除k1列的重復數據,Only the first item is kept
k1 k2
0 one 1
3 two 3
>>> data.drop_duplicates(['k1'], keep='last') # Keep the last item
k1 k2
2 one 2
6 two 4
>>> data = pd.Series([3,3,3,2,1,1,1,0])
>>> data
0 3
1 3
2 3
3 2
4 1
5 1
6 1
7 0
dtype: int64
>>> data.drop_duplicates(keep=False) # Only numbers that appear once are kept
3 2
7 0
dtype: int64
>>> df2 = pd.DataFrame(np.random.randn(10, 4))
>>> df2
0 1 2 3
0 2.064867 -0.888018 0.586441 -0.660901
1 -0.465664 -0.496101 0.249952 0.627771
2 1.974986 1.304449 -0.168889 -0.334622
3 0.715677 2.017427 1.750627 -0.787901
4 -0.370020 -0.878282 0.499584 0.269102
5 0.184308 0.653620 0.117899 -1.186588
6 -0.364170 1.652270 0.234833 0.362925
7 -0.329063 0.356276 1.158202 -1.063800
8 -0.778828 -0.156918 -0.760394 -0.040323
9 -0.391045 -0.374825 -1.016456 0.767481
>>> p1 = df2[:3] # Data row splitting
>>> p1
0 1 2 3
0 2.064867 -0.888018 0.586441 -0.660901
1 -0.465664 -0.496101 0.249952 0.627771
2 1.974986 1.304449 -0.168889 -0.334622
>>> p2 = df2[3:7]
>>> p3 = df2[7:]
>>> df3 = pd.concat([p1, p2, p3]) # 數據行合並
>>> df4 = pd.DataFrame({'A':np.random.randint(1,5,8),
'B':np.random.randint(10,15,8),
'C':np.random.randint(20,30,8),
'D':np.random.randint(80,100,8)})
>>> df4
A B C D
0 1 13 26 81
1 3 14 29 88
2 1 13 28 88
3 2 10 21 90
4 4 14 28 83
5 4 11 24 81
6 2 11 26 99
7 3 13 25 91
>>> df4.groupby('A').sum() # Data grouping calculation
B C D
A
1 26 54 169
2 21 47 189
3 27 54 179
4 25 52 164
>>> df4.groupby(by=['A', 'B']).mean()
C D
A B
1 13 27.0 84.5
2 10 21.0 90.0
11 26.0 99.0
3 13 25.0 91.0
14 29.0 88.0
4 11 24.0 81.0
14 28.0 83.0
>>> df4.groupby(by=['A', 'B'], as_index=False).mean()
A B C D
0 1 13 27.0 84.5
1 2 10 21.0 90.0
2 2 11 26.0 99.0
3 3 13 25.0 91.0
4 3 14 29.0 88.0
5 4 11 24.0 81.0
6 4 14 28.0 83.0
>>> df4.groupby(by=['A', 'B']).aggregate({'C':np.mean, 'D':np.min})
# 分組後,CColumns use the mean,DThe column uses the minimum value
C D
A B
1 13 27 81
2 10 21 90
11 26 99
3 13 25 91
14 29 88
4 11 24 81
14 28 83