def procentual_proximity(
source_data: list[list[float]], weights: list[int]
) -> list[list[float]]:
# getting data
data_lists: list[list[float]] = []
for data in source_data:
for i, el in enumerate(data):
if len(data_lists) < i + 1:
data_lists.append([])
data_lists[i].append(float(el))
score_lists: list[list[float]] = []
# calculating each score
for dlist, weight in zip(data_lists, weights):
mind = min(dlist)
maxd = max(dlist)
score: list[float] = []
# for weight 0 score is 1 - actual score
if weight == 0:
for item in dlist:
try:
score.append(1 - ((item - mind) / (maxd - mind)))
except ZeroDivisionError:
score.append(1)
elif weight == 1:
for item in dlist:
try:
score.append((item - mind) / (maxd - mind))
except ZeroDivisionError:
score.append(0)
# weight not 0 or 1
else:
raise ValueError(f"Invalid weight of {
weight:f} provided")
score_lists.append(score)
# initialize final scores
final_scores: list[float] = [0 for i in range(len(score_lists[0]))]
# generate final scores
for i, slist in enumerate(score_lists):
for j, ele in enumerate(slist):
final_scores[j] = final_scores[j] + ele
# append scores to source data
for i, ele in enumerate(final_scores):
source_data[i].append(ele)
return source_data
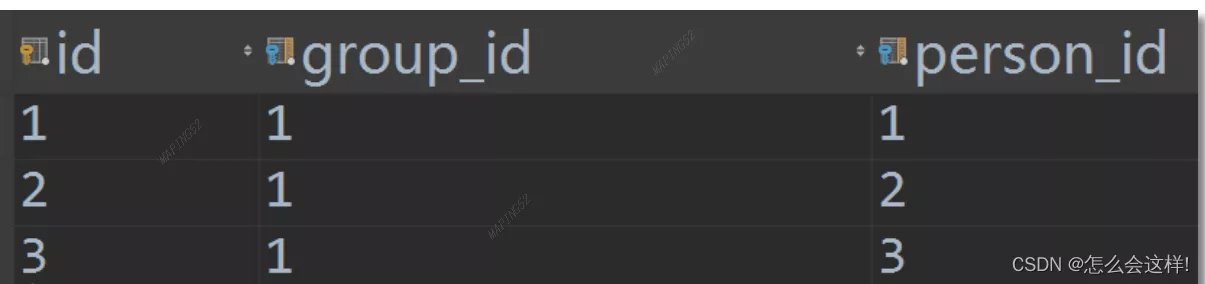 Django explained in detail how to use many to many through custom intermediate tables
Django explained in detail how to use many to many through custom intermediate tables
Catalog Many to many intermed
 [dry goods sharing] recommend 5 Python automated scripts that can get twice the result with half the effort
[dry goods sharing] recommend 5 Python automated scripts that can get twice the result with half the effort
Im sure youve heard about auto