Requirement: Describe the function to be completed by the lexical analysis system
Design and implement a lexical analyzer for high-level languages. The basic functions are as follows:
The following types of words are recognized:
Identifier (consisting of uppercase and lowercase letters, numbers, and underscores, but must start with a letter or underscore)
Keywords (① Type keywords: integer, floating point, boolean, record; ② if and else in branch structure; ③ do and while in loop structure; ④ procedure declaration and callkeywords)
Operators (① arithmetic operators; ② relational operators; ③ logical operations)
Delimiter (① Delimiter used in assignment statement, such as "="; ② Delimiter used at the end of sentence, such as ";"; ③ Delimiter used in array representation, such as "["and "]"; ④ delimiter "." for floating point number representation)
Constants (unsigned integers (including octal and hexadecimal numbers), floating point numbers (including scientific notation), string constants, etc.)
Comment (/…/ form)
Able to perform simple error handling, i.e. identify illegal characters in test cases.When the program outputs the error message, it needs to output the specific error type (ie lexical error), the location of the error (source program line number) and the relevant description text, the format is:
Lexical error at Line [line number]: [description text].
There are no specific requirements for the content of the description text (for example: illegal characters), but the error type and line number of the error must be correct, because this is the only criterion for judging whether the output error message is correct.
The input form of the system: It is required to be able to import test cases through files.Test cases should cover the types of words listed in "Experimental Content".
The output form of the system: print out the token sequence corresponding to the test case.
Requirements: Expand a description of the following content
Identifier:
[_ | [a-z]][\w*]Keywords:
r'((auto){1}|(double){1}|(int){1}|(if){1}|' \r'(#include){1}|(return){1}|(char){1}|(stdio\.h){1}|(const){1})'Operator:
r'(\+\+|\+=|\+|--|-=|-|\*=|/=|/|%=|%)'Delimiter:
r'([,:\{}:)(<>])'Constant:
r'(\d+[.]?\d+)'The rest of the word conversion diagrams are simpler
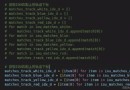
Constant: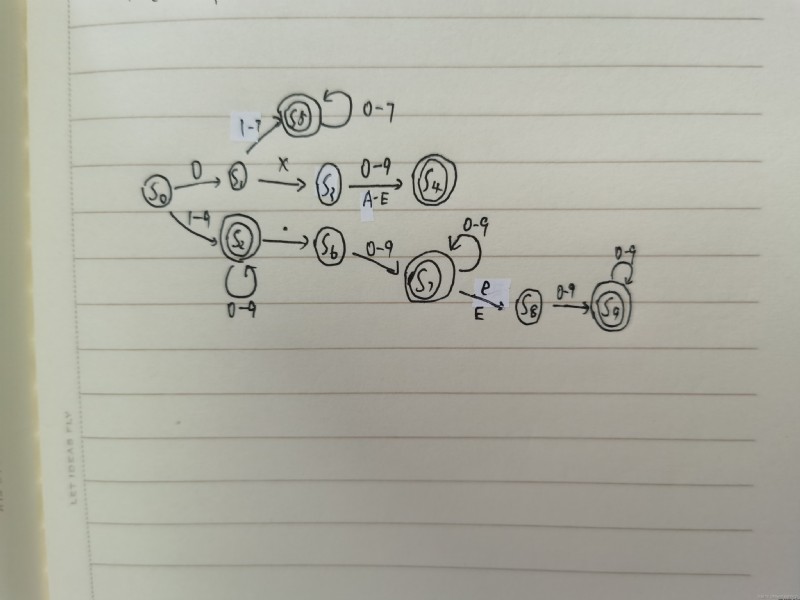
Requirements: It is divided into system outline design and system detailed design.
Function modules:
Design of core data structure
Lists using Python list[]
Main function function description
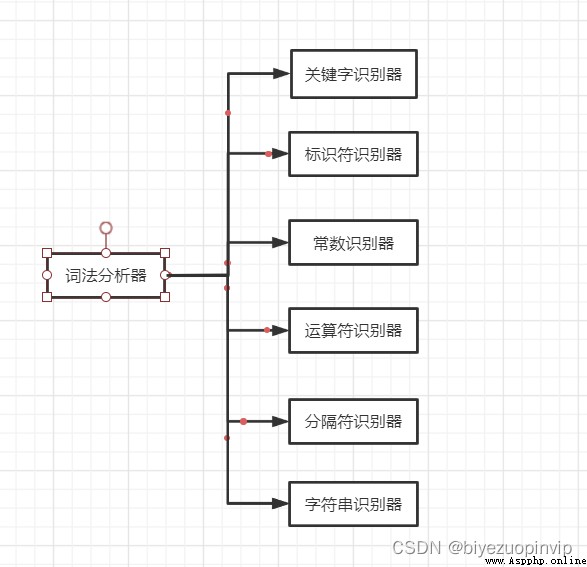
def is_blank(self, index):Determine whether it is a whitespace characterdef skip_blank(self, index):skip whitespacedef is_keyword(self, value):Determine whether it is a keyworddef main(self):The main program of lexical analysisProgram flow chart of the core part of the program
Requirements: Expand a description of the following.
The system's recognition of hexadecimal numbers is not taken into account.
The solution is to judge whether the first number of the constant is 0 when judging the constant, then judge whether the following letter is X, if so, judge whether the following string is a series of 0-9 orA-F, if it is, the word is considered constant.
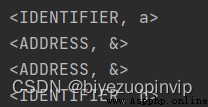
The test sample is as follows:
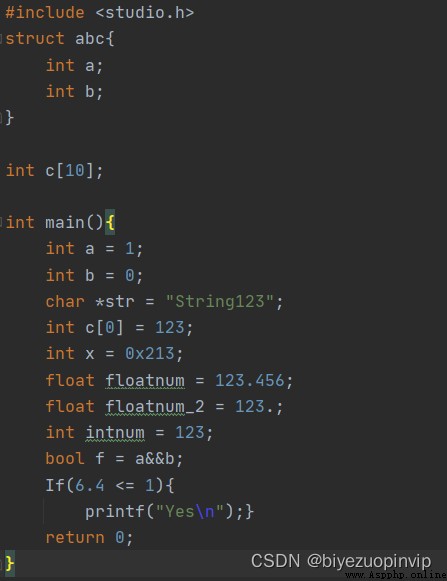
The results of the lexical analysis are generally correct, but the && is not recognized, but two &