活動地址:CSDN21天學習挑戰賽
以下是關於Python~UrllibUse of built-in libraries
🥧快,Get up with me
提示:以下是本篇文章正文內容

解釋1:通過一個程序,根據Url(https://www.baidu.com/)進行爬取網頁,獲取有用信息
解釋2:使用程序模擬浏覽器,去向服務器發送請求,獲取響應信息
1、Access in the form of a browser
2、部署多個應用分別抓取,降低單節點頻繁訪問
……

功能:
Access web scraping data data storage data processing to obtain data
缺點
功能:
Implement the crawler program to crawl the required data according to the requirements
設計思路
User‐Agent:
User Agent中文名為用戶代理,簡稱 UA,它是一個特殊字符串頭,使得服務器能夠識別客戶使用的操作系統及版本、CPU 類型、浏覽器及版本、浏覽器渲染引擎、浏覽器語言、浏覽器插件等.
代理IP:
驗證碼:
1、打碼平台
2、雲打碼平台
JavaScript 參與運算,返回的是js數據 並不是網頁的真實數據
Professional player level(代碼混淆、Dynamic encryption scheme、假數據,Obfuscate data, etc)
趕緊爬起來
Python庫的使用方法
# 引入urllib
import urllib.request
# 定義url
url = 'http://www.baidu.com/'
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(url)
# Get the corresponding page source code content 內容
# read方法 返回的是字節形式的二進制數
# 二進制轉換為字符串
# 二進制字符串 Decoding for short decode('編碼的格式') Format viewing method Right-click to view the source code content="text/html;charset=utf-8"(utf-8就是編碼格式)
content = response.read().decode('utf-8')
print(content)
The crawling is successful as shown in the figure
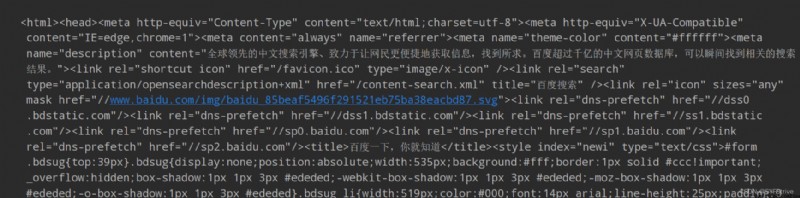
這時ctrl+a ctrl+c ctrl+v 如下所示
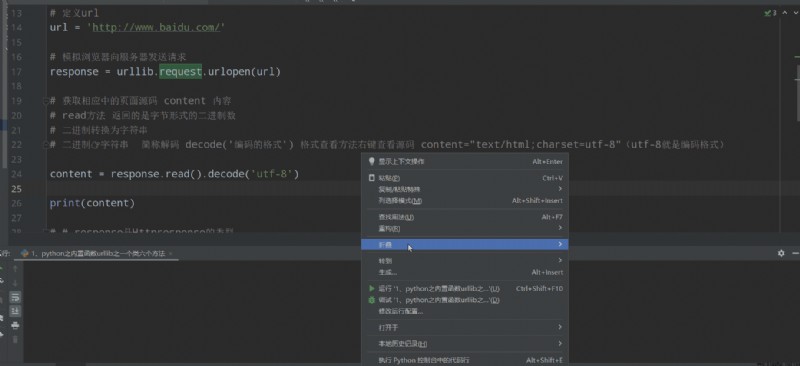

使用如下:
# 引入urllib(The built-in library does not need to be downloaded and imported directly for use)
import urllib.request
# 定義url(Crawl Baidu homepage information)
url = 'https://www.baidu.com/'
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(url)
# response是Httpresponse的類型
print(type(response))
# Read one byte at a time
content = response.read()
print(content)
# Return five bytes
content = response.read(5)
print(content)
# 讀取一行
content1 = response.readline()
print(content1)
# A read is a status message
content2 = response.readlines()
print(content2)
# 返回狀態碼 如200It proves that our logic is correct
content3 = response.getcode()
print(content3)
# 返回Url
content4 = response.geturl()
print(content4)
# 獲取狀態信息
content5 = response.getheaders()
print(content5)
import urllib.request
url = 'http://www.baidu.com/'
# 讀
# response = urllib.request.urlopen(url)
# content=response.read()
# print(content)
//urllib.request.urlretrieve(url,文件路徑 或 文件名);
# 下載網頁
urllib.request.urlretrieve(url, '2、python之urllibThe built-in function downloads the file to the local/baidu.html')
# 下載圖片
imgUrl = 'https://img1.baidu.com/it/u=1814112640,3805155152&fm=253&fmt=auto&app=120&f=JPEG?w=889&h=500'
urllib.request.urlretrieve(imgUrl, '2、python之urllibThe built-in function downloads the file to the local/img.png')
# 下載視頻
videoUrl = 'https://vd3.bdstatic.com/mda-jbrihvz6iqqgk67a/sc/mda-jbrihvz6iqqgk67a.mp4?v_from_s=hkapp-haokan-hnb&auth_key=1655298996-0-0-c4eb8c0b81c04fsrc='
urllib.request.urlretrieve(videoUrl, '2、python之urllibThe built-in function downloads the file to the local/video.mp4')
如下圖(下載保存到本地):
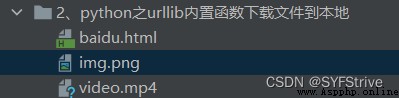

跳轉UAAnti-climbing instructions
語法:request = urllib.request.Request()
演示:
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
如圖(遇到了UA反爬):
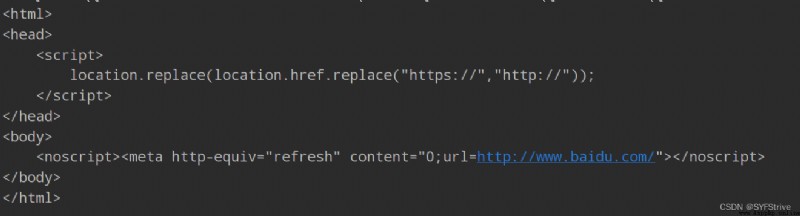
Solve to getUA:
方法一:百度跳轉
方法二:Find development tools such as 圖
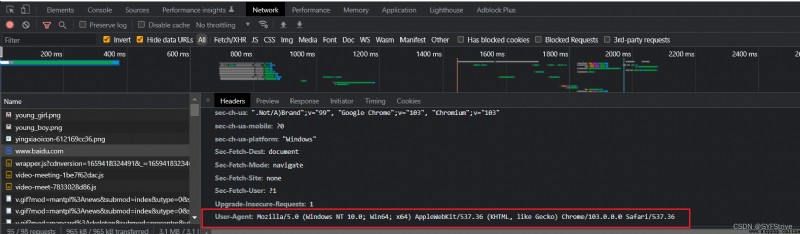
得UA 定制 再次爬取
演示:
import urllib.request
url = 'https://www.baidu.com/'
//UA寫成字典形式
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
#因為Urlopen 方法中不能儲存字典 所以headersCan't pass in
#請求對象的定制
因為順序問題 不能直接寫Url 和 headers middle againdata 所以我們需要關鍵字傳參
簡單理解:偽裝一下
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
如下圖(爬取成功):

引入 import urllib.parse
語法::urllib.parse.quote()
爬取鏈接:https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC
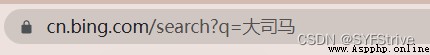
演示:
import urllib.request
import urllib.parse
url = 'https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 '
'Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
如圖所示(We have crawled successfully):
url = ‘https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC’
但是url後面的%E5%91%A8%E6%9D%B0%E4%BC%A6(Unicode編碼)Makes us feel bad(How can we put it directlyurl變成 url = 'https://cn.bing.com/search?q=大司馬’)
This is where codecs are used
Codec demo:
import urllib.request
import urllib.parse
# url = 'https://cn.bing.com/search?q=%E5%A4%A7%E5%8F%B8%E9%A9%AC'
url = 'https://www.baidu.com/s?wd='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 '
'Safari/537.36',
}
#編解碼
name = urllib.parse.quote('大司馬')
url = url + name
print(url)
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
如下圖所示(The crawling is also successful):

引入 import urllib.parse
語法:urllib.parse.urlencode(data)
演示:
import urllib.request
import urllib.parse
url = 'https://cn.bing.com/search?'
data = {
'q': '大司馬',
'sex': '男',
}
new_data = urllib.parse.urlencode(data)
print(new_data)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 '
'Safari/537.36',
}
url = url + new_data
print(url)
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
如下圖所示(爬取成功):
post VS get
import json
Ordinary climb such as:

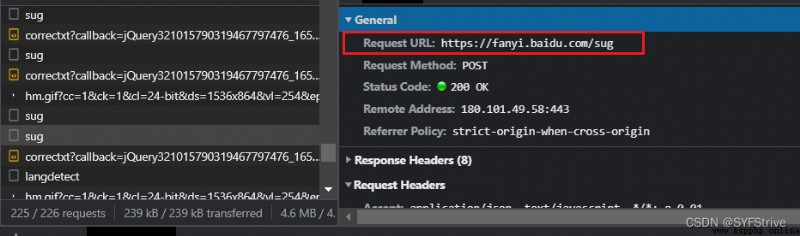
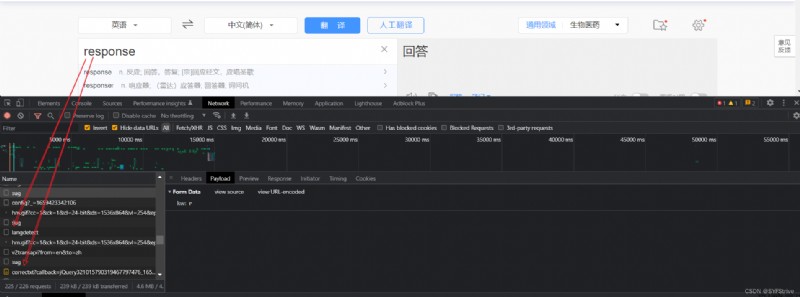
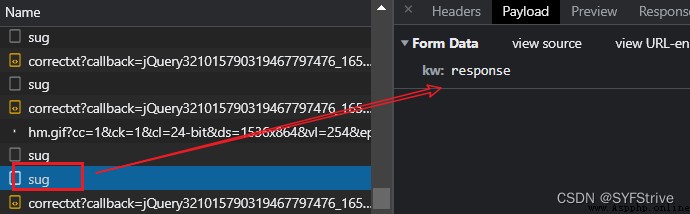
演示:
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'response'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 '
'Safari/537.36 '
}
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
print(type(content)) //<class 'str'>
import json
obj = json.loads(content)
print(obj)
print(type(obj)) //<class 'dict'>
如下圖所示(爬取成功):


Detailed climb eg:

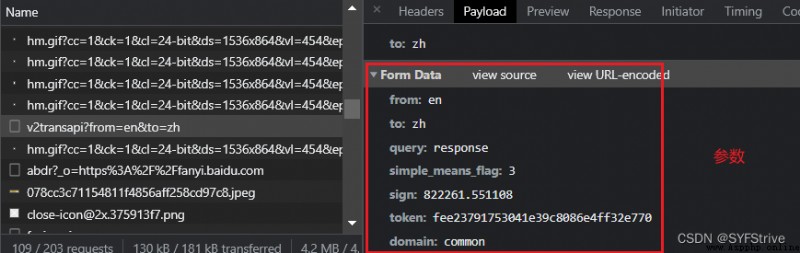
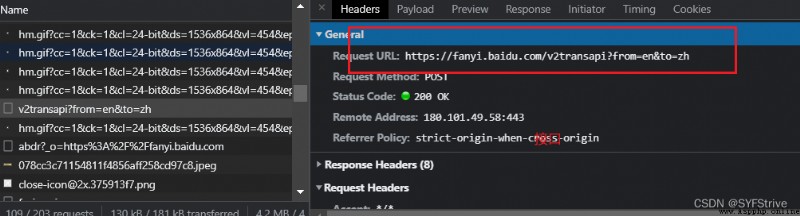
手動處理
Manual capture in developmentcookie,將其封裝在headers中
應用場景:cookieHas no active duration and is not dynamically changing
自動處理
使用session機制
使用場景:動態變化的cookie
session對象:該對象和requestsModule usage is almost identical.If generated during the requestcookie,If the request is usedsession發起的,則cookie會被自動存儲到session中

演示:
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
'Cookie': 'BAIDUID=6E16BFD21056E02BFCBB6C181371A7BA:FG=1; BIDUPSID=6E16BFD21056E02BFCBB6C181371A7BA; PSTM=1657274923; BDUSS=R2clJMdHNPaGJ3OTlnaElVTjlTemVwN0ZGSmRwWDgxY3loc1VMUW9WZll2dzVqRVFBQUFBJCQAAAAAAAAAAAEAAAAz-QpaAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANgy52LYMudiRl; BDUSS_BFESS=R2clJMdHNPaGJ3OTlnaElVTjlTemVwN0ZGSmRwWDgxY3loc1VMUW9WZll2dzVqRVFBQUFBJCQAAAAAAAAAAAEAAAAz-QpaAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANgy52LYMudiRl; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; BA_HECTOR=8h2g2k210525a421a12hoig31hehg8516; ZFY=TDJyUX98cot3iwdffZouzP1sZtAh37z5PDsJ8FRDb8g:C; BDRCVFR[C0p6oIjvx-c]=I67x6TjHwwYf0; H_PS_PSSID=36548_36752_36726_36413_36955_36948_36167_36917_36919_36966_36746_36863; BAIDUID_BFESS=810EC53BCDE6455B978B319AFAB64094:FG=1; APPGUIDE_10_0_2=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1659423222; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; ab_sr=1.0.1_MzI4MzNlOGUxOTA1NTRiZjE2NjM2ZjEzZDE3NTg3MTExMWVmYWNlNzhkYTM0NDczOGJmNTc4NjYwYzkwYjY5MmU2NWNmNmMxOTMxZDc1YmRlOTVkNjlhOTZjNDliNGM4ZWVkNWYxOWZlNGJlZjNiYWEwOGU0NWMzMjdlNWNhN2ExMTI0OTE2ZTI3OTcxNjYyNTgxMzA4MzQ1ZTc5NTdkOA==; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1659425248',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 '
'Safari/537.36',
}
data = {
'from': 'en',
'to': 'zh',
'query': 'response',
'simple_means_flag': '3',
'sign': '822261.551108',
'(It's been monitored here)': 'fee23791753041e39c8086e4ff32e770',
'domain': 'common'
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
print(type(content))
import json
obj = json.loads(content) //<class 'str'>
print(obj)
print(type(obj)) //<class 'dict'>
如下圖所示(爬取成功):


本文章到這裡就結束了,感謝大家的支持,希望這篇文章能幫到大家

下篇文章再見ヾ( ̄▽ ̄)ByeBye