該問題來源於 Kaggle 平台上的一個經典案例 Digit Recognizer [1],目的是將數據集中的手寫數字圖片識別為數字。
在本次研究中,我簡化了前人已有的模型,簡要探究了遷移學習的基礎方法,並將經典的預訓練分類網絡 VGG16 應用在數字識別中,對兩者進行對比,以期達到相近的效果。
該問題相當經典,也是入門神經網絡的推薦選題,以及不少神經網絡方面教程進行講解的常用例子。但是經過了解,我認為推薦原因主要在於訓練目標非常直觀,而且數據集較小,使用非專業的設備也能進行模型訓練,但是其背後的神經網絡設計經常被一筆帶過,但實際上仍較復雜。通常,該問題屬於深度學習范疇,使用卷積神經網絡(CNN)來解決。
傳統方案的問題在於模型結構、參數需要完全手工設計。深度學習的核心是特征學習,旨在通過分層網絡獲取分層次的特征信息,因而需要理解常見結構在具體任務中的作用,如卷積、池化、全連接等,進行對比實驗體會不同結構、參數對神經網絡性能的影響,這個過程需要大量的先驗經驗,也是不同神經網絡性能瓶頸的主要所在。除此之外,在訓練時,所有參數都需要從完全未知的狀態開始訓練,訓練時間長,往往需要多個 epochs 才能達到預期中較高的准確率。
基於此,我簡要探究了遷移學習的方法。遷移學習是將已訓練好的模型參數遷移到新的模型來幫助新模型訓練,考慮到大部分數據或任務是存在相關性的,所以通過遷移學習可以將已經學到的模型參數,通過某種方式來分享給新模型從而加快並優化模型的學習效率,而不用像通常的傳統網絡設計流程那樣從零學習。
因而我認為,研究該問題的意義在於,當需要應用神經網絡處理某些問題時,例如將數字識別從傳統的特征提取轉變為分類問題,是否可以利用一種通用的預訓練分類模型來簡化神經網絡設計的工作量,加快研究進度的同時能取得可接受的效果。
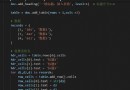
我以 Kaggle 平台上最熱門的開源解決方案為基礎,其基於 Tensorflow 使用 Keras 搭建神經網絡[2],模型結構如下
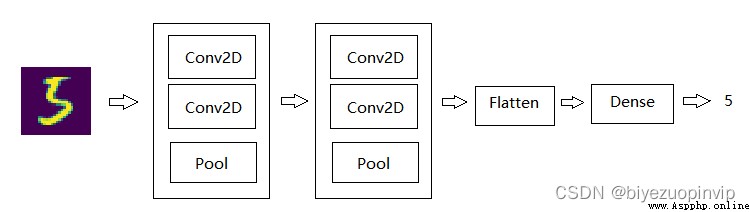
# In -> [[Conv2D->relu]*2 -> MaxPool2D -> Dropout]*2 -> Flatten -> Dense -> Dropout -> Out
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu', input_shape = (28, 28, 1)))
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.5))
常見的預訓練分類網絡有牛津的 VGG 模型、谷歌的 Inception 模型、微軟的 ResNet 模型等,他們都是預訓練的用於分類和檢測的卷積神經網絡(CNN)。
本次選用的是 VGG16 模型[4],是一個在 ImageNet 數據集上預訓練的模型,分類性能優秀,對其他數據集適應能力優秀。
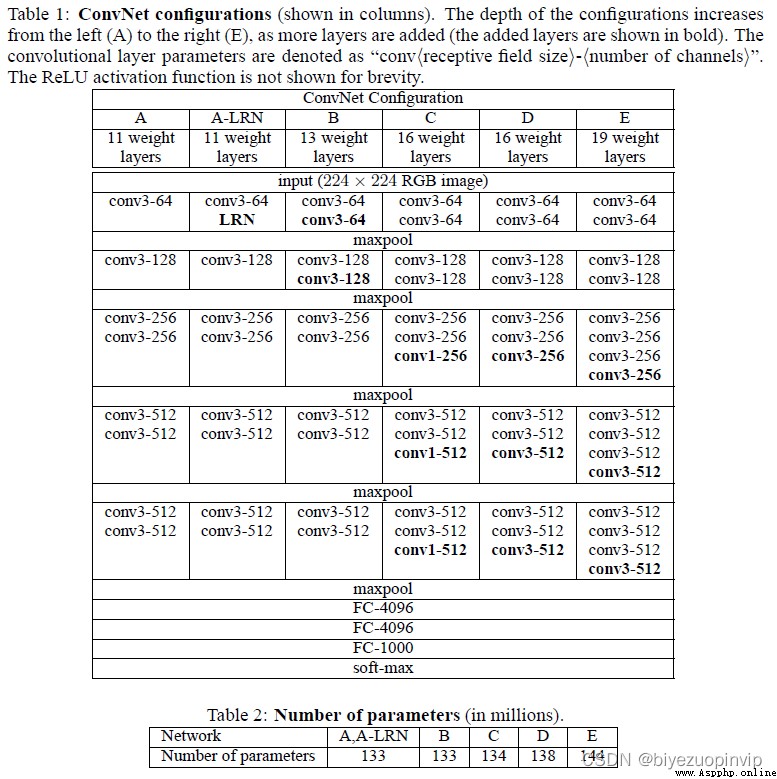
上圖為原論文中對 VGG16 模型內部結構的介紹,可以看出相當復雜,但在本次的研究中,並沒有准備對該結構進行任何調整,而選擇凍結其中所有的預訓練參數,僅對這之後的幾個必要層進行訓練。
前人分享的代碼使用的是 Kaggle 提供的 CSV 格式的數據集,將圖片以像素為列,存儲像素的灰度值。為了簡化代碼和方便驗證兩模型的准確率,統一使用 Keras 包中提供的數據集,訓練集和測試集的獲取方法如下
from keras.datasets import mnist
(X_train_data, Y_train_data), (X_test_data, Y_test_data) = mnist.load_data()
除此之外,原作者還設計了數據增強部分,在原數據集的基礎上隨機旋轉、平移、縮放、產生噪音,從而更好地聚焦於數字特征的提取,而不是數據集本身。但受限於機器性能,為了縮減模型的訓練時間,我刪減了該部分功能。
通過如上修改,將該模型再與後續的基於 VGG16 的遷移學習模型進行比較,分析遷移學習得到的模型准確率水平。
我使用了 keras.applications.vgg16 中的 VGG16,在線獲取已有的 VGG16 模型及參數,獲取後凍結 VGG16 中的所有參數進行訓練。
在這之後添加一層 relu 全連接以及用於多分類的 softmax 全連接,並插入卷積層到全連接層的過渡 flatten 層等,相較前人設計的 CNN 而言設計十分簡要。
# In -> VGG16 -> Flatten -> Dense -> Dropout -> Dense -> Out
vgg16_model = VGG16(weights='imagenet', include_top=False, input_shape=(48, 48, 3))
for layer in vgg16_model.layers:
layer.trainable = False # freeze VGG16卷積層的參數
model = Sequential()
model.add(vgg16_model)
model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(10, activation='softmax'))
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.datasets import mnist
epochs = 1
test_total = 10000
df_CNN = pd.read_csv("./epochs%d/CNN.csv" % epochs)
df_VGG16 = pd.read_csv("./epochs%d/VGG16.csv" % epochs)
(X_train_data, Y_train_data), (X_test_data, Y_test_data) = mnist.load_data()
X_test_data = X_test_data.astype('float32') / 255.0
X_test = np.reshape(X_test_data, (-1, 28, 28, 1))
Y_test = Y_test_data
err_CNN = 0
err_VGG16 = 0
for i in range(test_total):
res_CNN = df_CNN["Label"][i]
res_VGG16 = df_VGG16["Label"][i]
if res_CNN != res_VGG16:
res_correct = Y_test[i]
if res_CNN != res_correct:
err_CNN = err_CNN + 1
if res_VGG16 != res_correct:
err_VGG16 = err_VGG16 + 1
plt.imshow(X_test[i][:, :, 0])
plt.savefig("./epochs%d/%d_%d_%d_%d.jpg" % (epochs, i, Y_test[i], res_CNN, res_VGG16))
print(err_CNN, err_VGG16)
訓練 epochs=1 後,通過以上代碼,輸出兩模型對於分類結果預測不一致的測試樣例,命名為”樣例序號_參考結果_前人 CNN 預測結果_VGG16 預測結果.jpg”,並且輸出 10000 個測試樣例中的錯誤分類數,輸出及部分樣例如下

觀察如上結果,在 10000 張測試樣例中,前人 CNN 准確率為 98.95%,應用了 VGG16 進行遷移學習的模型准確率為 95.65%,雖然結果不及 CNN,但是我認為這已經超過了我預期的結果。
由於 VGG16 並不是針對該問題而設計的,而是一個基於 ImageNET 上 1400 萬張 1000 類圖片而預訓練的模型,在我的工作中只添加了必要的全連接層等,就實現了 95% 以上准確率的分類效果,可以說是較為滿意的。
通過觀察如上錯誤樣例,能夠發現 VGG16 將一些形狀十分類似於另一數字的圖片分類成了另一數字,例如右半部分較短、下半部分較長的”4”分類成了”9”,將下半部分極窄的”8”分類成了”9”,能夠感受到 VGG16 更多的是在將形狀類似的圖片分為一類,而並沒有像 CNN 那樣通過(5,5)、(3,3)的 kernel 聚焦於數字的特征,這在對於分類一些書寫並不規范且特殊的數字而言是致命的,但對於正常數字識別而言是能夠接受的,要解決該問題,可能需要調整 VGG16 中的內部結構。
將數據集中的像素信息轉化為圖片,由於實際訓練中不需要圖片信息,在此我僅將測試集的一部分樣例轉化為圖片進行演示,代碼如下
for i in range(100):
plt.imshow(X_test[i][:, :, 0])
plt.savefig("./test/%d.jpg" % i)