要求:闡述詞法分析系統所要完成的功能
設計實現類高級語言的詞法分析器,基本功能如下:
能識別以下幾類單詞:
標識符(由大小寫字母、數字以及下劃線組成,但必須以字母或者下劃線開頭)
關鍵字(① 類型關鍵字:整型、浮點型、布爾型、記錄型;② 分支結構中的 if 和 else;③ 循環結構中的 do 和 while;④ 過程聲明和調用中的關鍵字)
運算符(① 算術運算符;② 關系運算符;③ 邏輯運算)
界符(① 用於賦值語句的界符,如“=”;② 用於句子結尾的界符,如“;”;③ 用於數組表示的界符,如“[”和“]”;④ 用於浮點數表示的界符“.”)
常數(無符號整數(含八進制和十六進制數)、浮點數(含科學計數法)、字符串常數等)
注釋(/……/形式)
能夠進行簡單的錯誤處理,即識別出測試用例中的非法字符。程序在輸出錯誤提示信息時,需要輸出具體的錯誤類型(即詞法錯誤)、出錯的位置(源程序行號)以及相關的說明文字,其格式為:
Lexical error at Line [行號]: [說明文字].
說明文字的內容沒有具體要求(例如:非法字符),但是錯誤類型和出錯的行號一定要正確,因為這是判斷輸出錯誤提示信息是否正確的唯一標准。
系統的輸入形式:要求能夠通過文件導入測試用例。測試用例要涵蓋“實驗內容”中列出的各類單詞。
系統的輸出形式:打印輸出測試用例對應的 token 序列 。
要求:對如下內容展開描述
標識符:
[_ | [a-z]][\w*]
關鍵字:
r'((auto){1}|(double){1}|(int){1}|(if){1}|' \
r'(#include){1}|(return){1}|(char){1}|(stdio\.h){1}|(const){1})'
運算符:
r'(\+\+|\+=|\+|--|-=|-|\*=|/=|/|%=|%)'
界符:
r'([,:\{}:)(<>])'
常數:
r'(\d+[.]?\d+)'
其余的單詞轉換圖較為簡單
常數: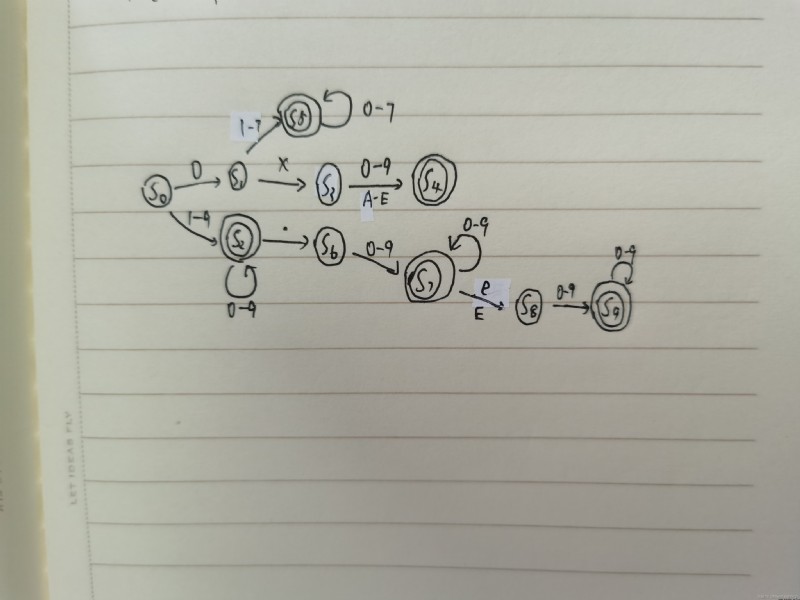
要求:分為系統概要設計和系統詳細設計。
功能模塊:
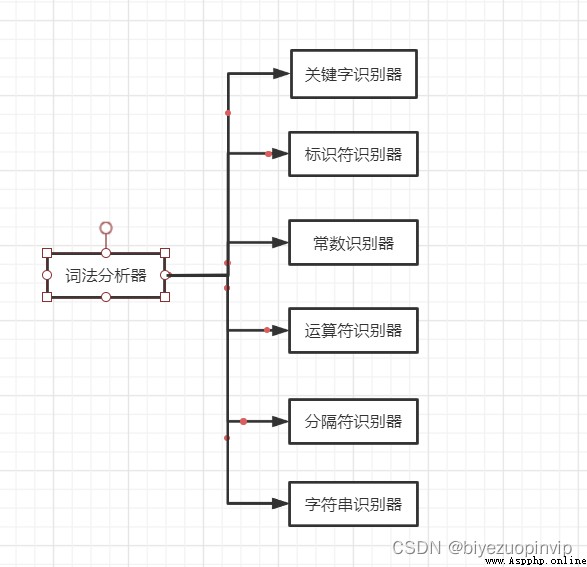
核心數據結構的設計
使用 Python 的列表 list[]
主要功能函數說明
def is_blank(self, index):判斷是否是空白字符
def skip_blank(self, index):跳過空白字符
def is_keyword(self, value):判斷是否是關鍵字
def main(self):詞法分析的主程序
程序核心部分的程序流程圖
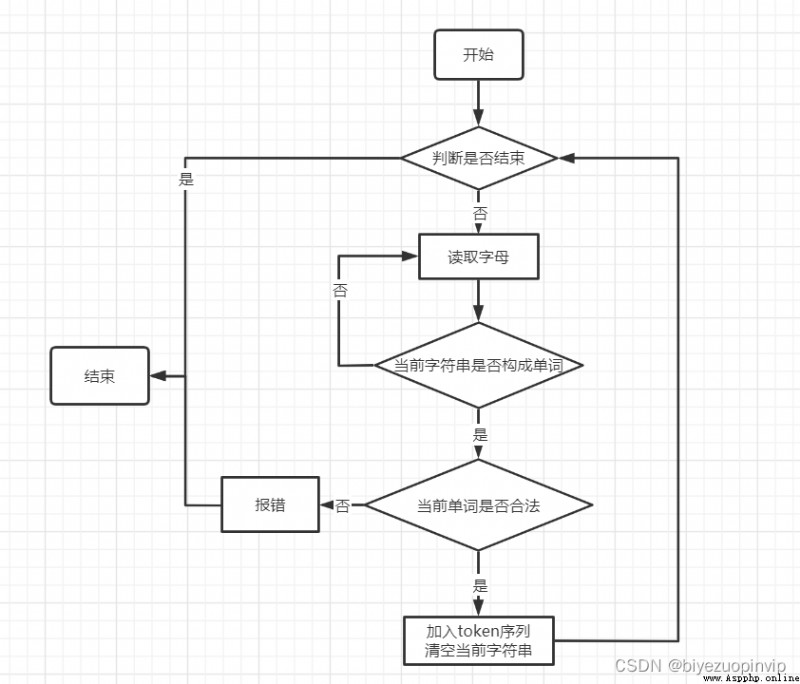
要求:對如下內容展開描述。
系統對十六進制的數的識別沒有考慮進去。
解決方法為在判斷常數時如果判斷該常數第一個數為 0 時,再判斷其後的一個字母是否為 X,如果是,再判斷後面的字符串是否為一連串的 0-9 或 A-F 組成,如果是,則認為該單詞是常數。
測試樣例如下:
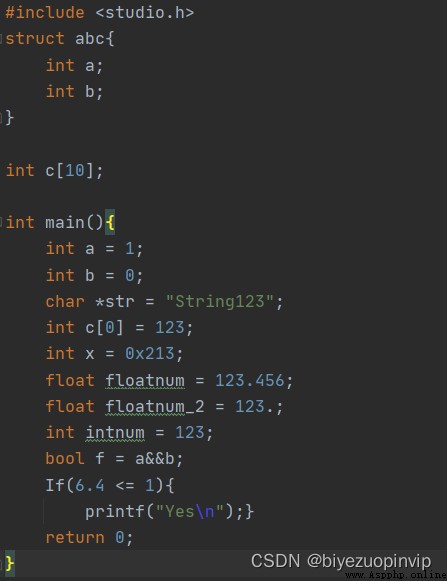
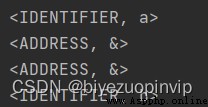
詞法分析的結果大體上都是正確的,但對於&&並沒有識別出來,而是識別成了兩個&