在進行數據科學時,可能會浪費大量時間編碼並等待計算機運行某些東西。所以我選擇了一些 Python 庫,可以幫助你節省寶貴的時間。
Optuna 是一個開源的超參數優化框架,它可以自動為機器學習模型找到最佳超參數。
最基本的(也可能是眾所周知的)替代方案是 sklearn 的 GridSearchCV,它將嘗試多種超參數組合並根據交叉驗證選擇最佳組合。
GridSearchCV 將在先前定義的空間內嘗試組合。例如,對於隨機森林分類器,可能想要測試幾個不同的樹的最大深度。GridSearchCV 會提供每個超參數的所有可能值,並查看所有組合。
Optuna會在定義的搜索空間中使用自己嘗試的歷史來確定接下來要嘗試的值。它使用的方法是一種稱為“Tree-structured Parzen Estimator”的貝葉斯優化算法。
這種不同的方法意味著它不是無意義的地嘗試每一個值,而是在嘗試之前尋找最佳候選者,這樣可以節省時間,否則這些時間會花在嘗試沒有希望的替代品上(並且可能也會產生更好的結果)。
最後,它與框架無關,這意味著您可以將它與 TensorFlow、Keras、PyTorch 或任何其他 ML 框架一起使用。
ITMO_FS 是一個特征選擇庫,它可以為 ML 模型進行特征選擇。擁有的觀察值越少,就越需要謹慎處理過多的特征,以避免過度擬合。所謂“謹慎”意思是應該規范你的模型。通常一個更簡單的模型(更少的特征),更容易理解和解釋。
ITMO_FS 算法分為 6 個不同的類別:監督過濾器、無監督過濾器、包裝器、混合、嵌入式、集成(盡管它主要關注監督過濾器)。
“監督過濾器”算法的一個簡單示例是根據特征與目標變量的相關性來選擇特征。“backward selection”,可以嘗試逐個刪除特征,並確認這些特征如何影響模型預測能力。
這是一個關於如何使用 ITMO_FS 及其對模型分數的影響的普通示例:
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334ITMO_FS是一個相對較新的庫,因此它仍然有點不穩定,但我仍然建議嘗試一下。
到目前為止,我們已經看到了用於特征選擇和超參數調整的庫,但為什麼不能同時使用兩者呢?這就是 shap-hypetune 的作用。
讓我們從了解什麼是“SHAP”開始:
“SHAP(SHapley Additive exPlanations)是一種博弈論方法,用於解釋任何機器學習模型的輸出。”
SHAP 是用於解釋模型的最廣泛使用的庫之一,它通過產生每個特征對模型最終預測的重要性來工作。
另一方面,shap-hypertune 受益於這種方法來選擇最佳特征,同時也選擇最佳超參數。你為什麼要合並在一起?因為沒有考慮它們之間的相互作用,獨立地選擇特征和調整超參數可能會導致次優選擇。同時執行這兩項不僅考慮到了這一點,而且還節省了一些編碼時間(盡管由於搜索空間的增加可能會增加運行時間)。
搜索可以通過 3 種方式完成:網格搜索、隨機搜索或貝葉斯搜索(另外,它可以並行化)。
但是,shap-hypertune 僅適用於梯度提升模型!
PyCaret 是一個開源、低代碼的機器學習庫,可自動執行機器學習工作流。它涵蓋探索性數據分析、預處理、建模(包括可解釋性)和 MLOps。
讓我們看看他們網站上的一些實際示例,看看它是如何工作的:
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
best = compare_models()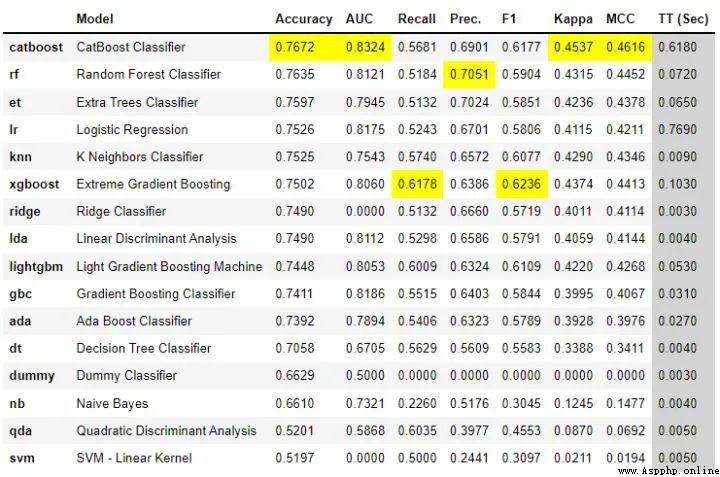
只需幾行代碼,就可以嘗試多個模型,並在整個主要分類指標中對它們進行了比較。
它還允許創建一個基本的應用程序來與模型進行交互:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_app(lr)最後,可以輕松地為模型創建 API 和 Docker 文件:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api')沒有比這更容易的了,對吧?
PyCaret是一個非常完整的庫,在這裡很難涵蓋所有內容,建議你現在下載並開始使用它來了解一些 其在實踐中的能力。
FloWeaver 可以從流數據集中生成桑基圖。如果你不知道什麼是桑基圖,這裡有一個例子:
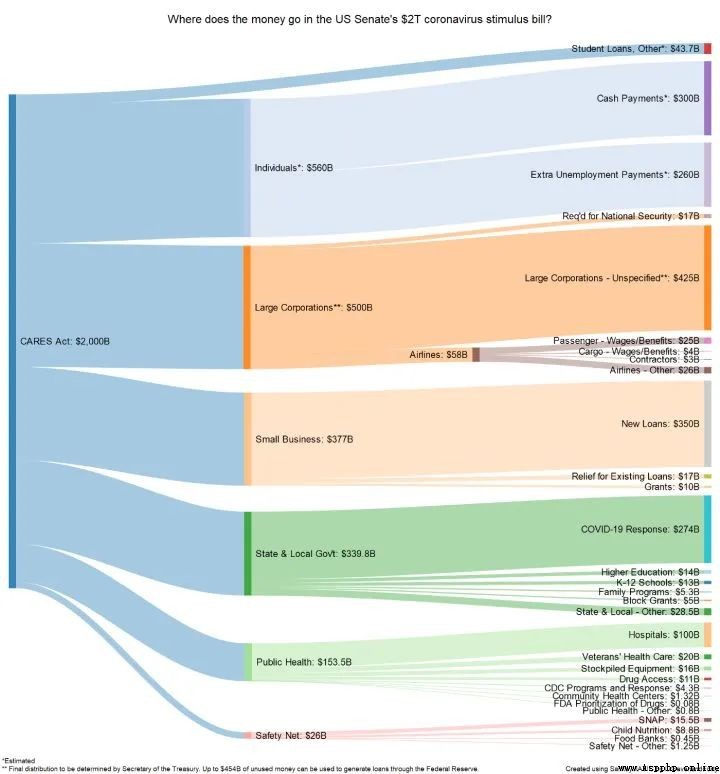
在顯示轉化漏斗、營銷旅程或預算分配的數據時,它們非常有用(上例)。入口數據應采用以下格式:“源 x 目標 x 值”,只需一行代碼即可創建此類圖(非常具體,但也非常直觀)。
如果你閱讀過敏捷數據科學,就會知道擁有一個讓最終用戶從項目開始就與數據進行交互的前端界面是多麼有幫助。一般情況下在Python中最常用是 Flask,但它對初學者不太友好,它需要多個文件和一些 html、css 等知識。
Gradio 允許您通過設置輸入類型(文本、復選框等)、功能和輸出來創建簡單的界面。盡管它似乎不如 Flask 可定制,但它更直觀。
由於 Gradio 現在已經加入 Huggingface,可以在互聯網上永久托管 Gradio 模型,而且是免費的!
理解 Terality 的最佳方式是將其視為“Pandas ,但速度更快”。這並不意味著完全替換 pandas 並且必須重新學習如何使用df:Terality 與 Pandas 具有完全相同的語法。實際上,他們甚至建議“import Terality as pd”,並繼續按照以前的習慣的方式進行編碼。
它快多少?他們的網站有時會說它快 30 倍,有時快 10 到 100 倍。
另一個重要是 Terality 允許並行化並且它不在本地運行,這意味著您的 8GB RAM 筆記本電腦將不會再出現 MemoryErrors!
但它在背後是如何運作的呢?理解 Terality 的一個很好的比喻是可以認為他們在本地使用的 Pandas 兼容的語法並編譯成 Spark 的計算操作,使用Spark進行後端的計算。所以計算不是在本地運行,而是將計算任務提交到了他們的平台上。
那有什麼問題呢?每月最多只能免費處理 1TB 的數據。如果需要更多則必須每月至少支付 49 美元。1TB/月對於測試工具和個人項目可能綽綽有余,但如果你需要它來實際公司使用,肯定是要付費的。
如果你是Pytorch的使用者,可以試試這個庫。
torchhandle是一個PyTorch的輔助框架。它將PyTorch繁瑣和重復的訓練代碼抽象出來,使得數據科學家們能夠將精力放在數據處理、創建模型和參數優化,而不是編寫重復的訓練循環代碼。使用torchhandle,可以讓你的代碼更加簡潔易讀,讓你的開發任務更加高效。
torchhandle將Pytorch的訓練和推理過程進行了抽象整理和提取,只要使用幾行代碼就可以實現PyTorch的深度學習管道。並可以生成完整訓練報告,還可以集成tensorboard進行可視化。
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseConpython
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseConpython(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
conpython_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)定義一個模型,設置數據集,配置優化器、損失函數就可以自動訓練了,是不是和TF差不多了。