大家好,又見面了,我是你們的朋友全棧君。
我們平時使用浏覽器來訪問網頁,實質上來看,就是通過一個客戶端經過網絡連接訪問了服務器端,訪問前,我們的頁面沒有任何內容,那麼這些內容必然都是從服務器端傳輸過來的。爬蟲的工作就是利用編程的方式自動化地從服務器端獲取並分析數據,得到我們需要爬取的內容。
因此想要利用爬蟲獲取內容,首先需要我們分析目標網站頁面,了解其數據排列方式,知曉其數據傳輸過程,從而能夠制訂正確有效的爬取途徑。
以CSDN中我本人之前的一篇文章為例 https://blog.csdn.net/qq_26292987/article/details/107608315
如果我們希望獲取這個頁面上的文章內容而不希望自己動手去復制粘貼,爬蟲是一個非常有效的工具,而分析這個頁面有幾個方向:
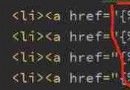
(一)分析頁面源代碼: 在頁面上單擊右鍵,可以看到選項“查看頁面源代碼”(這裡我使用的是Microsoft Edge浏覽器,不同浏覽器可能有所不同),彈出的新網頁內容如圖:
如何能夠在繁雜的代碼信息中快速找到我們需要的內容呢? 【1】查找大法好 “Ctrl+F”,搜索要查找的關鍵詞,看是否能得到結果,這裡目的是查找文章內容,直接搜索“BeautifulSoap用法”即可得到如下界面
那麼為什麼選擇搜索“BeautifulSoap用法”而不是題目或者其他呢?簡單查看源代碼即可發現,題目在源代碼中多次出現,不能很好的確定文章位置,第一段同理(第一段主要是本人編輯的問題) 【2】進階方法 對於這個方法,首先需要對網頁源代碼的組織方式有一定的了解,也就是需要對HTML相關知識有億點點了解:https://www.runoob.com/html/html-tutorial.html 經過簡單的學習(After ten thousands years) 我們知道了: HTML是一種標記語言,有嚴謹的標簽設置來確定其中每一部分的功能,而更關鍵的是:
HTML 標簽是由尖括號包圍的關鍵詞,比如
<html>HTML 標簽通常是成對出現的,比如<b>和</b>標簽對中的第一個標簽是開始標簽,第二個標簽是結束標簽 開始和結束標簽也被稱為開放標簽和閉合標簽 聲明為 HTML5 文檔<html>元素是 HTML 頁面的根元素<head>元素包含了文檔的元(meta)數據,如 <meta` charset=“utf-8”> 定義網頁編碼格式為 utf-8。<title>元素描述了文檔的標題<body>> 元素包含了可見的頁面內容<h1>元素定義一個大標題<p>元素定義一個段落<a>元素定義一個鏈接<img>元素定義一個圖像<div><span>元素定義一個區塊<script>定義一個腳本(運行的函數)
有了上面這些知識,那我們需要的東西一定是在body裡去找的,具體在哪裡找呢?(實話說還是“Ctrl+F”更方便,這些知識更多的是為了下一步從頁面中獲取內容所需要的)這裡我個人推薦sublime作為暫時的閱覽器,配置好該軟件的“HTML/CSS/JS Prettify”模塊之後,只需要輕輕一點,那些沒有縮進和對齊的代碼就變成了下面這樣:
隨後就可以比較方便的通過折疊查找等方式獲得我們需要的內容了
(二)分析頁面元素 在頁面上按“F12”,神奇的事情出現了,頁面的右側(有的浏覽器是下方)發生了有趣的變化:
其上方菜單欄有“元素、控制台、源代碼、網絡、性能、內存”等幾個選項,現在我們只需要注意“元素、網絡”兩個部分就夠了! 元素區系統的展示了頁面上全部的元素和內容及其排布方式,修改其中的內容,頁面上的內容也會發生相應的改變(別擔心,服務器端存儲的內容沒有改變),將鼠標移到相應的位置,可以看到左側相應的內容出現了被選中的效果,現在再去尋找元素所在的位置就輕松多了吧。
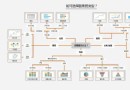
(三)分析網絡傳輸 如果你對前面的內容還有印象,那你應該還記得,頁面上的所有內容都是服務器端傳輸到我們的浏覽器上的,也就是說,頁面上的每一個元素都是服務器端傳輸的結果,在網絡中可以看到這個過程:
看到這麼一堆亂七八糟的東西,我的內心是崩潰的(這都啥玩意兒啊) 沒事兒,無所不能的網絡告訴我們,遇到事情不要慌,先拿出手機拍一張(笑) 首先我們可以看類型,從圖片中可以清晰的看到其傳輸的很大一部分內容都是png、gif之類的圖片,那麼這些圖片是什麼呢?一般我們可以點擊左側的名稱,在彈出的預覽頁面中看到他們主要是一些頁面上的圖標、廣告等需要圖片的元素;其次是script,這個我們已經了解了,它是一種網頁上使用的腳本函數,那這些“.js”文件大概率就是網頁上運行的腳本函數的內容;緊接著是text,從類型上可以看出來,這是一種文本文件,與其相似的還有類型為document的文件流,這些文件中的內容很多是和我們需要的內容直接相關的。 其次我們可以分析文件名稱,確實,文件名稱也是亂糟糟的,但是,如果這些文件名稱真的是亂糟糟的沒有規律,那網站的運維人員又該如何在一團亂麻中快准狠找到問題解決問題呢?所以堅信一點,只要是人設計的,就一定是有規律可循的,就一定是有漏洞的,然後通過多個網頁的對比,總能夠找到我們需要的東西。 再次,我們可以去看大小。很多時候,要分析的頁面所包含的最重要的信息其文件傳輸流一定不會很小,因此一些只有幾個B的信息流在分析的時候可以忽略掉,按照信息流的大小來判斷其重要與否是一個很方便且有必要的方式。
那麼,對於初級的爬蟲學習者來說,用好這三個方法,很多網頁就可以去嘗試著分析並尋找其有價值的信息藏在何處從而將其爬取到自己的電腦上了。然而,如果說爬蟲是網絡世界爬取信息最鋒利的矛,那麼為了保護自己的網站信息不被隨意爬取(畢竟信息就是金錢),同時也為了讓網站的設計和使用更加便利,網站使用了很多方式來優化自己,有意無意間給我們的爬取帶來了很多困難,常見的如異步信息流、動態頁面加載、登陸驗證、ip訪問次數限制等等,其中的一些可以通過分析網頁解決,大部分都需要我們針對不同的網站對自己的程序做不同的優化處理才能夠解決。那麼,接下來我們先做一個小項目,初步嘗試一下爬蟲獲取數據的快樂吧!
發布者:全棧程序員棧長,轉載請注明出處:https://javaforall.cn/125155.html原文鏈接:https://javaforall.cn